
We present our new traceability metamodel, to be presented at SAM’21. As, clearly, ours is not the first traceability metamodel that has ever been attempted (more the opposite!), we start by describing some background on traceability proposals, the key qualities we believe a treacabiliy metamodel should have and the details of our own proposal. Keep reading to learn more. You can also download the paper [1] and the slides.
Contents
Traceability through the years
Historically, traceability has been concerned with maintaining the link (sometimes conceptual or implicit) that exists between specification and design documents, and software implementation artifacts. It attempts to link the semantic intentions, made from the expertise of the application domain, with their syntactic extensions, expressing in computer terms the means developed to automate their operations.
Seminal studies of the field appeared in the 90s with authors such as Gotel et al [2,3]. The idea was then to offer a point of view on the causal links which govern the modifications of the software: downward causality when changes to the specification affect the source code; ascending causality when it comes to updating the specification as a result of changes to design elements or source code. Considering the current level of software volatility – it is constantly changing, sometimes with multiple fixes made every day – these casualties become difficult to track down. As a result, the prevailing feeling that traceability tools seem to be chasing too fast a rabbit and falling into disuse after the first executed project is unfortunately well entrenched. The number of failures and unused projects in the field is sadly high.
Thirty years have passed since the Gotel calls. The foundations have remained the same, firmly anchored in research: the traceability tools must be adaptable to specific problems, customizable for the areas considered ad hoc, automatable as far as possible, and they shall generate information rich enough to meet the (predefined) goals [4,8]. Scientific advances, on the other hand, have remained somewhat discreet in the field. The first reason being the diversity of the fields of application as well as the diversity of the means used for software tracing. The studies, which are scattered among the different fields of application, use specific terminology. Although the usefulness of notions relating to traceability have been generalized to the various cycles and processes of the software, they are still considered secondary, even accidental. To respond to this design delay, recent studies seek to build a standard terminology together with a generic abstract language to allow the pooling of knowledge developed within the innumerable traceability approaches [5, 6, 7].
Important characteristics of traceability
Our recent contribution builds on top of these attempts to unify core traceability terminology. In particular, we use the results of the conceptualization of traceability work to extract a metamodel based on the common points between them.
To this well-founded basis, we have added a missing and nonetheless important element for the reasoned use of tracing elements: the quality of these. Indeed, trustworthy traceability requires defining quality characteristics for the links. The many approaches dealing with traceability that we know never mention this “quality” and we try to fill this gap with our last contribution.
Let’s discuss more in detail the concerns that we found relevant to build a useful traceability metamodel.
Ubiquitous
Taken from a distance, traceability is a generic means of accessing relevant information enabling the software to be understood. This involves annotating the relationships between the different parts of the software to extract information relating to a specific problem (bug fix, feature extension, change impact, etc.). The idea is applicable to more or less all areas of IT, from design to execution and monitoring, and each area, each study, offers its own language dedicated to the tracing of specific elements.
In a previous work (a Survey-driven Feature Model for Software Traceability Approaches), we automated the search for documents relating to the modeling of traceability in the scientific literature. Out of 159 works, more than twenty propose a particular metamodel to their problems, which, then, are of course of limited applicability to other domains.
Yet scattered
We also noticed that the studies using tracing functionalities hardly ever put forward the term, if not the concept. After selecting the studies mentioning traceability modeling, we built a functionality model to assess the maturity of traceability and look for its strengths and weaknesses. In order to achieve rapid (positive) results in science, the tendency has been to focus on identifying traces – through the use of learning algorithms – instead of constructing a holistic understanding of the field. The race for publications and the craze for deep learning play a detrimental role here in the expansion of the field. Indeed, a significant number of studies automate the identification of specific links between artifacts: from requirements to design, from design to code, from defect notification to fix commit, and so on.
These studies are undertaken in isolation – outside of the context of application of the identified traces. They further exploit irregularities and trends in the nature and shape of artefacts to identify them rather than explore a system’s ability to generate information that can tell about its condition.
Decay of tracing artefacts
Beyond the AI buzz, studies aimed at conceptualizing and standardizing the field have only recently emerged. Gotel and Cleland had launched the specification-only traceability initiative. Antoniol, Heisig, and Maro, et al. propose a metamodel and terminology standard based on existing uses of traceability tools. The main conclusion that emerges from the in-depth investigation of traceability studies is that the quality of the traces is completely overlooked from the equation.
