
Collaboration between developers and end-users seems particularly fitting when developing Domain Specific Languages (DSLs) given the fact that DSLs target the experts of a domain. However, current DSL development processes are completely centered on the developers who still lead all phases of the DSL development, while end-users only participate in the very beginning, when the domain is analyzed, and they cannot see how their input was interpreted until the modeling environment for the new language is deployed. The validation is therefore performed at the end, which implies rebuilding the environment (a very costly process, even with current language workbenches) every time the end-user wants to change the language definition (e.g., to add new properties to a metaclass, change their type,…).
To improve this situation, we propose to make the development process for DSLs community-aware, meaning that all stakeholders (i.e., technical and end-users) have the chance to participate, discuss and comment during the DSL definition phase (currently, this process only covers the abstract syntax, i.e., the metamodel, part of the DSL, but it should cover also the collaboration process for the concrete syntax). Moreover, we believe it’s important to track this discussion so that in the future we can justify the rationale behind each language design decision.
Contents
Community-driven language development
The following figure summarizes the key differences between a community-driven language development process and a traditional one.

End-user agreement in (a) a traditional language development process, where a restart may be required due to misunderstandings, and in (b) a community-driven process, where each development phase is agreed by the community, thus involving a possible restart the same phase.
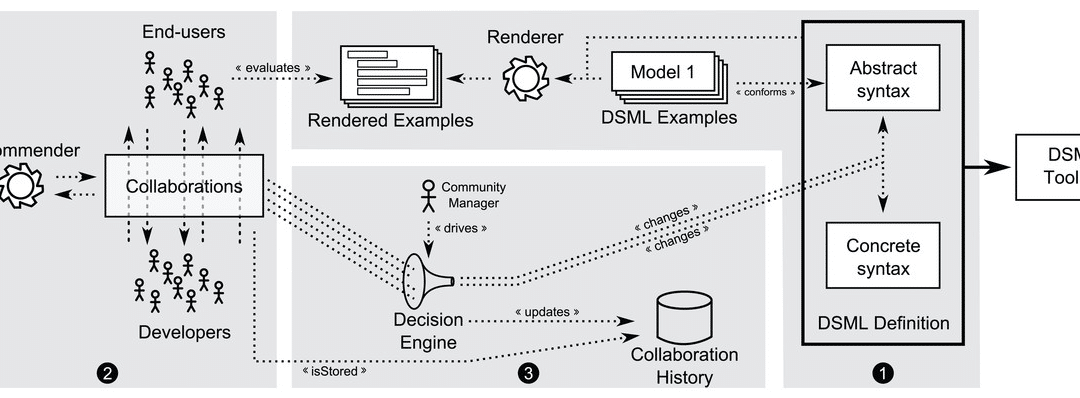
This collaborative process is also illustrated in this other figure showing how the key goal is accelerating the feedback and making sure the DSL concepts are agreed upon all the stakeholders from the very beginning instead of waiting until the modeling tool based on such DSL is fully created.

To make this collaborative development process feasible, it is essential to facilitate as much as possible the collaboration between all people involved. Our solution is based on a new DSL, called Collaboro, to represent the collaborations which arise among the members of a language community.
Collaboro: a collaborative (meta)modeling tool
Collaboro enables the involvement of the community (i.e., end-users and developers) in the development of (meta) modeling tasks. It allows modeling the collaborations between community members taking place during the definition of a new DSML. Collaboro was implemented as an Eclipse-based tool and as a web-based solution that can be used by all kinds of users willing to have an active role in the evolution of their DSL. You can take a look at the project on this webpage or read the paper Enabling the Collaborative Definition of DSMLs. CAiSE 2013: 272-287 or, even better, the more recent: Collaboro: a collaborative (meta) modeling tool published in the PeerJ journal. The tool is not maintained anymore (though we plan to reimplement it as part of BESSER in the future).
The core of the abstract syntax of the language is shown in the following picture. As you can see, with Collaboro you can track all the change proposals, solutions (plus the set of changes to apply on the DSL to adopt the solution), comments or votes. The DSL element can represent both abstract (e.g., concepts and attributes) and concrete (e.g., notation symbol or keywords) elements of the DSL under development so that collaboration can arise on any element of the language.

To show how Collaboro works in practice, imagine a Transport DSL used by a transport company to represent its fleet and calculate the most efficient path between several points. The DSL therefore includes concepts such as Truck and Route to model the distribution maps (top part of the next Figure). Thanks to the fact that we are now following a collaborative development process, by looking at this initial version of the Transport metamodel, End-user 1 detects that Transport is missing the possibility of stating the traffic density of each Route concept and claims this is an important concept for the language. Since the rest agree, an initial solution is proposed and improved (after a comment suggesting a slightly different strategy, which is voted and selected by the community).

