
The Open Data movement promotes the free distribution of data. More and more companies and governmental organizations are making their data available online, often via Web APIs, which offer powerful means to reuse this data and integrate it with other services. Socrata, CKAN or OData are examples of popular specifications for publishing data via Web APIs.
Nevertheless, querying these Web APIs is time-consuming and requires technical skills that limit the benefits of Open Data movement for the regular citizen. In other contexts, chatbot applications are being increasingly adopted as a direct communication channel between companies and end-users. We believe the same could be true for Open Data. Chatbots are the way to bridge the gap between citizens and Open Data sources. Making sure citizens can benefit from the open data promise is the key goal of our “Open Data for All” project.
We describe here an approach to automatically derive full-fledged chatbots from API-based Open Data sources. Our process relies on a model-based intermediate representation (via UML class diagrams and profiles) to facilitate the customization of the chatbot to be generated. This work is part of the 21st International Conference on Web Engineering (ICWE’21). The work is a collaboration between Hamza Ed-douibi , Javier Luis Cánovas, Gwendal Daniel, myself and Xatkit (as the chatbot platform running the generated open data bots). You can download our model-based chatbot approach for open data preprint or continue reading. for a summary.
Chatbots are the way to bridge the gap between regular citizens and the Open Data sources published by governmental organizations. Click To TweetOverview
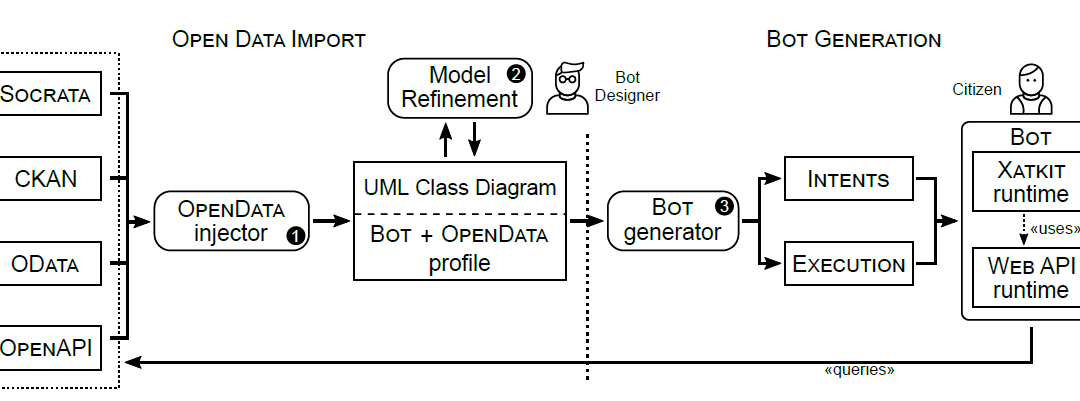
Our proposal is split into two main phases, Open Data Import and Bot Generation.
During the import phase, an Open Data API model is injected (see Open-Data injector) and refined (see Model refinement). The injector supports several input formats (i.e., Socrata, CKAN, OData and OpenAPI) and the result is a unified model representation of the API information (i.e., operations, parameters and data schemas).
Without loss of generality, this inferred API model is expressed as a UML class diagram to represent the API information plus two additional UML profiles:
- The Open Data profile is used to keep track of technical information on the input source (e.g., to be used later on by the Bot to know which API endpoint to call and how).
- The Bot profile is proposed to annotate the model with bot-specific configuration options (e.g., synonyms or visibility filters) allowing for a more flexible chatbot generation. Once the injector finishes, the Bot Designer refines the obtained model using this second profile. During this step, elements of the API can be hidden, their type can be tuned, or synonyms can be provided (so that the chatbot knows better how to match requests to data elements).
The generation phase is in charge of creating the chatbot definition (see Bot Generation). This phase involves specifying both the bot intentions and its response actions. In our scenario, responses involve calling the right Open Data API operation/s, processing the answer, and presenting it back to the user. As bot platform, we use Xatkit [7], a flexible multi-platform (chat)bot development framework, though our proposal is generic enough to be adapted to work with other available chatbot frameworks. Xatkit comprises two main Domain-Specific Languages (DSLs) to define bots: Intent DSL, which defines the user inputs through training sentences, and context parameter extraction rule (see Intents); and Execution DSL, in charge of expressing how the bot should respond to the matched intents (see Execution). If preferred, Xatkit can also work with an internal chatbot Java-based DSL. Xatkit comes with a runtime to interpret and execute the bots’ definitions. The execution engine includes several connectors to interact with external platforms. In the context of this work, we implemented a new runtime in Xatkit to enable communication with Web APIs.
