

The current hype around Large Language Models (LLMs) is still going on, especially with the support of image to text generation for some LLMs, such as OpenAI’s ChatGPT4. This has led to some creative tools that allow the generation of corresponding HTML, CSS and JS code from either screenshots of web pages or just generally mock-ups with additional textual descriptions. One example that makes use of ChatGPT4 would be Make-real.
In light of these creative mock-up to frontend tools, I asked myself: What about using LLMs’ image understanding capabilities to generate UML class diagrams from pictures of models or even hand-drawn model sketches?
Contents
Why you should care about this
Adoption of modeling tools is a constant discussion topic. And usability of such tools is a common complaint. I think we can all agree that the fastest way to create a UML class diagram in any shape or form is by drawing it by hand. Not only on paper, but also on whiteboards, which further allows for collaboration.
Imagine the scenario of a team meeting to discuss the design of an application, where they crystallize their thoughts by collaboratively sketching the UML class diagram on a whiteboard. Yet, once drawn, there still is the need to transform the drawing into a more polished form, for example for documentation purposes. Additionally, one might also want a computer readable format to use the UML class diagram for code generation. Wouldn’t be great to be able to just take a picture of the whiteboard and immediately get it transformed into a “real” UML diagram?
This is also needed as part of legacy migration projects where, most likely, we won’t find the specification and design models of the system but we may still find a few drawings as part of the system docs. With an image to UML tool, we could at least create some first models based on those.
What are existing attempts?
As this is a real need, we are not the first ones trying to get this done. Previous attempts were relying on standard OCR techniques with limited results (e.g. they were not working with hand drawing models). An example would be the work Img2UML: A System for Extracting UML Models from Images, aimed to extract the UML class models from images and produce XMI files of the UML model. Unfortunately, we have not been able to access and test the tool. Other works just focused on classifying the contents of the image into different UML diagram types, e.g. Automatically recognizing the semantic elements from UML class diagram images.