As can be seen, both the collaboration and the decision processes are modelled. In this case, we have applied a full agreement policy, so the change proposal and the corresponding solution are marked as accepted only if every community member agrees. Other, more complex, governance models are also possible.
While our first versions of Collaboro supported the collaborative development of textual DSMLs in an Eclipse-based environment, the last version offers:
- Better support for the collaborative development of graphical DSMLs;
- A new architecture which includes a web-based front-end, thus promoting usability and participation for end-users;
- A metric-based recommender system, which checks the DSMLs under development to spot possible issues according to quality metrics for both the domain and the notation (relying on Moody’s cognitive framework (Moody, 2009))
- The development of several cases studies, which have allowed us to improve the general expressiveness and usability of our approach
Crowdsourcing your notation
As we have said above, the collaborative process should also cover the concrete syntax of your language so that your future users can also participate in the discussion for the best icons, shapes, colors, keywords,… of your graphical (or textual) notation.
You could keep track of the whole process in Collaboro itself, where you can define the notation for each metamodeling element and even show examples of models rendered with that notation as part of the decision-making process.
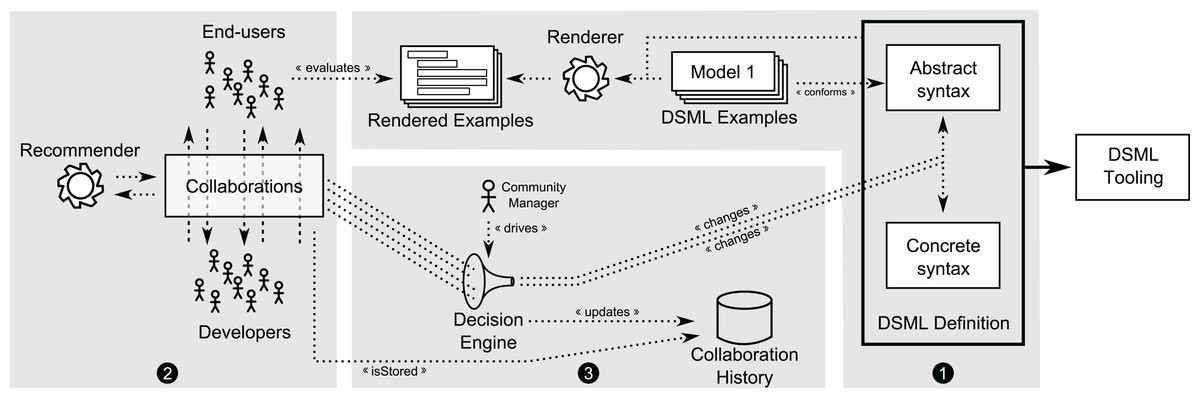
Full collaborative development process
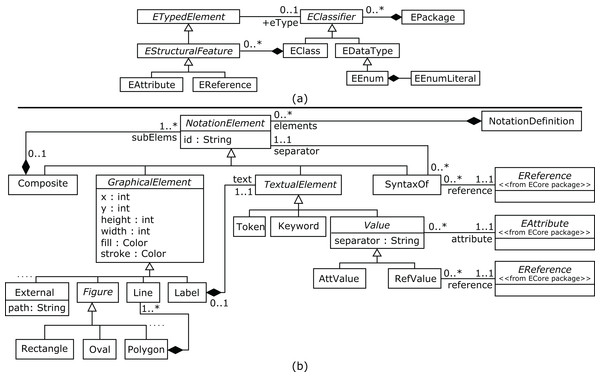
This subset of the Collaboro metamodel shows the details of the notation metaclasses
But this strong collaboration restricts the number of participants. If you really want to test your possible notation with a large number of users, we propose a two-phased approach where you combine a Collaboro-based approach with a restricted group of users together with a crowdsourced approach to get faster feedback from a larger user base. This could be a great initiative that even major modeling languages (UML, SysML,…) could (and should) take.

As part of this crowdsourcing experiment, you could even run some A/B tests for your notation to choose the alternatives that work best as part of a controlled experiment.
Evolving your language
No matter how good is your initial language design, it will need to evolve overtime as the domain, the users or the usage of your DSL changes. We could trigger revisions of the language from time to time. But you can also run some automatic tests to check how the language is used and detect some issues. Here we would propose the detection of usage patterns to improve language design.
More on language design
This post has been evolving since we started exploring these ideas around ten years ago so in the comments below you’ll also find pointers to other ideas and approaches for language design. Make sure you take a look at them as well!