And, more specifically, what quality characteristics are likely to be of interest to tracers?
In the first place, it is necessary to take into consideration:
- the volatility of software systems which makes the maintenance of traces a heavy energy consumer, and
- the pervasive use of non-deterministic algorithms to assist software engineering tasks and in particular the identification of trace links.
Software volatility
Each time an artifact is modified, renamed, moved, deleted, the traces that link it to other artifacts must be updated. The case is particularly clear when one thinks of the trace that links specification documents to design models, and then to source code fragments reflecting their implementation.
When a bug is detected, for example, or when a feature is reviewed to respond to user feedback, the documentation must (!) be updated otherwise the cohesion between the artifacts and their specification will deteriorate. However, we know that this update is late at best, and in most cases completely omitted.
Non-determinist algorithms
A pervasive use of non-deterministic algorithms to assist software engineering tasks makes the results of identifying links between artifacts uncertain, or even in some cases misleading.
Automated identification is limited to assessing the likelihood that a link exists between two artifacts. In this configuration, the links can be derived automatically by means of association rules (this is the case when the nomenclature of Java executables is derived from the name of the classes, for example). They can also be derived through the use of learning algorithms. Thus, the text contained in the record of a commit could (potentially) allow it to be linked to the altered functionality. The potential lies in the combination of precision and recall of the algorithms used, in the non-deterministic nature of their execution, and in the composition of their training data set. The traces thus identified, automatically, have a potential for false positives which must be taken into consideration if the purpose of the tracing is to meet a need for certification or another security variant.
A traceability metamodel with a special focus on quality
If we now imagine the situation where a software module is subject to certification (SPICE, ISO26262) and traces are used to justify the causality of the analysis elements of the software, it is unthinkable to use traces that are “potentially” existing, without precisely defining the level of uncertainty.
It is thus necessary to distinguish the traces obtained following a manual investigation of the software and those obtained automatically from non-deterministic algorithms (AI-based etc.). It is also necessary to assess the degree of cohesion between these traces and the state of the system at the time of analysis. A quantification of the confidence that shall be attached to the traces, together with the justification which allowed this quantification, will make it possible to consider the overall quality of the traceability of a system.
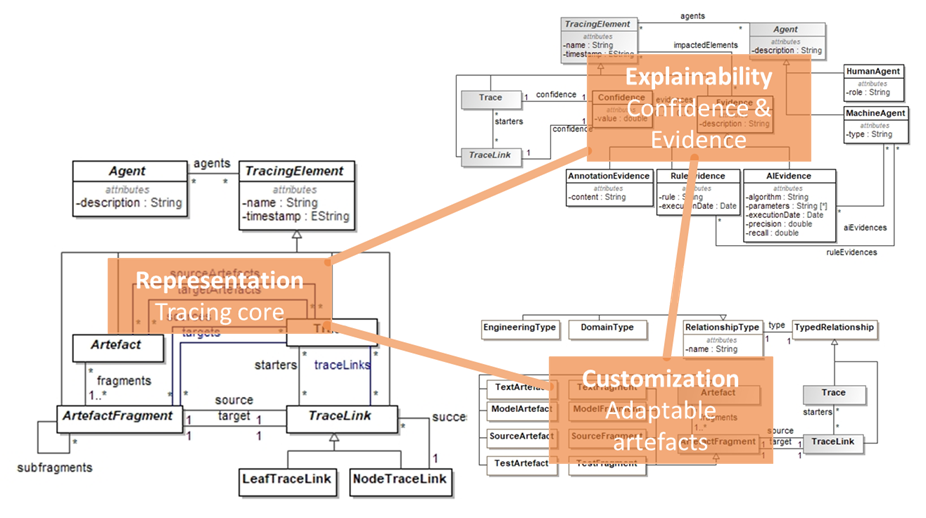
Fig. 1: a modular design for quality traceability: Core representation, Customizable artefacts and links, and Explainable tracing artefacts
As can be seen in Fig. 1, our modular metamodel for traceability, named Tracea, offers to separate conceptually and pragmatically the core structure of traceability, its adaptability to diverse applications, and the quality of traces.
- The first concern, the core structure, allows the representation of traces and links or various provenance and nature.
- The second concern, adaptability, will make it possible to define (or refine) the elements targeted by the tracing. Depending on whether we trace bugs and their resolution, or events and their persistence in the database, the nature and granularity of these artifacts must be adjusted to each project and / or area. The same need applies to the nature of the links that we wish to represent, and which may vary for each area or even for each project.
