
Database schemas are a key element in relational database systems. Prior to store data, the structure of that data must be specified in form of a database schema. Schemas not only restrict the structure of stored data, but that also assure that data are correctly read from database applications. However, with a few exceptions, most of NoSQL database systems do not require the definition of schemas. This schemaless nature provides the flexibility required to cope with frequent schema changes, and it is one of the most attractive NoSQL database features for developers.
Not having to define an explicit schema does not mean the absence of a database schema, but that it is implicit to data. Actually, a database is always characterized by the structure of stored data, which can be explicit or implicitly specified. This schemaless feature is not a novelty of NoSQL systems but a property of semi-structured data (e.g. XML or JSON) which are “self-describing” and the definition of a separate schema is not needed. The need (or lack of) to define a database schema is similar to the distinction between static and dynamic typing in programming languages.
Schemaless databases offer some advantages that can result very useful in scenarios where the changes in the data structure are frequent [1]. For example, they facilitate to have custom fields and non-uniform types for database entities, and data with a new structure can be added at any moment without a schema that would impose those restrictions. However, this flexibility should not be obtained at the expense of losing the benefits provided by having schemas.
Developers need to keep in mind the implicit schema when they write (or read) code of applications that manage NoSQL databases. Also, database tools usually require the knowledge of a schema to implement their functionality.
Therefore, the NoSQL schema extraction is increasingly receiving attention from industry and academia, as discussed in [2]. The report “Insights into NoSQL Modeling” (Dataversity, 2015) [3] highlighted that data modeling will be a crucial activity for NoSQL databases and drew attention on the need for NoSQL tools to provide functionality similar to those available for relational databases. In particular, three main types of desired functionalities were identified from the survey carried with data management experts: diagramming, code generation, and metadata management. The report also remarked that schema discovery would be a common task to be implemented to achieve such functionalities.
Schemas for NoSQL Databases
“NoSQL databases” is really used to denote a varied set of database modeling paradigms that are grouped usually in four main types: document, wide column, key-value stores and graph-based databases. The three former types are categorized as “aggregation-oriented paradigms” because the object aggregations are prevalent over connections between objects (i.e. references). More details on this classification can be found in [5].
The notion of schema is well-defined for relational databases. However, NoSQL databases can store several versions or variations of a particular entity. For example, a movie database could have movie and director objects with different structure. Next, we show a movie database example that includes 3 versions for movies objects and 3 versions for director objects. We will use this example to illustrate the schema visualization.

Taking into account that data of the same entity can be stored with different structures (i.e. non-uniform types), we have considered several notions of schema for NoSQL databases:
- Schema object (or object type): it is obtained by replacing, recursively, the atomic values of a semi-structured object (JSON in our case) by an identifier that denotes its type (i.e. String, Number).The schema extraction process analyzes this set of object schemas to discover the set of entities and relationships between them.
- Entity version schema (or simply version schema): it is obtained from the object schema of an entity version by replacing each embedded and referenced objects by the corresponding name of the embedded or target entity version, respectively. These schemas can specify both root (root version schema) and embedded objects (embedded version schema). Next, we show the root version schema for the movie object with _id=”1” (Movie_1, each version is named by the entity name followed by the id number).
{ "title ": "String", "year ": "Number", "genre ": "String", "director_id ": "ref ( Director )", "prizes": "Prize_1", "criticisms ": ["Criticism_1", "Criticism_2"] }
- Entity schema: The set of version schemas of a given entity.
- Entity union schema: It is a view of all the version schemas of an entity. It can be obtained by joining all the properties contained in the version schemas and applying some rules to solve name conflicts. We have applied the following: when a property name appears in more than one version schema and the type differs in some of them, the union type is applied. The union schema for the two movie entities of the movie database example would be the following:
{ "title": "String", "year": "Number", "genre": "String", "director_id": "ref ( Director )", "ratings": "Rating_1", "running_time": "Number", "criticisms": ["Criticism_1","Criticism_2"], "prizes": "Prize_1" }
Discovering NoSQL Schemas
We have implemented a model-driven reverse engineering approach to infer NoSQL schemas for aggregation-oriented systems. The main features of our inference strategy with respect to other proposed approaches (like the JSONDiscoverer) are the following: (i) to extract all the versions or variations of each entity; (ii) to discover all the relationships among the entity versions extracted: aggregation and references; and (iii) consider the scalability and performance of the inference algorithm. Instead of obtaining a succinct, approximate or skeleton schema, we record all the entity versions and relationships between them.