Importing Open Data APIs as Models
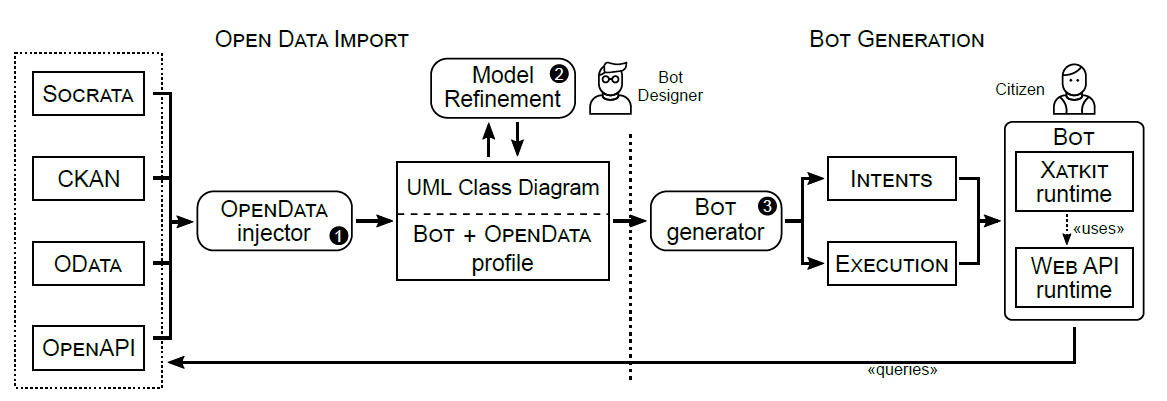
The import phase starts by analyzing the Open Data API description to inject a UML model representing its concepts, properties, and operations. This model is later refined by the bot designer. The injection depends on the two profiles mentioned above and shown in the following figures.
Bot UML Profile

Open Data profile
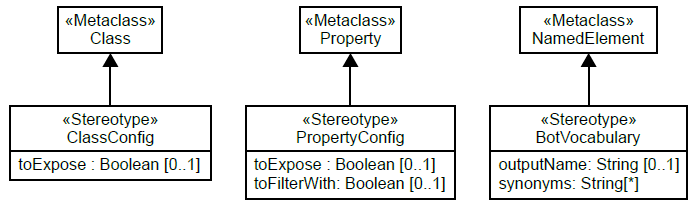
Concepts, properties and operations of Open Data APIs are represented using standard elements of UML structural models (classes, properties and operations, respectively). On top of this basic imported model, the bot profile offers a set of stereotypes to explain:
- the data the chatbot should expose
- how to refer to model elements (instead of the some obscure internal API identifiers), and
- synonyms for model elements that citizens may employ when attempting to alternatively name the concept as part of a sentence
in order to enable more fluent communication between the citizen and the bot. Then, the Open Data profile aims to enrich the model with additional technical details that the generator needs to be aware of in order to ensure proper communication between the bot and the API backend.
Generation of the chatbot for open data
The generation process takes the annotated model as input and derives the corresponding chatbot implementation. As our proposal relies on Xatkit, this process generates the main artifacts required by such platform, specifically:
- Intents definition, which describes the user intentions using training sentences (e.g., the intention to retrieve a specific data point from the data source, or to filter the results), contextual information extraction, and matching conditions; and
- Execution definition, which specifies the chatbot behavior as a set of bindings between user intentions and response actions (e.g., displaying a message to answer a question, or calling an API endpoint to retrieve data). A similar approach could be followed when targeting other chatbot platforms as they all require similar types of input artefact definitions in order to run bots.
The main challenge when generating the chatbot implementation is to provide effective support to drive the conversation. To this aim, it is crucial to identify both the topic/s of the conversation and the aim of the chatbot, which will enable the definition of the conversation path. In our scenario, the topic/s are set by the API domain model (i.e., the vocabulary information embedded in the UML model and the Bot profile annotations) while the aim is to query the API endpoints (relying on the information provided by the OpenData profile).
Our approach supports two conversation modes, direct queries and guided queries.