- Finally, the third and last concern that we have to consider is the quality of the traces with the concepts and attributes as mentioned above: the evaluation of the confidence in the existence of the traces and the elements of justification of this evaluation. The snippet in Fig. 2 shows the detail of our conceptualization of trace quality concerns.
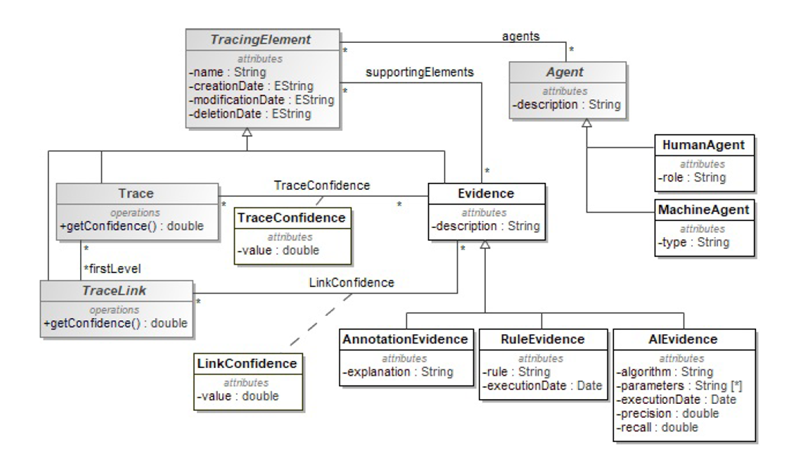
Fig. 2 : The “trustability” of links is quantified to a degree of confidence and supported by evidences. The nature of evidences depends on the means used to identify the links.
Example
The concepts of the metamodel relating to the quality of traces make it possible to answer questions such as: “Which Java classes are impacted by a specific change in the specification?” Or, more precisely, “Which classes are impacted, with a minimum confidence level of 80%, by a particular change in the specification?”
This “80%” confidence level may be based on the accuracy of the identification algorithm, or on the degree of volatility of the elements connected by the links or trace in question. In the first case, it is justified either by the parameters used to learn and execute the identification mechanism. In the second case, the consistency can be (re)evaluated thanks to the impacted elements referenced in the tracing artefacts.
The quantitative evaluation of links allows their rapid (automated) exploration and facilitates access to precise information. An example can be seen in the matrix-based representation of links illustrated in Fig. 3. In our extension to Capra, a threshold is defined below which the color of trace links turns to red. The justification of these values, expressed in terms of configuration elements, makes it possible to ensure their accuracy. Depending on the means used for identification (manual, rule-based, or through a neural model) the parameters vary. Their details allow the identification process to be reproduced and point to those elements of the system that are likely to impact trust values if they were to be changed.
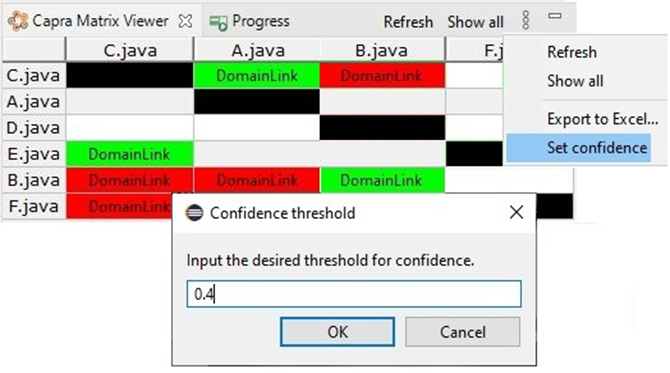
Fig. 3: a matrix-based representation of trace links parameterized with a threshold confidence level.
Integration and tool support
We developed our language thanks to Eclipse technologies. Our first prototype offers the possibility to create and maintain tracing artefacts thanks to a textual representation generated by Xtext. It aligns with the JSON syntax for increased ease of reading for humans while allowing automated processing independent of the target system or language.
In addition to this prototype, we have integrated Tracea in Capra (v0.8.2) [9] to allow visualization of links respecting a certain level of trust, and we are currently working jointly with the SysMLv2 development team to integrate Tracea functionalities into a future release.
References
[1] E. R. Batot, Jordi Cabot, and S. Gérard, “(Not) Yet Another Metamodel for Traceability”, to appear in the Models2021 companion, 2021.