The schema discovery strategy basically consists of the three stages showed in the following figure.
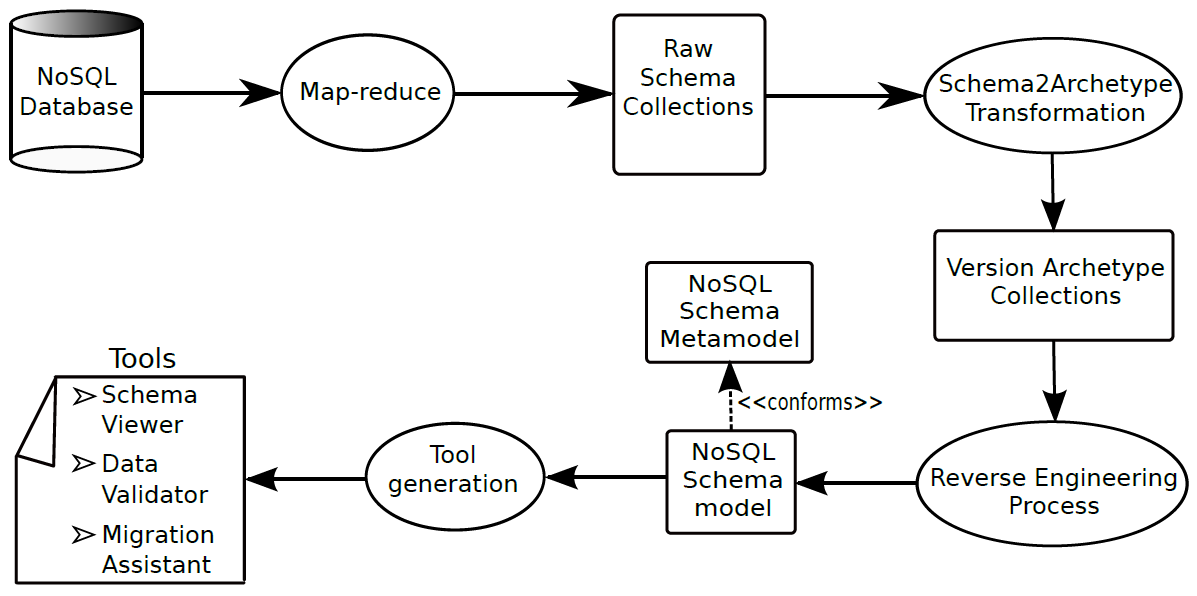
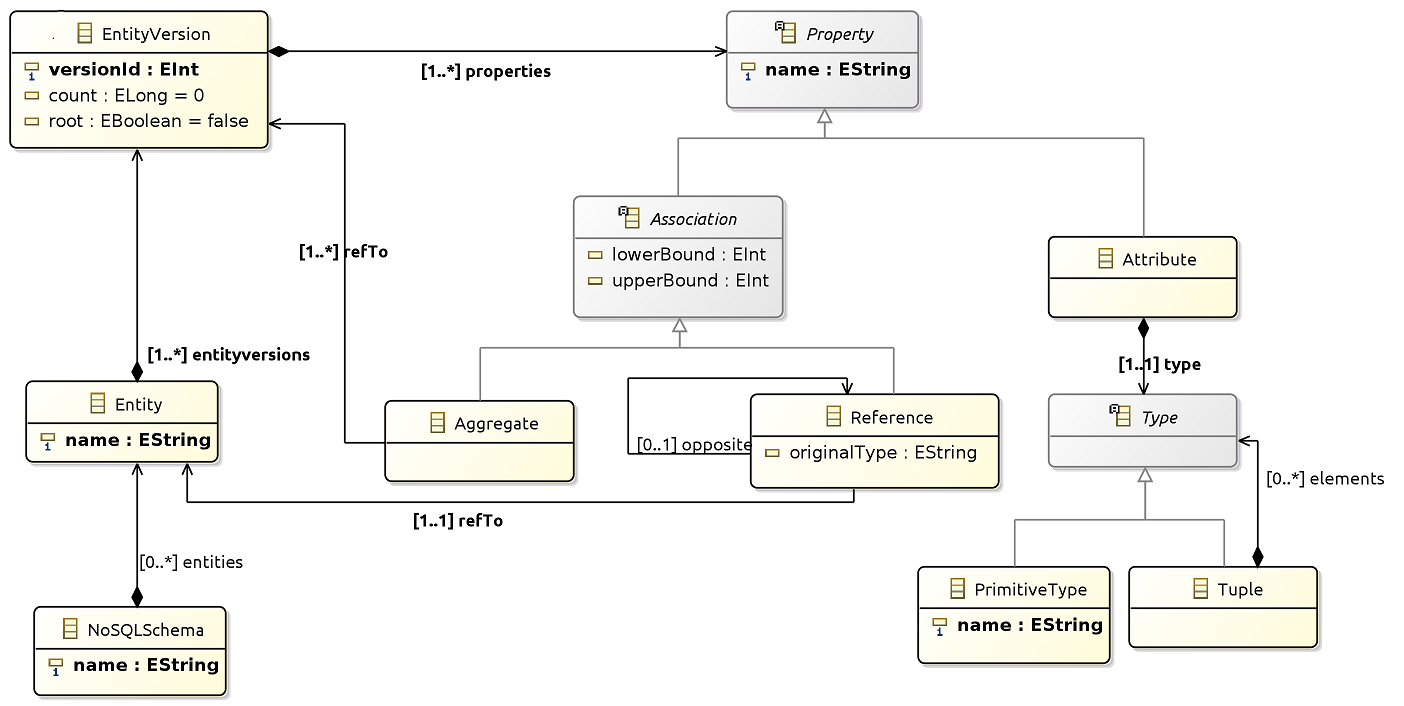
First, a Map-Reduce operation is applied to directly access to the database and obtaining the minimum set of JSON objects needed to apply the inference process. Secondly, the object schema for each JSON object is calculated (version archetypes). Thirdly, these objects versions are analyzed to discover entities and relationships. This information is represented as a model that conforms to the following metamodel.
Visualization of NoSQL Schemas
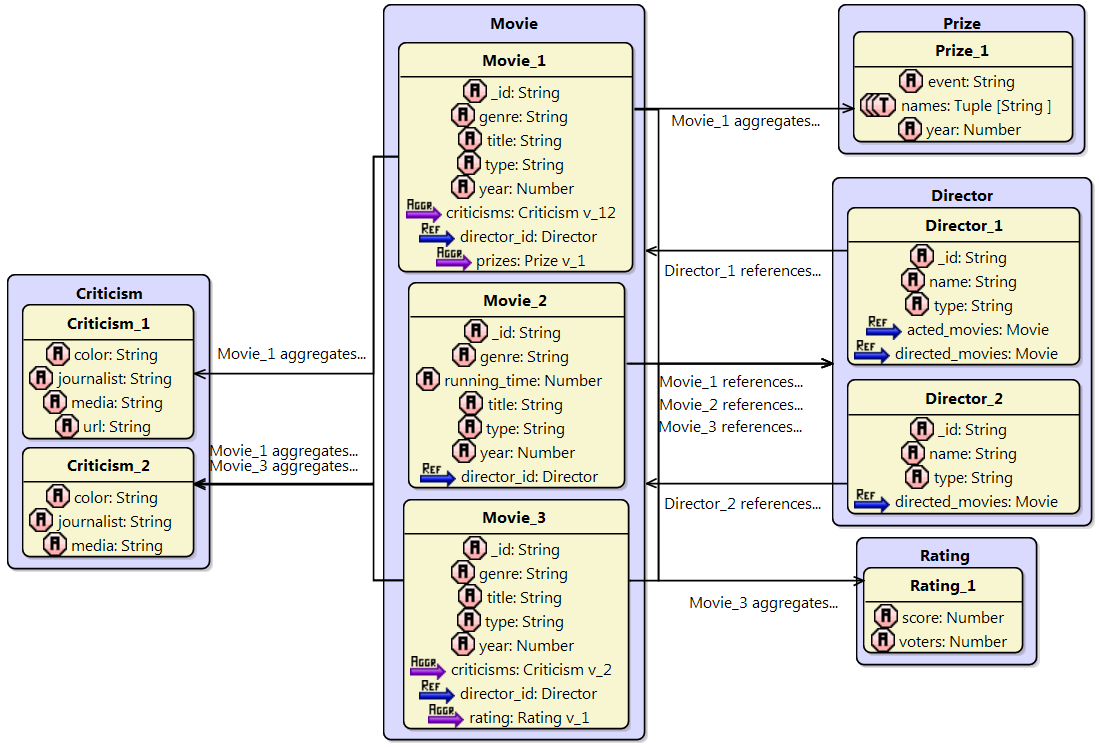
