

Curated collections of models are essential for the success of Machine Learning (ML) and Data Analytics in Model-Driven Engineering (MDE). However, there is still a lack of curated datasets of software models. We believe that there are several reasons for this, including the lack of large collections of good quality models, the difficulty to label models due to the required domain expertise, and the relative immaturity of the application of ML to MDE.
To alleviate this situation, we created ModelSet, which is a dataset of software models intended to help in the application of machine learning techniques to solve modelling tasks. The dataset models have been manually labelled and curated in order to foster research in ML and MDE. The models were extracted from public repositories like GitHub and GenMyModel. Then, they were labelled with their main category and several additional tags. The dataset contains 5,466 Ecore models and 5,120 UML models, and is provided with a set of Java and Python libraries to facilitate its use and illustrate its potential applications.
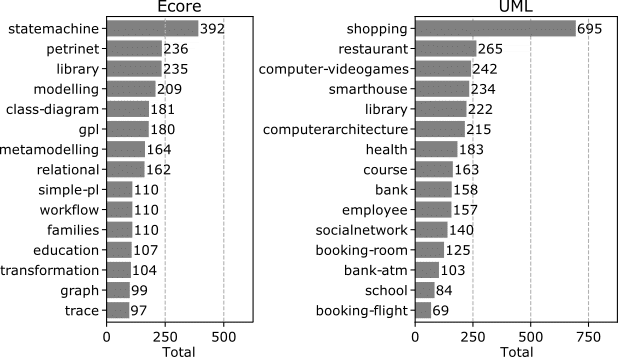
The main label of ModelSet is named category, which represents a type of models sharing a similar application domain. The charts below include the most used categories in the dataset. In addition, ModelSet contains other labels which provide more semantic information. For instance, a model can be labelled with category: statemachine, an additional label with value timed to indicate its variant, and another one teaching to indicate that this particular model is being used for teaching purposes. In total, there are more than 28,000 labels.
With ModelSet, we foresee several potential applications, like
- Classification approaches where labels are the target variables.
- Recommender systems (e.g., suggesting attribute names/types, etc.).
- Evaluation of clustering methods, in which the labels provide the ground truth about the clusters.
- Spurious model identification (i.e., using “dummy” labels).
- Evaluation of ML models via train-test-eval splitting in a stratified fashion using the labels.
- Train embeddings based on labels (i.e., for clone detection using the resulting vector).
- Empirical analysis of the modelling domain.
Of course, we are sure that if you are interested in ML you may also find other interesting areas of application.
To facilitate the implementation of concrete applications we have built a Python library, which provides facilities to load the dataset into Pandas dataframes as well to load the models into several formats like xmi, text (1-gram) and graphs.
You can find more details of ModelSet in this paper (freely available). Also, you can find some usage examples and technical details in this article.

I’m an Associate Professor at UOC and researcher at SOM Research Team, in Barcelona, Spain. My research interests are mainly focused on Model-Driven Engineering (MDE), Domain-Specific Languages and Collaborative Development.


Recent Comments