[2] O. C. Z. Gotel and C. W. Finkelstein, “An analysis of the requirements traceability problem,” Proceedings of IEEE International Conference on Requirements Engineering, 1994, pp. 94-101.
[3] O. Gotel and A. Finkelstein, “Contribution structures [Requirements artifacts],” in Proceedings of 1995 IEEE International Symposium on Requirements Engineering (RE’95), 1995, pp. 100-107.
[4] J. Cleland-Huang, O. C. Z. Gotel, J. Huffman Hayes, P. Mäder, and A. Zisman. “Software traceability: Trends and future directions”. In Future of Software Engineering proceedings, 2014, page 55–69.
[5] G. Antoniol, J. Cleland-Huang, J. Huffman Hayes, and M. Vierhauser. “Grand challenges of traceability: The next ten years.” CoRR, abs/1710.03129, 2017.
[6] J. Holtmann, J. -P. Steghöfer, M. Rath and D. Schmelter, “Cutting through the Jungle: Disambiguating Model-based Traceability Terminology,” 2020 IEEE International Requirements Engineering Conference (RE), 2020, pp. 8-19.
[7] S. Maro, J-P Steghofer, E. Knauss, J. Horkoff, R. Kasauli, R. Wohlrab, J. L. Korsgaard, F. Wartenberg, N. Strøm, and R. Alexandersson, “Managing Traceability Information Models: Not Such a Simple Task After All?,” in IEEE Software, vol. 38, no. 5, Sept.-Oct. 2021, pp. 101-109.
[8] Gotel O., J. Cleland-Huang, J. Huffman Hayes, A. Zisman, A. Egyed, P. Grünbacher, A. Dekhtyar, G. Antoniol, J. Maletic, P. Mäder, “Traceability Fundamentals”. In: Cleland-Huang J., Gotel O., Zisman A. (eds) Software and Systems Traceability, 2012.
[9] P. Heisig, J.P. Steghöfer, C. Brink, S. Sachweh, “A generic traceability metamodel for enabling unified end-to-end traceability in software product lines.” In: Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing. 2019, p. 2344–2353.

Edouard is a postdoctoral fellow working in the SOM Research Lab at the Internet Interdisciplinary Institute (IN3) of the Open University of Catalonia (UOC) in Barcelona. His most prominent expertize lies in the use of machine learning to derive complex engineering artefacts by means of usage examples.
Currently working on the conjunct use of AI and MDE for certification traceability purpose, his topics of interest span from software modelling engineering and quality to the social and political consequences of ubiquitous technologies.
You will find Edouard’s complete curriculum here or interact with him by email: ebatot [at] uoc [dot] edu.


Before the 1990, the DAIDA project already provided a traceability metamodel, see http://conceptbase.sourceforge.net/mjf/JJR90-InformationSystems.pdf.
The RE community was well aware of these papers :-/
There are indeed plenty of traceability metamodels. But most of them disregarding all the quality attributes that we believe are important in order to properly use trace information in any kind of analysis.
What is the advantage of having a separate traceability meta-model?
In the Arcadia method as well as in my system modeling meta-models traceability is an integral part of the meta-model.
In my system modeling meta-models in general to rules exist.
* each system artifact has to be traceable to a requirement
* each requirement has to be traceable to a stakeholder
/Carsten
Hi Carsten and thank you for your valuable question.
To my understanding, traceability can be seen as a means to “link” between software elements – any “elements” of interest. These links can take the semantics the user defines and thus step out of what an embedded tracing feature would allow.
Advantages of having a separate metamodel are many-fold.
First, it will allow independence from the system itself and thus allows continuity (of tracing) even if the language of the system evolves, or if its support platform changes. (At the cost of some proxies to bridge the differences.)
Then, a separate traceability metamodel allows to gather information of diverse sources – and potentially not directly of the system itself. It allows artefacts that are not part of the language itself to be integrated in the tracing.
Finally, extracting a metamodel from the existing approaches is always helpful to build a common understanding of the field. Conceptualizing brings a holistic view which later can be reused and improved. Here we see that if the customizability is understood as a salient feature, the quality of traces is not (yet). This metamodel shows some insight on how to tackle these issues.
(I must precise that I consider tracing broadly here, and I do not restrict the concept to tracing requirements to their implementation – and backward.)
Edouard