Finally, attempts at using LLMs to create UML class diagrams are described in On the assessment of generative AI in modeling tasks: an experience report with ChatGPT and UML and Conceptual Modeling and Large Language Models: Impressions From First Experiments With ChatGPT. While providing positive results regarding ChatGPTs ability to produce PlantUML diagrams, models are only created from textual prompts.
Our Experiment
Given that nobody seems to have explored whether the new vision capabilities in recent LLMs could do a good job, we set out to answer this question ourselves.
Setup
As LLMs focus on generating text, I attempted to generate from a given input the equivalent UML class diagram in PlantUML syntax. PlantUML is a text-based diagramming tool that enables, for example the creation of UML class diagrams using a simple and intuitive syntax. It is useful for quickly and efficiently visualizing and communicating the structure of software systems.
I created 4 different UML class diagrams and for each diagram I created 2 drawn versions (on a whiteboard and on paper) and a draw.io version which I screenshotted. To keep the discussion short, I’ll use the whiteboard version as an example in the rest of the post, though the other variations shown similar issues. To process each whiteboard drawing, I used the freely accessible Microsoft Copilot, OpenAIs GPT-4-Vision model via the API, the free CogVLM model and Google’s Bard chatbot. I will show next the generated results, but also point out the number of mistakes per generation. For simplicity reasons, I define mistake as every missing element and every added element that was not part of the original class diagram.
The prompt was always the same: “Can you turn this hand-drawn UML class diagram into the corresponding plantuml class diagram?“.
Results
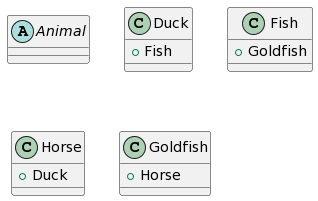
The first input image and the expected outcome is the following:
| Picture | Expected Outcome |
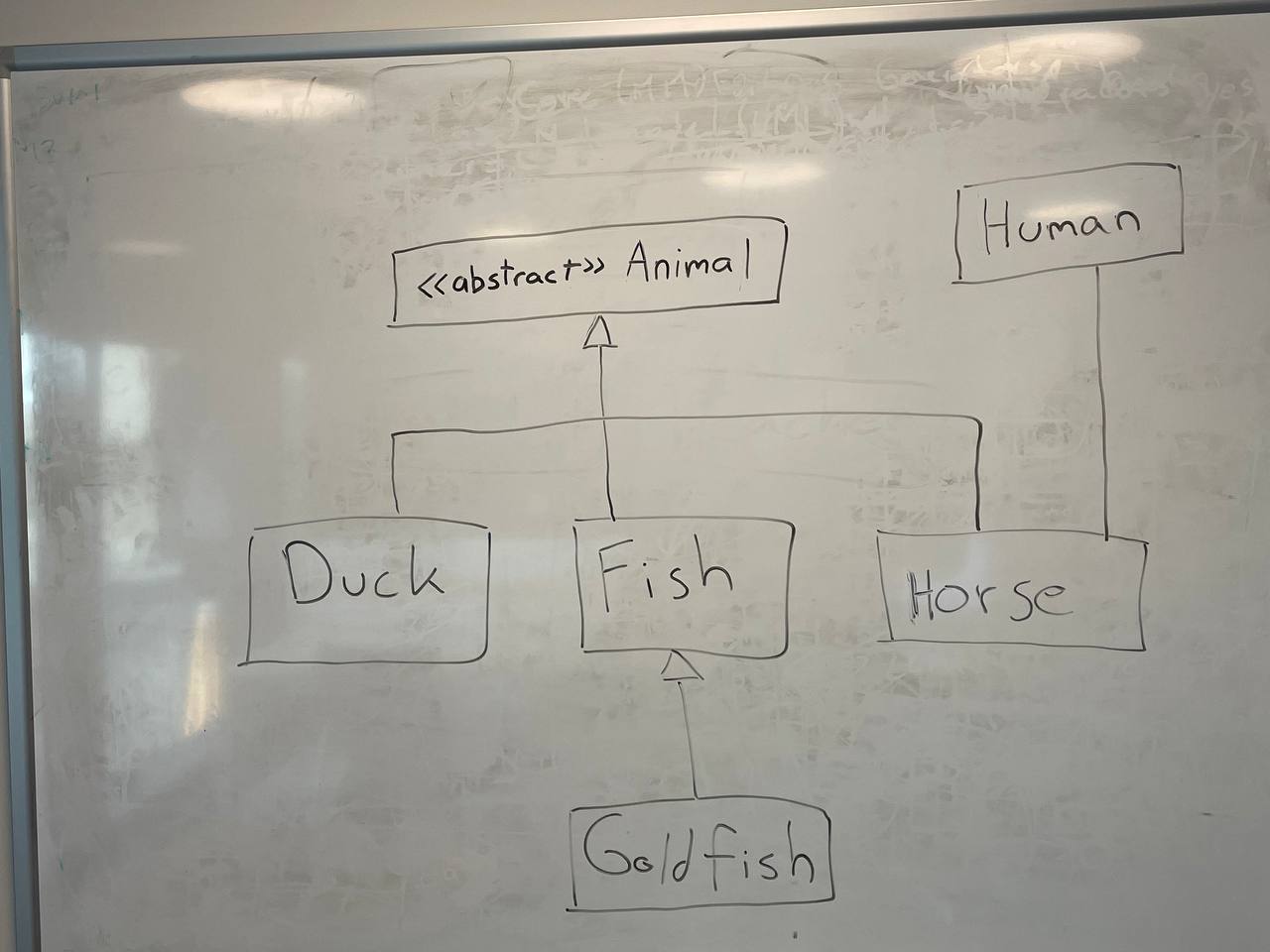 |
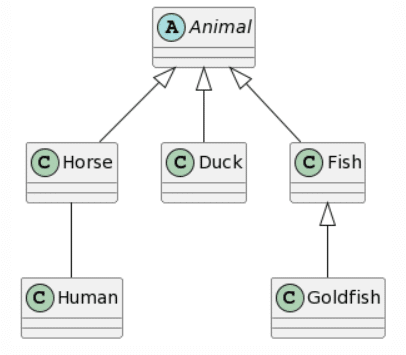 |
And here is the first result by each of the LLMs:
| Microsoft Copilot: 3 mistakes |
ChatGPT4: 2 mistakes |
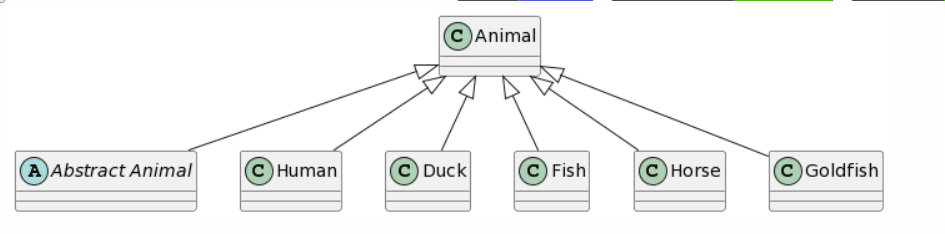 |
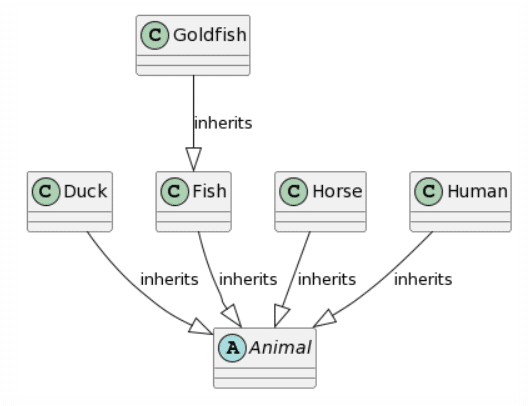 |
| CogVLM: 10 mistakes | Bard: 3 mistakes |
 |
 |
Note that, for Bard, 3 attempts were needed, until I got a PlantUML diagram. The two first attempts resulted in a response claiming that transforming a picture containing a UML class diagram into the equivalent PlantUML diagram was beyond its scope. From now on, I will also refrain from trying multiple times, and will instead only show the first answer to the query. Optimally, you shouldn’t waste more resources by needing to query the LLM multiple times to get a satisfactory answer.
