
Models are rarely executable and/or lack the required level of expressiveness or performance to be exploited directly in production. The underlying semantics of the code to be executed is generally encoded in code generators that will produce the code from the initial models.
This approach, model first, then generation, raises two major issues.
- It creates an important gap between the conceptual level (the model) and the source code, where semantics may be totally hidden or implicit.
- The synchronization of the pair models-code in a co-evolution scenario where model and source code may evolve independently (and often by different actors, e.g., architect and developer) becomes hard to maintain.
Round-trip mechanisms are commonly used to overcome those difficulties, but they are difficult to use and maintain. Indeed, the model/code co-evolution problem remains an open subject in the software engineering research community and, consequently, software development projects often abandon the idea of maintaining the synchronization between model and source code during development process.
PAMELA proposes a shift in the modeling paradigm, in which models and code are developed together and at the same time in what we call a continuous modeling process. The PAMELA framework supports this paradigm shift by providing the means to:
- Weave model-based annotations with Java source code and
- Interpret model annotations at run-time.
This post, by Sylvain Guerin and Salvador Martínez, explains the main concepts behind PAMELA.
PAMELA’s approach and development process
PAMELA is an annotation-based Java modeling framework providing a smooth integration between model and code, without code generation nor externalized model serialization. Instead of generating the code, the API (mostly Java interfaces with abstract method declarations) is locally executed (interpreted). The idea is to avoid separation between modeling and code to facilitate consistency management and to avoid round-trip issues.
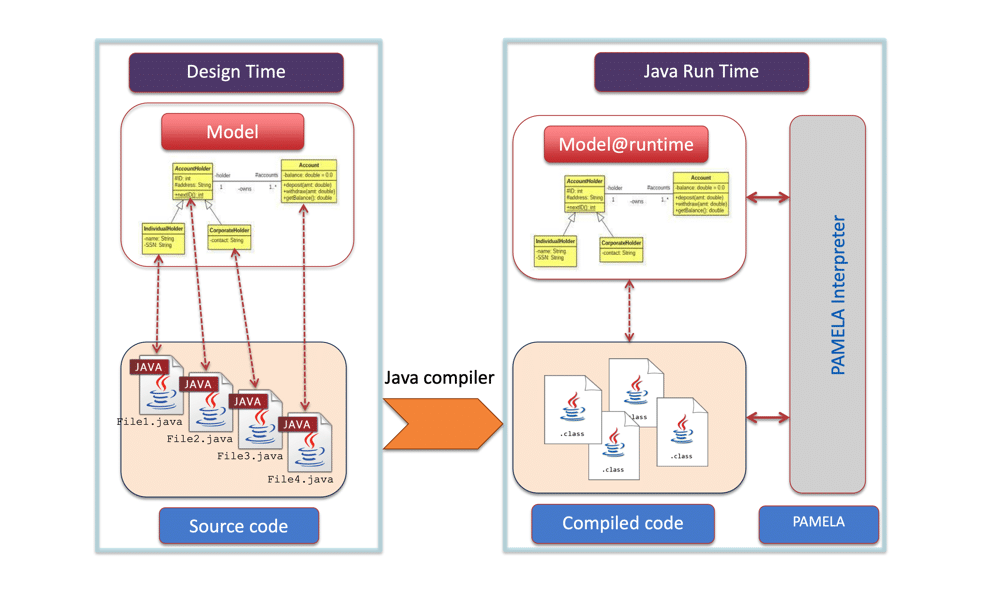
The figure at the top of the post summarizes the PAMELA architecture. The left side shows the structure of the application source code where java files contain the code and annotations that link part of the code to PAMELA model entities such as class, attribute, method, etc. The right side shows that at runtime the PAMELA interpreter maintains the relationships between the application binary, result of the java compilation, and the internal representation of PAMELA models. The preservation of the structure and of the whole information allow a very good and high level of control over the execution.
Coupling model and code into the same artifact opens new ways of programming. The classical (metadata enabled) programming process relies on programmers that produce code reusing pre-existing modeling concepts. These concepts are implemented by modelers that provide the right annotations the programmers use. This is, for instance, the process followed by Jakarta EE (JEE) developers reusing JEE specific annotations. The evolution rhythm between models and code is low. This programming way is still possible with PAMELA, but we allow the ability to reach a higher evolution rhythm where the programmer also becomes the modeler. In fact, when the programmer identifies a pattern, an abstraction, a generalization, s/he can use PAMELA to develop and capitalize on this abstraction by extending PAMELA’s metamodel.
