

Continuous Delivery (CD) is becoming the most popular agile practice. From the Agile Manifesto: Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
Continuous delivery encourages a more frequent software integration and testing process; and claims many advantages (shorter release cycles, faster feedback, visibility of the process, automatization, quality, etc…). Continuous development relies on the related concepts of continuous integration and continuous deployment. For a discussion on the (somehow overlapping) relationship between these terms read this.
Given the important role model-driven engineering (in any of its versions) plays nowadays in software development, the natural question is: how can we combine modeling and continuous delivery? And how can this combination benefit both paradigms?
We call this combination: continuous model-driven engineering. We believe this integration can be done at two different levels: 1 – using modeling artifacts in a “normal” continuous delivery process and 2 – Using continuous delivery to develop the modeling artifacts themselves.
We have explored both scenarios. Initial results were presented at DEVOPS’18 as part of our accepted paper: Stepwise Adoption of Continuous Delivery in Model-Driven Engineering. A summary of the paper follows.
Modeling artifacts in a Continuous delivery process
Most software development processes involve some kind of modeling artifact (even if for documentation). This forces any continuous delivery strategy to take into account those artifacts in the integration and deployment pipelines for the software (e.g. every change in an input model may need to trigger a new code generation process or the release of a new version may require updating the documentation automatically derived from it).
I’m afraid this is not really the case and typically models are left out of the process. But the question is whether there are technical reasons for this or it is more of a culture problem. Is it actually possible to chain MDE tools in a continuous delivery process?
The answer is a rotund yes. For each major MDE activity (model-to-model transformation, model-to-text transformation, model comparison,…) we can find a tool that can be executed standalone in batch mode by calling the tool with the right model/text parameters. This allows modeling tools to be integrated into continuous deployment servers, allowing the creation of pipelines (chained jobs) involving MDE tools.
The main limitation is that the integration server is not model-aware. This implies that all dependencies between jobs are manually added, coevolution is limited to alerting developers when an element needs to be manually reviewed and any new model version triggers all depending jobs.
Clearly, CD in MDE is possible but there is still work to be done. Model-aware CD processes would do a better job in interpreting when and how a model change affects the pipeline.
Continuous delivery in the development of modeling artifacts
Modeling artifacts evolve as often as any other software artifact. And not only the models evolve, but also the metamodels / languages, the transformations,… . This poses a real challenge when building a MDE infrastructure for a given domain or project. This modeling ecosystem needs to be evolved and maintained in a coherent way. Then, the questions is: Can continuous development help to maintain faster and better an MDE infrastructure?.
Again, the answer is yes. Analogously to traditional CD, where the goal is to have the mainline always in a deployable state, the aim now would be to have the modeling infrastructure always ready to be used. Wouldn’t it be nice to have our domain models always conforming to their metamodels and the transformations always ready to be executed, e.g. to generate code?
While there are many proposals for the coevolution of modeling artifacts, they often involve manual activities and target only pairs of components (a metamodel and its models, a metamodel and its transformations,…).
We propose a more ambitious approach where the co-evolution is reactive, multidimensional, automatic and parallelizable. Co-evolution tasks would take advantage of CD practices and tools: change detection would benefit from push notifications of CD servers, impact analysis would benefit from testing automation, and adaptations would benefit from automatic triggering depending on the result of previous tasks.
As an example, the following picture illustrates a co-evolution pipeline, with the typical steps in a co-evolution scenario (change detection, impact analysis, co-evolution):
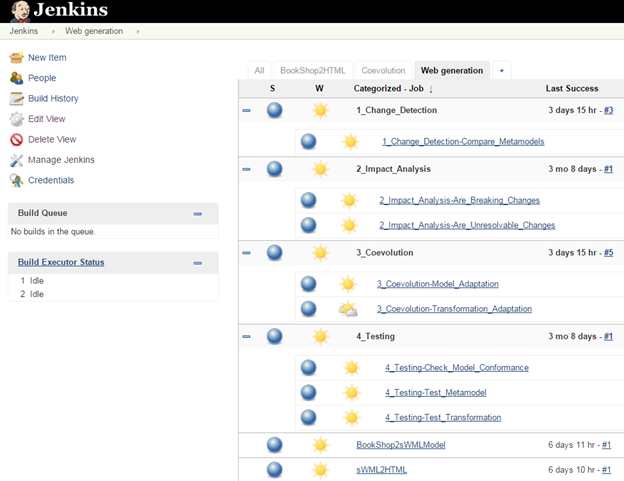
Example of a pipeline for the continuous development of a model-based project
The above example is just a proof-of-concept that we manually implemented in Jenkins to test whether those ideas would be feasible. Still, it’s a first step towards this goal.
If we are able to start extending continuous integration servers to teach them how to calculate the dependencies and propagate changes among all combinations of modeling artifacts (leveraging many of the proposals in the research literature) we would achieve a significant next step towards the maturity of model-driven engineering practices.
As always, if you are already using MDE within CD or have any thoughts on this topic, we’ll be happy to hear them!
ICT services at IK4-Ikerlan


The Umple project (www.umple.org) has been using continuous integration since its inception 10 years ago. Umple is a modeling tool, but it is written in itself using model-driven, test-driven processes.
Great to hear that, Tim! Any comment or advice on that experience?
Thank you
Suggest you read this research paper I was asked to write a few year ago
http://www.igi-global.com/chapter/object-model-development-engineering/78620
And my comments in this forum http://bpm.com/bpm-today/in-the-forum/4537-has-bpmn-slowed-down-the-adoption-of-bpm
Decades ahead of the game no code generation or compiling with a data centric architecture really does at all with continuous improvement/development supported….but very disruptive but MDE now rising in profile helped by this forum.
You might like to have a look at my MODELS’18 paper “Towards sound, optimal, and flexible building from megamodels” – I think this approach has something to offer concerning management of dynamic dependencies. Open access version via my institutional page https://www.research.ed.ac.uk/portal/en/persons/perdita-stevens(acfe1cde-a9dd-4f2d-817b-cf17dcb50331).html