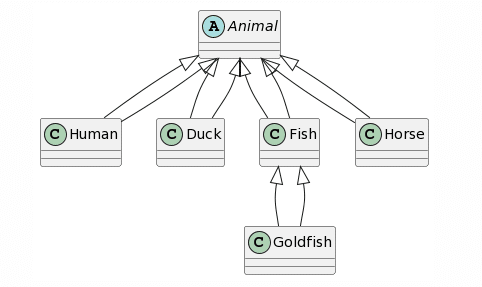
Regarding the results, ChatGPT4 provides the most complete representation, the only problem being the missing unidirectional association between Horse and Human and the addition of a generalization from Animal to Human. Bard provides a similar result, the only difference being the fact that each class inherits twice from Animal (which we considered as 1 mistake). Microsoft Copilot misses the mark a bit more by adding a class called Animal and lets Goldfish inherit from Animal instead of Fish. Finally, CogVLM provides some classes with correct names, but no relations at all and some questionable attributes based on the other classes.
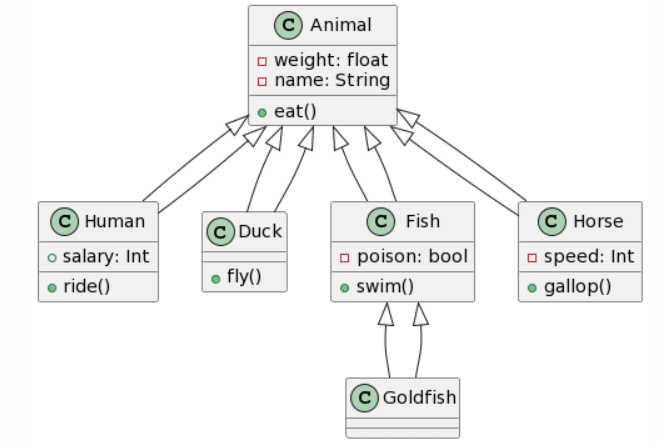
I now wanted to go one step further and extended our class diagram by adding attributes and methods:
| Picture | Expected Outcome |
 |
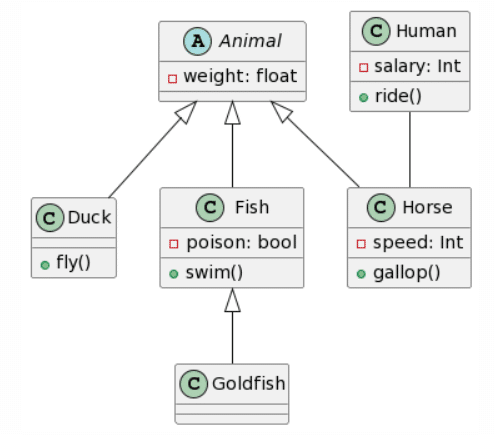 |
You can notice some elements that are inconsistent, such as the change of color due to the black marker not working anymore and the reflection of the light. I believed this might affect the results, yet, in a real life scenario, aspects like these are not to be avoided.