The hierarchical structure of version schemas can be appropriately represented with class diagrams. For example, Movie_3 would be represented by the following diagram:

These diagrams have been obtained by using PlantUML (http://plantuml.com/). A model-to test transformation generates the PlantUML code from the extracted NoSQL model. Each entity version is represented as a class, and a letter within a small circle is used to distinguish the root entities (“R”) from the embedded entity versions (“V”). All the version schemas directly or indirectly nested to the root entity version are shown by means of unidirectional composite relationships whose name and cardinality are the same than the corresponding aggregation elements of the schema model. The letter “E” is used to denote the entities referenced.
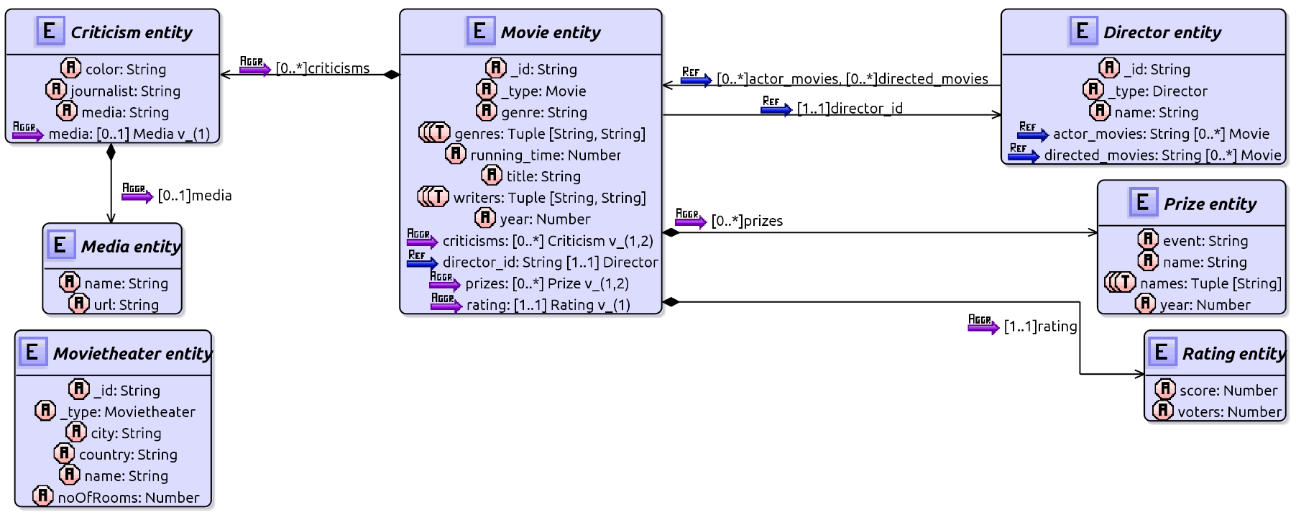
Entity union schemas have also been represented as class diagrams by using PlantUML. When several version schemas have a property with identical name but different type, the union type inferred for this property can only be visualized if it has only two versions: one includes the property with a primitive type (or a tuple) and the other one is a relationship, but the rest of possible unions of types would cause an error in PlantUML. The representation of the Movie union schema would be the following:
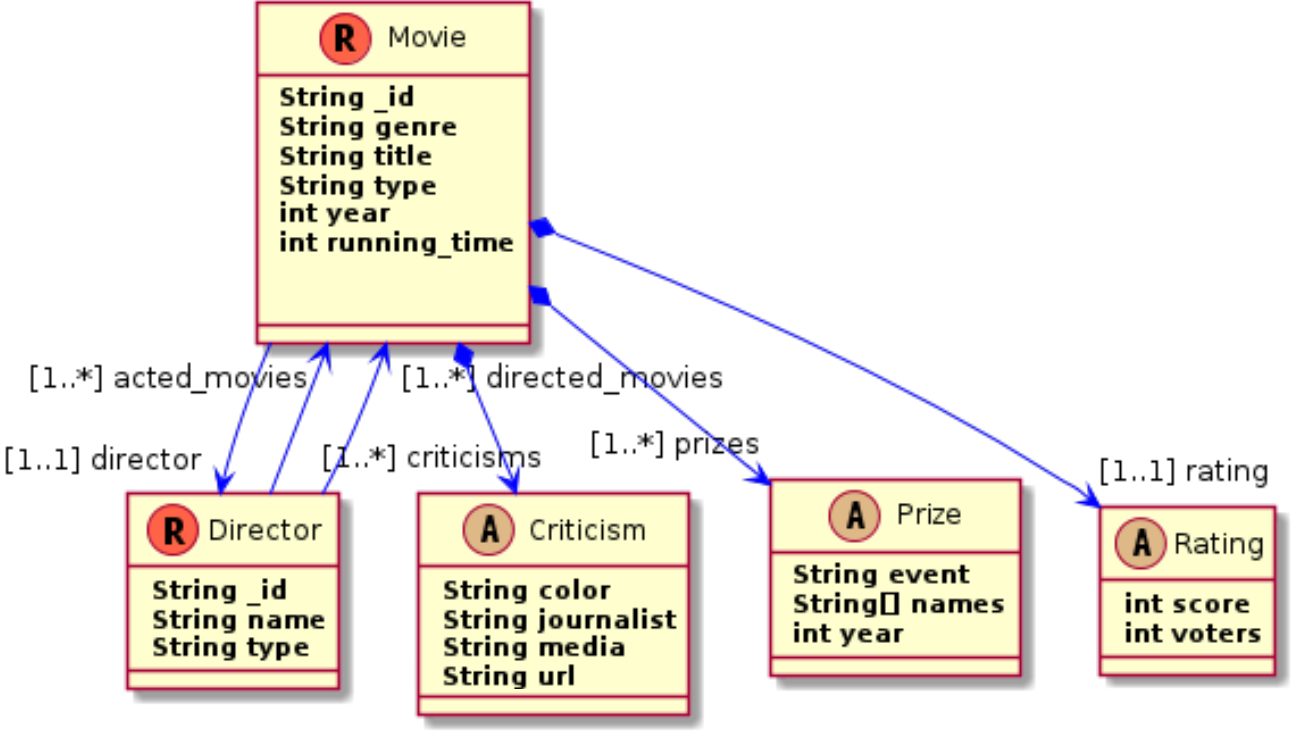
A diagram of the entity database schema is formed by superposing all the diagrams for root union schemas. In our database example, this diagram would be the same as that shown above.
UML class diagrams cannot represent entity schemas or database schemas, and visualizing the rest of schemas has significant limitations. Therefore, we have defined a specific notation to visualize all the kinds of NoSQL considered. We have taken advantage of obtaining a model that conforms to a Ecore metamodel in order to develop our visualization tool. We have used Sirius, a robust and powerful tool aimed to define graphical notations for existing metamodels. Sirius automatically generates an editor and injector from the notation specified by the developer. We have created tree view and diagrams to represent schemas with Sirius. In addition, we have created some browsing and navigation capabilities.