I’m an Associate Professor at UOC and researcher at SOM Research Team, in Barcelona, Spain. My research interests are mainly focused on Model-Driven Engineering (MDE), Domain-Specific Languages and Collaborative Development.


very interesting. what does “current DSL development processes” refer to?
You’re right, the term “current DSL development processes” may be a bit confussing. With this term we wanted to refer to the existing approaches and recommendations to develop DSLs (e.g,. “When and how to develop domain-specific languages” from M. Mernik, J. Heering, and A. M. Sloane).
This comment make me think that perhaps, in MDE, we cannot still speak about a well-known DSL development process (any comment or suggestion is welcomed).
Interesting.
I see in the use case, it is an Eclipse plugin. Is it possible to use it online in a multiuser enviroment (let’s say, an actual company)? Or is it a proof of concept?
Thanks.
Hi Ricardo,
At the moment it is a proof of concept (as it usually happens with all research prototypes 🙂 ) so synchronous editing of the Collaboro model is not supported yet. We hope to find a company interested in industrializing it (like here https://modeling-languages.com/industrialization-research-tools-atl-case/ )
It sounds like you need to widen your idea of “current DSL development processes” and “current language workbenches”. Is it really the case that in the Eclipse / academic world, language development processes and tools are as bad as you suggest? Or do you just need to portray them in a negative light, to set the stage for the improvements in your paper?
Developing the language in isolation from its users is clearly a bad idea – can you find anyone who suggests that? For a more sensible process, and one proven in practice over the last 15 years, take a look at Domain-Specific Modeling by Kelly & Tolvanen (www.dsmbook.com), or Laurent Safa’s article from the OOPSLA DSM Workshop in 2006, http://www.dsmforum.org/events/dsm06/Papers/19-safa.pdf, where he lists as the first two commandments:
– Get embedded into the practitioner team
– Observe the way people work to understand their context
In which language workbenches is “adding a property to a type” a “very costly process”? In MetaEdit+ it takes less than 10 seconds to add a property and deploy the updated metamodel and tool support to all the modelers.
Recording design rationale is something we experimented with in MetaEdit+ in 1992-1998. Look up research by Harri Oinas-Kukkonen and Janne Kaipala. In the end we didn’t find as much practical benefit from it as we’d hoped – a heavyweight change process didn’t fit in well with an agile approach to changing the language (or models). Rather than one fixed process and set of concepts for design rationale, we decided to let customers make their own, to the extent they felt it useful. That seems to have worked better, and of course it’s more domain-specific, so fits well with our philosophy.
Hi Steven,
Some comments:
> Or do you just need to portray them in a negative light, to set the stage for the improvements in your paper?
Not at all, this is more the task of tool vendors 🙂
> In which language workbenches is “adding a property to a type” a “very costly process”?
As I’m sure you understand, the post uses a simple example to keep it short but, if the value in the new property affects the way the object is displayed we do need to perform some non-trivial changes.
> Developing the language in isolation from its users is clearly a bad idea – can you find anyone who suggests that?
I’m sure nobody recommends this. It’s more that the lack of tool support forces people to work this way (i.e. without “persisting” the discussion and/or letting the user to be a more active, i.e. hands-on, participant). We believe observing is good but not yet enough. Sure, we have in the agenda the need to conduct some experiments to validate this assumption.
Hi Jordi,
Thanks for the clarifications. What is the language workbench, and how long does it take to add a Traffic Type enumeration property to Route, and have the concrete syntax display its value e.g. in a small font at the bottom centre of the symbol? Just do it and time yourself for the first time, not for how quickly you can type once you know what the code should be 🙂
What are the benefits that you see which offset the “very costly process” and “lack of tool support” in that current language workbench, rather than some other language workbench which would make changes on the fly easier?
Do you think Safa’s Joker concept or Oinas-Kukkonen’s Debate Browser would be a useful approach for this language workbench? Having the user’s comment in the context of an instance model, rather than the metamodel, may make it easier for the user to express himself, and easier for the metamodeler to understand the comment.
The concrete syntax for the decision model above is much nicer than the black and white boxes in the paper – is the syntax above really in the tool, or is that just a picture?
Steven,
Thanks for the pointers to these works. I don´t think we were aware of them.
One thing that for sure would be nice is that users can ask for changes “by example”. It would be great if the tool allows them to define the model they would like to be able to define (even if this model is not 100% conforming to the metamodel) and then ask the designers to change the metamodel in a way that the model becomes possible.