And here is the first result by each of the LLMs:
| Microsoft Copilot: 10 mistakes |
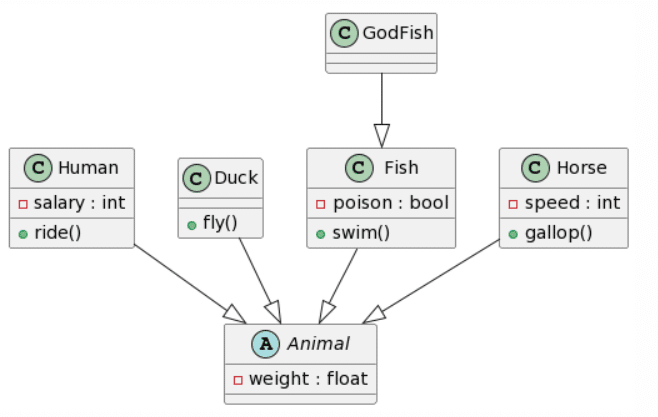
ChatGPT4: 2 mistakes |
 |
 |
| CogVLM: 9 mistakes | Bard: 5 mistakes |
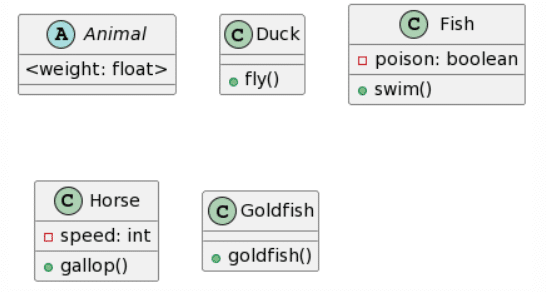 |
 |
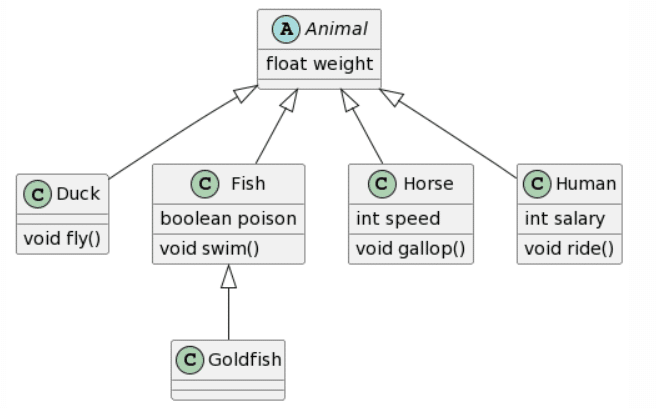
Again, ChatGPT4 wins this round with the only mistakes being the same as before. Bard creates an almost identical result, yet again has double inheritance for each class, and decided to add additional attributes and methods to the Animal class (which depending on the context might not be a bad thing). Microsoft Copilot provides also a fairly good result, with the same structure as ChatGPT4, yet fails to respect the given format for the attributes, and rather tried following Java conventions it seems and also ignores the accessibility of the attributes. Finally, CogVLM again has no relations, does a pretty ok job with the attributes, yet randomly ignores the existence of the Human class.
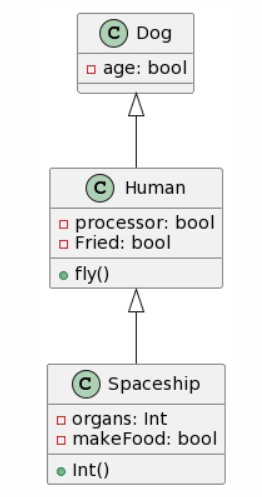
I now added a final level of complexity by including cardinalities and named associations:
| Picture | Expected Outcome |