A Global View shows a tree with three branches: Schemas, Inverted Index, and Entities. The global view for our movie database example would be the following:
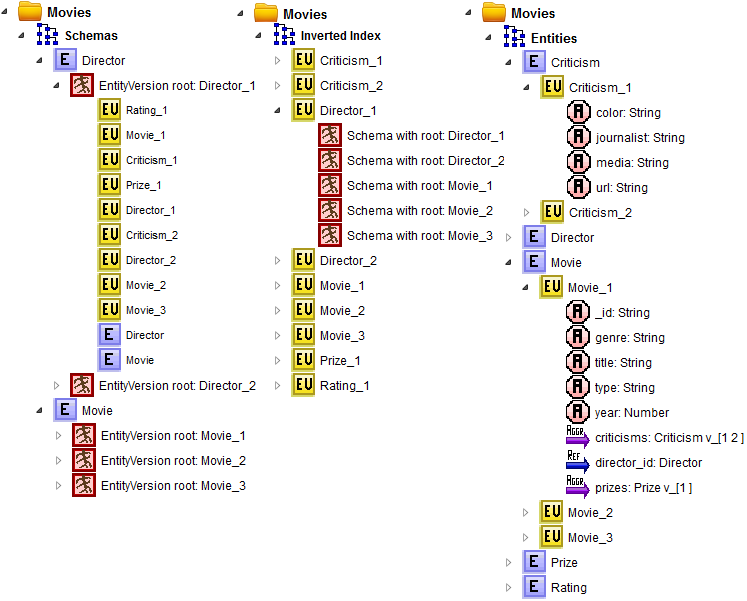
Schemas list all the root entities with their version schema; given a root version schema, the user can browse their embedded and referenced schemas. Inverted Index lists an inverse index of versions and allows to navigate from a root or embedded version schema to all the root version schemas from which it is referenced. Entities list all the entities that exist in the database, and the user can select an entity to display its entity versions, and then he or she can inspect their properties and types. These three branches show, in different form, the information included in the database schema. It is possible to navigate from the Global View Tree to the other diagrams by means of contextual menus.
Next, we show the diagrams defined for entity schemas, database schemas, and union database schemas.

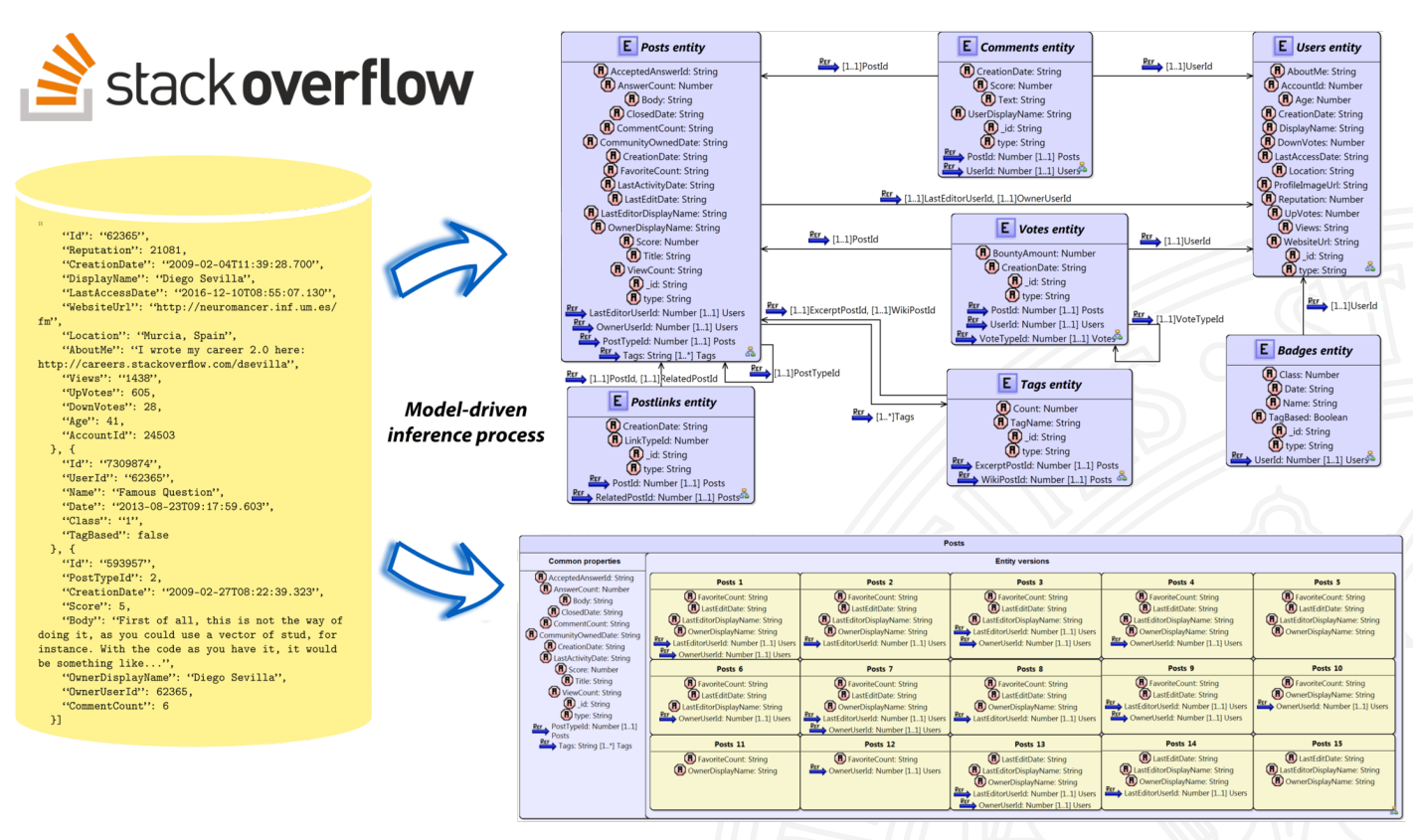
We have validated our tools with several MongoDB datasets that have been generated by injecting open data of sources as Stackoverflow, Facebook, or EveryPolitician. Next, we show the schema obtained for Stackoverflow.