Direct queries. The most basic communication in a chatbot is when the user directly asks what is needed (e.g., What was the pollution yesterday?). To support this kind of query, we generate intents for each class and attribute in the model enabling users to ask for that specific information. Moreover, we also generate filtering intents that help users choose a certain property as a filter to cope with queries returning too much data.
Guided queries. We call guided queries those interactions where there is an exchange of questions/requests between the chatbot and the user, simulating a more natural Open Data exploration approach. Their implementation requires a clear definition of the possible dialog paths driving the conversation. Next Figure shows an example where the conversation paths start once the user asks for a specific concept available in the API. If the property can be filtered, the path gives the user the option to apply such a filter. This step repeats while there are additional filtering options available.
As input assistance, both direct and guided modes include buttons as short-cuts in the conversation interface.
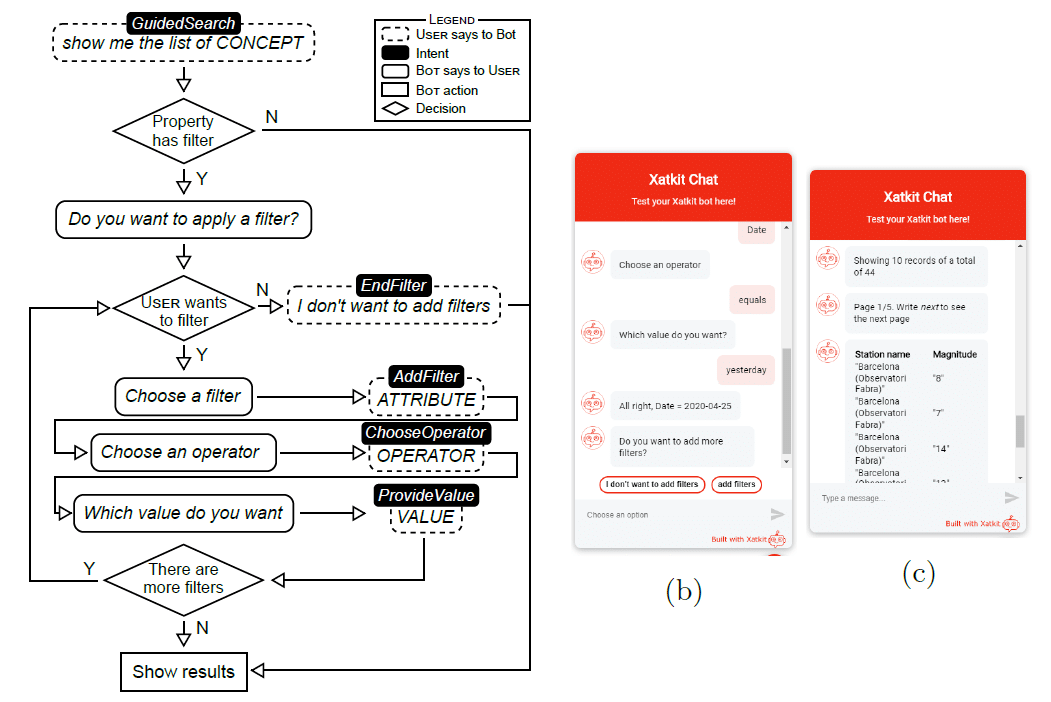
Example of a guided query conversation with the bot
Once the chatbot collects the request (with the possible filters) from the user, the next step is to query the involved Open Data Web API, which relies on the information provided in the OpenData profile.
Further work
As further work, we plan to work on several extensions of this core framework. We mention here three of them (see the paper for more!).
Support for advanced queries. Our approach supports descriptive queries where users navigate the data. However, there are other types of interesting queries; for instance, we could have: (i) diagnostic queries, which focus on the analysis of potential reasons for a fact to happen; (ii) predictive queries, aimed at exploring how a fact may evolve in the future; and (iii) prescriptive ones, which study how to reproduce a fact. We plan to extend our query templates to provide initial support for these types of queries.
Massive chatbot generation for Open Data portals. Our approach works on either individual APIs or a set of interrelated ones (see the point above). We plan to extend our tool support with an automated pipeline able to retrieve and process all available APIs in a given open data portal.
Voice-driven chatbots. The growing adoption of smart assistants emphasizes the need to design chatbots supporting not only text-based conversations but also voice-based interactions. We believe that our chatbot could benefit from such a feature to improve the citizen’s experience further when manipulating Open Data APIs.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Recent Comments