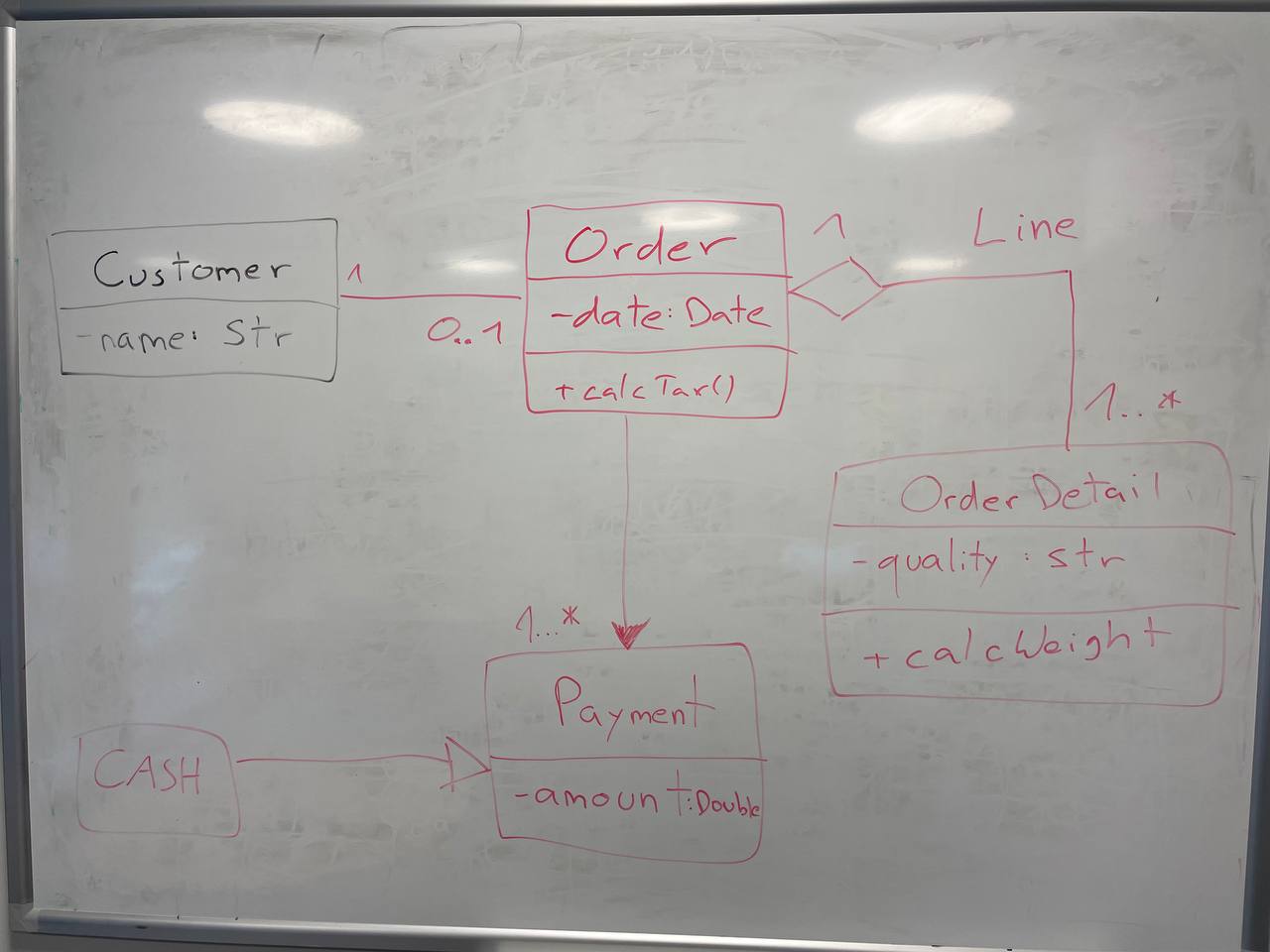 |
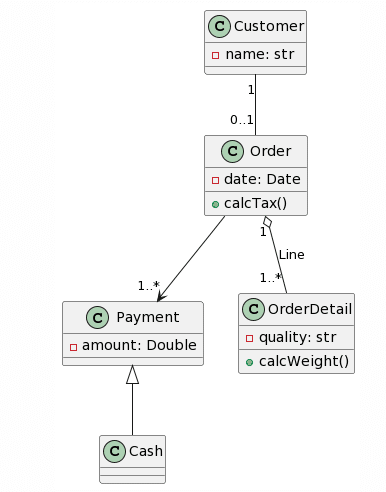 |
And here is the first result by each of the LLMs:
| Microsoft Copilot: 15 mistakes |
ChatGPT4: 7 mistakes |
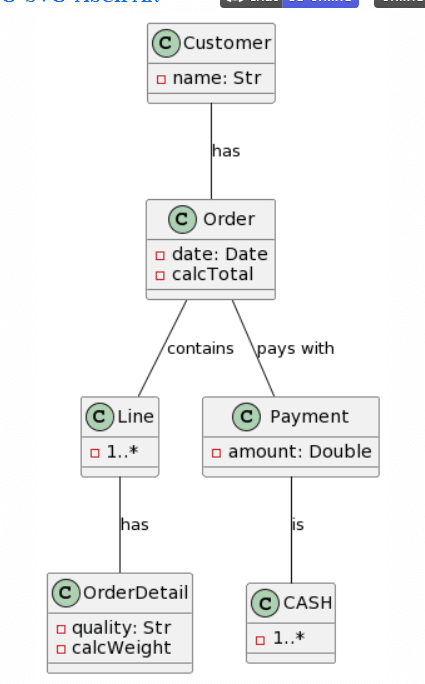 |
 |
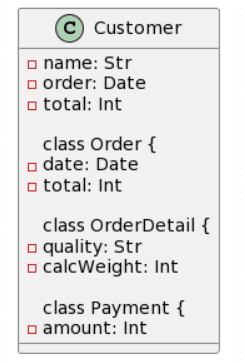
| CogVLM: / |
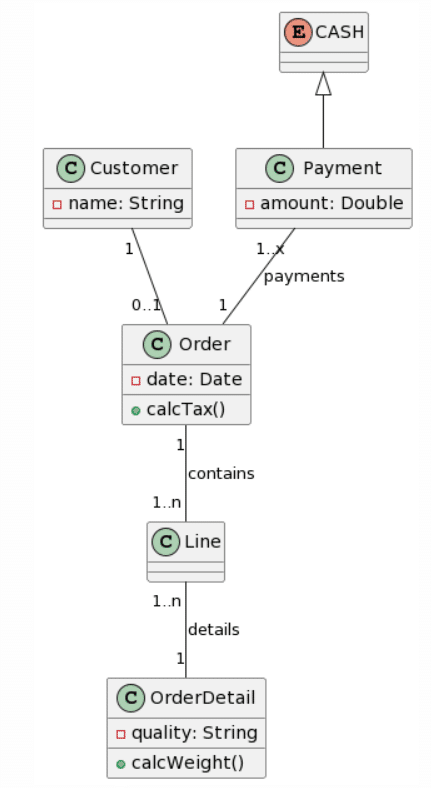
Bard: 22 mistakes |
 |
 |
Like before, ChatGPT4 provides the best generation, while not perfect, the cardinalities are pretty much correct, apart for an asterisk symbol being recognized as an “x”, the addition of a Line class instead of naming the association Line. Another interesting change was the change of the class Cash to being an Enumeration. This time around, Microsoft Copilot provided an almost correct class structure, yet failed with the cardinalities as they were added as attributes to some classes. Interestingly, this time the attribute’s format was kept and not changed to a Java style. Surprisingly, Bard seemed to have quite a lot of trouble with this example, as it only got 3 classes right, hallucinated 1 class into existence (Product) and had no associations right. There is not much to say about CogVLM.