Further information on the schema extraction process and some database utilities developed can be found in [2]. A discussion on the limitations of our approach and some directions for further work can be found in [6]. The schema extraction and schema visualization tooling can be found in the repository https://github.com/catedrasaes-umu/NoSQLDataEngineering/.
The work presented here has been developed by Alberto Hernández, Diego Sevilla, Severino Feliciano and Jesús García-Molina under the Modelum Group and the Cátedra SAES of the University of Murcia.
References
[1] Martin Fowler, https://martinfowler.com/articles/schemaless/
[2] Severino Feliciano, “Inferring NoSQL Data Schemas with Model-Driven Engineering Techniques”, Doctoral Thesis, Murcia University, 2017. (http://hdl.handle.net/10201/53472)
[3] Insights into NoSQL Modeling: A Dataversity Report, 2015. (http://forms.embarcadero.com/2015-Dataversity-Survey-Report?cid=701G0000000tKU2 )
[4] Sevilla Ruiz, D., Feliciano Morales, S., García Molina, J.: Inferring Versioned Schemas from NoSQL Databases and Its Applications. In Proceedings ER 2015, pp. 467–480 (2015).
[5] Sadalage, P., Fowler, M.: NoSQL Distilled. A Brief Guide to the Emerging World of Polyglot Persistence. Addison-Wesley (2012)
[6] Alberto Hernández Chillón, Severino Feliciano Morales, Diego Sevilla, Jesús García Molina: Exploring the Visualization of Schemas for Aggregate-Oriented NoSQL Databases. ER Forum/Demos 2017: 72-85 (http://ceur-ws.org/Vol-1979/paper-11.pdf)


Recent Comments