

The adaptation of modeling languages has become a common need in companies because the available standard languages (like UML, BPMN, or IFML) are either too complex with respect to the actual needs or are not perfectly matching the domain to be modeled.
So far, the issue of languages adaptation has been typically addressed by either creating a new brand domain-specific modeling language (DSML) or by extending an existing base language.
In our study , to be presented in the upcoming SLE 2015 conference, we propose a language adaptation approach that starting from an existing modeling language, simplifies it according to the user needs.
Our simplification process relies on a set of steps that encompass:
- Selection of language elements to be included
- Generation of a set of language variants
- Measurement of effectiveness of the variants through user modeling sessions, and
- Extraction of quantitative and qualitative data for guiding the selection of the best language refinement.
The simplification process pretends to be generic but we illustrate it using a concrete use case, namely the simplification of Business Process Model and Notation (BPMN) with the aim to make it a suitable language for simple personal tasks (personal process) modeling. Personal process management refers to the application of BPM techniques and tools to personal task management, to-do lists, and small work plans shared with friends and personal contacts (Fluxedo is a good example of concrete implementation of such family of processes). The simplification process is represented below.
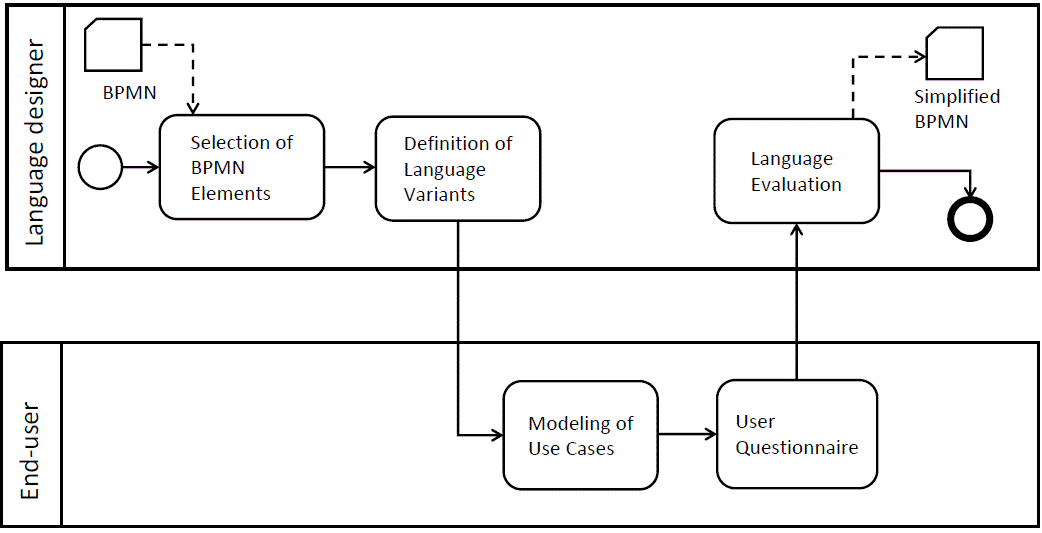
Let’s see each phase in more detail:
1. Selection of BPMN elements
In this phase, we identify the elements of the BPMN that are suitable for the modeling of personal processes. During the elements identification we consider both the nature of personal tasks and the users’ needs, which differ from the needs of organizations for which the BPMN was designed. The output of this phase is a set of language elements with their full description in terms of relevance and relationships.
2. Generation of the language variants
In this phase, we take in input the elements defined in the previous phase and we produce a set of alternative syntaxes, the language variants. Language variants are generated from a sub set of the language elements.
We have built four language variants all having the basic elements in common: start and end events, task and sequence routing. Those are the mandatory elements for a notation allowing the modeling of personal process. We built a linear variant with global parameters, events, parallel routing but not conditional and loop gateways. We also built a more complex variant with multiple local parameters, conditional routing but no parallel gateway. The other two variants were instead more balanced.
3. Modeling of use cases by end-users
In this phase, the users test the language by modeling the assigned use case. A use case represents a pair of a personal process with the language variant to be used to model it. The users were asked to model real life processes like the planning of a holiday with friends or the organization of a party for an association. A logging system logs the users’ actions (such as the creation, modification, and deletion of an element) useful to derive quantitative data allowing to compare and evaluate the language variants. We also monitor the users by taking the notes on how they model the assigned processes, by direct observation.
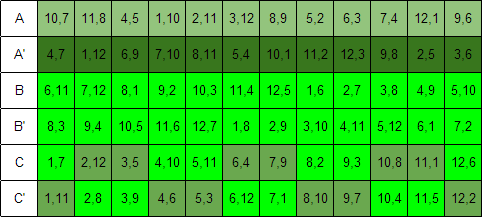
Table of valid experiment
Each cell represents a single experiment made by two use cases to be assigned to a single user. Valid experiments are obtained from Graeco-Latin square of use cases by dropping invalid experiments, experiments which have the same scenarios and/or same variants in both tests.


Recent Comments