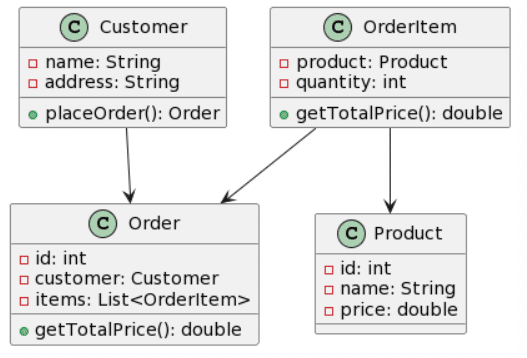
In my final test, we decided to create a nonsensical class diagram, in an attempt to check out the LLMs react to a structure that wouldn’t make sense in real life:
| Picture | Expected Outcome |
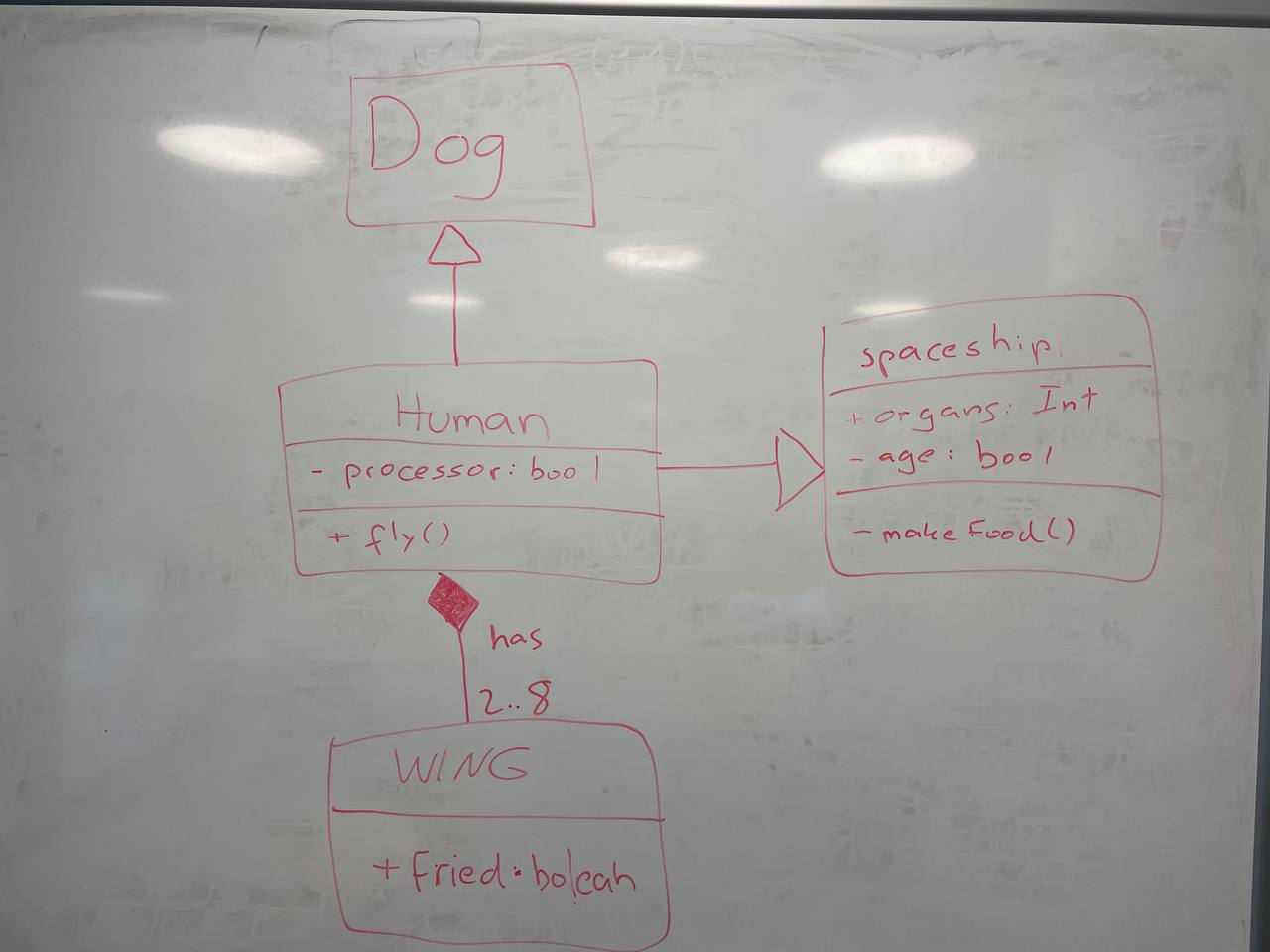 |
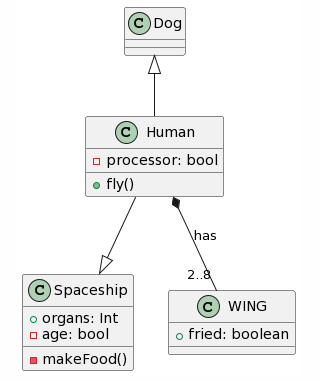 |
And here is the first result by each of the LLMs:
| Microsoft Copilot: 13 mistakes |
ChatGPT4: 5 mistakes |
 |
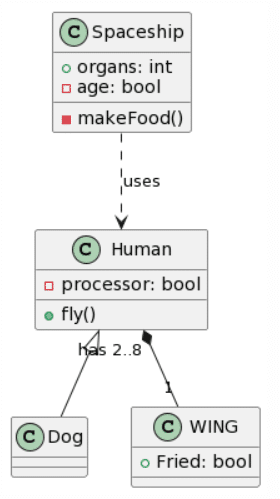 |
| CogVLM: 14 mistakes |
Bard: 17 mistakes |
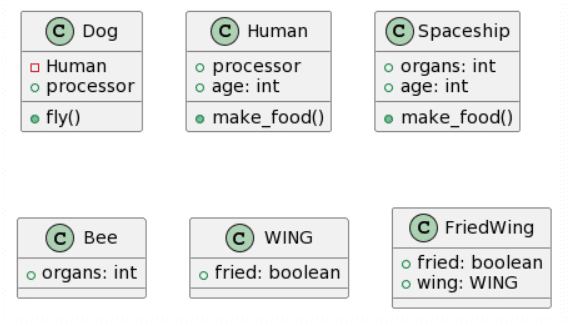 |
 |
Ultimately, ChatGPT4 manages to get the most complete transformation, although with some important mistakes as the specified generalizations being inverted or transformed to a unidirectional association and putting the cardinalities at the wrong end. Microsoft Copilot also managed to do a decent job, while forgetting the WING class and adding non-existent attributes, it managed to get one generalization right. Bard seems to have removed the classes WING and Spaceship and decided to hallucinate attributes into existence. CogVLM follows the same usual pattern of creating some of the correct classes, while ignoring relations altogether and creating random classes that might fit in terms of context (such as FriedWing fitting with WING).
Discussion
In this short experiment, I only focused on generating the PlantUML code using the same prompt and only judging the first result the LLM provided. We generally saw that ChatGPT4 managed to get the best results and acted the most consistent overall. Yet, only using one prompt and only assessing the first result might not necessarily be conclusive in terms of results.