The developed metamodels are implemented by annotations that rely on Java/JVM entities and mechanisms. They include consistency checking, which constrains their use and help the programmer to avoid inconsistencies or errors. We have first experimented with their use with setters/getters to define Plain Old Java Objects (POJO), with traits to implement multiple inheritance or with roles and rules to set security rules on classes.
Our experience shows that introducing and reusing new concepts (1) reduces the size of the code (2) reduces the risk of errors and (3) improves the code structure. The cycle of development between the model and the code can then be drastically reduced, leading to what we call continuous modeling. The code size is reduced because abstractions factorize recognized concepts so that the code using such concepts is replaced by the use of the abstraction at the right place. This also reduces the risk of errors since the code is now managed by the PAMELA framework with all the required checks. Finally, the code structure is improved since it matches the way the programmer conceptualizes (models) her/his code.
Here are various conceivable scenarios for PAMELA use:
- Programming use: programmers reuse existing annotations and write model and code at the same time (the modelers and programmers share the same artifacts: the Java code). This scenario includes the case where the model (made by the modelers) is pre-existing.
- Reengineering: programmers start from an existing code base (legacy) and refactor it while replacing this code by abstract method declarations in Java interface, reducing risks of errors.
- Aspect-oriented programming: programmers may use or redefine “patterns” (e.g., Security Patterns) which offers code weaving at runtime, and runtime monitoring.
- Advanced programmers use: programmers may extend PAMELA with their own annotations, implementations or patterns. In this presentation, we focus on the programming use of PAMELA, when programmers reuse existing annotations. The full power of PAMELA arises when programmers become modelers defining their own abstractions/annotations.
PAMELA’s software framework and features
PAMELA is composed of one design time component (the PAMELA metamodel which includes two main concepts, ModelEntity and ModelProperty plus a number of predefined annotations) and one runtime component (the PAMELA interpreter).
The main idea for the approach is to override Java dynamic binding. Invoking a method on an object which is part of a PAMELA model, causes the real implementation to be called when existing (more precisely, dispatch code execution between all provided implementations), or the required interpretation according to the underlying model to be executed. The PAMELA interpreter will intercept any method call for all instances of ModelEntity and conditionally branch code execution.
Pamela includes a number of advanced features: multiple inheritance and traits, containment management, cloning, fine-grained notification management, object graph comparison and diff/merge, visiting patterns, clipboard management, validation, support for design by contract by integrating assertions from Java Modeling Language (JML), Metaprogramming, Aspect Oriented Programming. Each of those features is described on a dedicated page that is reachable from the official web site. Additional information on the approach and components is also detailed in this article.
Industrial use cases and experiments
The PAMELA framework has been successfully applied in a variety of complex programming and modeling scenarios. In the following, we describe three important use cases in which PAMELA was a core component.
Openflexo infrastructure
Openflexo is a software infrastructure providing support for model federation across multiple technological spaces. Conceptualization is addressed through the proposition of a language called FML (Flexo Modeling Language), which is executable on the platform. Openflexo infrastructure introduces connectors (also called Technology Adapters) to support various technological spaces and paradigms.
The full Openflexo infrastructure is composed of about 50 components. In most components, the PAMELA framework is largely used. An interesting experiment has been done in the context of Openflexo development process. When PAMELA was integrated into the code base, a big portion of the former legacy code was gradually and iteratively been migrated to PAMELA. Refactoring mainly consisted in removing code, and replacing method implementation with API method declaration. In some parts of core model implementation, code has been reduced by 80% (in terms of lines of Java code), and many bugs disappeared, as they were caused by programming errors.
Formose project
The Formose ANR (French National Agency for Research) project (ANR-14-CE28-0009) (https://formose.lacl.fr/) aimed to design a formally-grounded, model-based requirements engineering (RE) method for critical complex systems, supported by an open-source environment. The main results of the project are a requirement modeling multi-view language, its associated design process and the development of an open-source platform called Formod, built using Openflexo infrastructure and the PAMELA framework.
Security Patterns experiment
A significant experiment in PAMELA is the implementation of security patterns weaved on domain code [1]. In this context, the PAMELA framework is extended to include the notion of Pattern, i.e. a composition of multiple classes. In this scenario, security patterns are specified by expected behavior defined and formalized by pattern contracts. These contracts are defined by formal properties which PAMELA framework verifies at runtime. A notable use case is the enhancement of existing Java code with the definition of additional security behavior.
[1] Silva, Caine, et al. “Contract-based design patterns: a design by contract approach to specify security patterns.” Proceedings of the 15th International Conference on Availability, Reliability and Security. 2020.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Recent Comments