Regarding the concrete syntax, the one in the post is not implemented. In fact, as we say in the post, Collaboro at the moment has no concrete syntax yet, it has to be used from the tree view of the (meta)model
In this context, I would kindly refer to my thesis in the area of model versioning. In this thesis, a conflict-tolerant merge approach incorporates all changes of all developers and highlight the occurred conflicts. These conflicts can be resolved following a collaborative approach by prioritizing the individual changes.
http://www.ub.tuwien.ac.at/diss/AC07812234.pdf (Chapter 5, p.67ff)
Cheers,
Konrad
Hi Konrad,
Thanks for posting your thesis, it’s good to see AMOR research here! There are a couple of methodological points about the experiment in Chapter 7 that bear mentioning. Before going through them let me say that I thoroughly believe the overall thrust of the results you obtained; I just want to show how you could have improved the validity.
First, if you are comparing two different tools for doing the same task, you should randomize the order of the tools for the subjects, otherwise the 2nd tool gets a significant benefit. You’ve done well to use different task data for the different tools, but changing the order too would improve the validity.
Second, in your questionnaire all of the questions are effectively “our CT Merge is better than EMF Compare”. Asking the question in such a leading way puts serious doubts on the validity of the results. Better would have been to vary the order of the comparison; best perhaps to simply have the subject score each tool separately on a 5-point Likert scale for how well it carried out the task of that question. By just asking “is A better than B?” you lose the ability to see how big the difference is between them.
Finally, even if you’re not going to claim statistical significance, you should certainly try and stick to some basic statistical and mathematical principles. Stating percentages to three significant figures, on a population of just 18, is kind of overdoing it :).
My biggest qualm however is not academic, but more from the real world. Your experimental setup assumes three people working on the same small model, and you force them to make conflicting changes. That goes against your survey finding, that work is divided up to avoid conflict. It also goes against research on modeling tools back in the 90s, that showed that only 3 out of 1000 operations are conflicts. Your experiment is still worthwhile for investigating ways of dealing with conflicts, but you haven’t really studied whether a better approach, avoiding conflicts in the first place, would be more effective overall. Having talked to rather a lot of people working on large modeling projects, some using a merge-based approach and others using fine granularity locking, I can say with some certainty that locking works far better in practice.
Our research on this topic was back in the 90s, so it’s a shame that your comparison of tools and approaches doesn’t extend that far. If you’re interested you can look at Chapter 5 in my thesis (http://www.metacase.com/stevek.html), or at a recent article from OBJEKTspektrum on Mature Model Management(http://www.metacase.com/papers/Mature_Model_Management.html). The article basically lays out how we’ve made a number of very different decisions from the EMF+UML+XMI&VCS+merge approach, replacing it with a GOPPRR+DSL+repository+locking approach, and what benefits have been obtained from this. It would be interesting to hear your feedback, and whether you’re able to get past the fact that we basically throw out everything that today’s academic modeling research takes for granted!
All the best,
Steve
Hi Konrad,
We are well aware of your work and I do believe it´s complementary in many aspects (in fact, we had a chat with Manuel at the beginning of our work on Collaboro to start exploring this complementary but we decided to wait until our idea of Collaboro was more developed, I guess it’s time to meet again!)
Hello,
Another interesting approach to collaborative modeling is the ComMod (Companion Modeling). Wich focus on iterative modeling to design complex systems. And also aims to collective decision making for collective agreement.
To test the model/metamodel/DSL, you can put in place some role playing games and figure out how the DSL would be used by end users.
It is mostly used in sustainable development and to validate multi agent systems for simulation.
You can find the charter of the ComMod there : http://cormas.cirad.fr/ComMod/en/charter/
Regards,
Xavier
This is obvioulsy interesting and needed in practice, but collaborative language development tools already exist: See 10min video at: http://www.metacase.com/webcasts/multi-user.html. Not only language users can join the DSL definition, but note that also models update immediately based on the changed made. This makes DSL development agile and emphasize participation leading to better DSLs.
Since all are customizable on the langauge side, you could also add here the ’Collaboro’ concepts too. The practice we often see is that language users can apply joker, comment etc concept to give their feedback. Depending on the user rights – as shown in the video – users may also be allowed to do the changes by themselves.
Yours,
Juha-Pekka