Although I wanted to keep things short for this blog post, I noticed upon further testing, how nondeterministic the results were at times. While ChatGPT4 and CogVLM usually provided results in consistent quality, Microsoft Copilot and Bard seemed to both provide very good or very bad results depending on the attempt. Furthermore, at times, both Bard and Microsoft Copilot refused to generate something, as both tools claimed not to be able to handle such a request. Therefore, it might make sense to either perform a check in the backend if PlantUML code was provided or provide multiple results to the user and let them decide which one they feel seems best (this leads of course to the drawback of needing to waste more resources, be it computational resources but also monetary for paying models).
Additionally, the fact that I only used one simple prompt might also have affected the results. As we saw with some of the results, sometimes random attributes or classes were added that, while fitting in the context of the given example and correct in logic, were not wished by me. Hence, creating a more precise prompt might have prevented such a behavior. A better prompt might have been:
“Transform a hand-drawn UML class diagram into PlantUML syntax. The hand-drawn diagram may include unconventional relationships that don’t make sense in real-life scenarios. Disregard common sense and focus solely on translating the elements, classes, and relationships into valid PlantUML code. Your goal is to provide a faithful representation of the hand-drawn diagram using PlantUML syntax without adding additional descriptions. Additionally, stick to the python class notation.”
A more concrete prompt such as this might have provided better results, especially if it may have helped avoid inventing attributes.
Regarding CogVLM, although it never included relations in the generated PlantUML code, if requested to only describe the UML class diagram contained in the picture, it actually does recognize that there are relations:
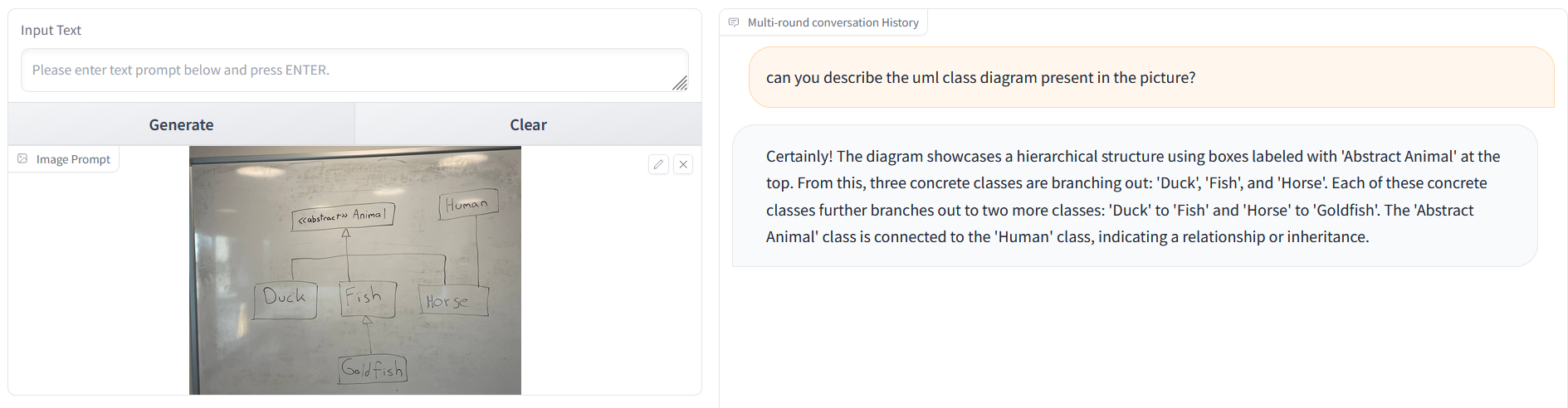
While the provided description is not perfect, it seems that the PlantUML generation also partly fails due to the model not being an expert in PlantUML generation, which might point toward a lack of data in that regard. At this point, if one would want to stick to free models, it could be possible to use CogVLM’s image to text generation to generate the description of the class diagram and generate the actual PlantUML code using a more advanced free Text-to-Text model.
When looking at the nature of the errors, the most common one seems to be to both wrongly and not recognizing relations. As the LLM’s act as blackboxes, it’s difficult to reason the errors. A possibility could be that, the LLMs don’t perfectly recognize the exact type of relation, but rather only are aware that there is some form of relation. At this point, there might be some confidence percentage about the type of relation, and if too low, the LLM might decide to make assumptions. Furthermore, if a relation might be nonsensical in real-life, this could further decrease the confidence score, as such a relation might be regarded as a possible semantic error based on the LLM’s knowledge.
Conclusion and Future Work
Overall, I experimented on LLMs’ abilities to convert pictures of UML class diagrams into PlantUML code. The initial results suggest that, while some free models create appropriate results, the price of ChatGPT4 still seems to pay off in terms of quality (although surprising, as Microsoft Copilot itself also uses ChatGPT but maybe not exactly the latest version). Additionally, even though the free Microsoft Copilot and Bard models provide good results, these do not come with any kind of API. Thus, it is not possible to smoothly integrable them into a development pipeline. The provided results still show that LLMs are a good fit for easily converting images to a UML class diagrams, although with the need of inspecting the provided result, thus the human in the loop process.
For future work, there are multiple interesting directions to explore. First of all, it might prove useful to conduct a more systematic and complete approach to comparing the models. This would include conducting more tests with the same prompt and models, for example 50 generations per prompt and model. Furthermore, instead of verbally pointing out some of the problems, we would need to more concretely count the errors to actually provide error statistics.
Taking a look at different prompts and their outcomes might also prove fascinating, in a way optimizing the prompt such that the generation provides the best results. In a similar fashion, instead of only providing the results, one could specify that the LLM should transform the input, but also act as a teacher and provide feedback on some of the elements that are present. For beginners in UML, they might attempt to draw a UML class diagram which might have some mistakes in terms of semantics and not syntax. A chatbot could then act as a teacher and correctly transform the UML class diagram, but point out some aspects of the model that might need revisiting, thus gaining a learning tool.
Generally, it might be interesting to let actual software engineers or computer science students use such a tool and conduct surveys to find out about its usefulness.


Interesting work. There are some clear mistakes in your second “expected outcome” though. (wrong positioning of swim(), weight…)
Best regards,
Johan
Thank you for pointing that out! It should be correct now.
Best,
Aaron
Aaron’s reply sounds very much like ChatGPT when you correct it. And he made four mistakes whereas ChatGPT only made two.
I think one of you just passed the Turing test, I’m just not sure which 🙂
(Aaron’s original version:
https://modeling-languages.com/wp-content/uploads/2023/12/level2_solution.png – weight duplicated, salary_ instead of salary:, poison and swim() pushed down)
Fortunately, the reason for my mistakes is the very boring “human-error”, which is not as hard to explain. I’d assume making more mistakes than ChatGPT would increase my chances of passing the Turing test 😄