

One way to assess the benefits of model-driven engineering (MDE) is to reimplement popular software with MDE tools and compare the two codebases, the “handwritten” one with the “generated” one. Unfortunately, this is hardly ever done due to the poor cost-benefit ratio for the researchers (plenty of time dedication to reimplement a non-trivial software plus a hard time publishing this kind of empirical studies, IMHO). Today, I’m happy to present one of the exceptions, the work by Sina Madani and our good friend Dimitris Kolovos from the Department of Computer Science, University of York. Read on to learn about their reimplementation of Apache Thrift using the MDE technologies XText and Epsilon (work published at the OCL workshop 2016, full paper available here). Enter Sina and Dimitris.
On Apache Thrift (and why we chose it as target)
Software frameworks such as Apache Thrift and CORBA enable cross-platform client-server model to be implemented with minimal duplication of development effort. This is made possible by the use of an Interface Definition Language (IDL); – a domain-specific language for defining the data and services provided by a server.
These definitions are then used to automatically generate code to enable communication across languages and platforms. Despite most of these technologies being open-source, they are not straightforward to understand or modify; potentially due to the tools and processes used to develop them (e.g. code generation through string concatenation). Perhaps the modifiability and evolvability aspects can – at least partially – explain why there are a number of these frameworks; all with essentially similar objectives. After all, if it’s difficult to modify and adapt an existing framework – perhaps due to the choice of tools, it may be more convenient to build a new framework with the desired constructs and features. On the face of it, these frameworks appear to provide an ideal use case for model-driven engineering technologies.
We therefore set out to investigate whether using a more modern, model-driven implementation and tools can alleviate these issues. We chose Apache Thrift as our focus, since it supports a wide range of languages and has one of, it not the most, complex type system for an IDL. At the core of these frameworks is a domain-specific language, which is then parsed by a “compiler” to produce the appropriate code in the target language(s). Since these IDLs are, by definition, high-level declarations of services, data types and function signatures, intuitively one might expect their “compilers” to be relatively simple. However, the generated code is verbose due to the complex nature of facilitating cross-platform (asynchronous) communication via Remote Procedure Call (RPC). Our model-driven implementation supports two output languages: Java and Ruby.
To make comparisons with the existing implementation easier, we tried to match the output as closely as possible so that in terms of functionality, the two implementations would be (almost) identical from a user’s perspective.
Thrift’s current implementation
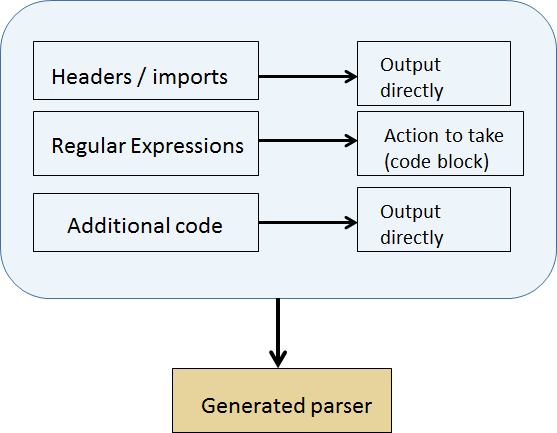
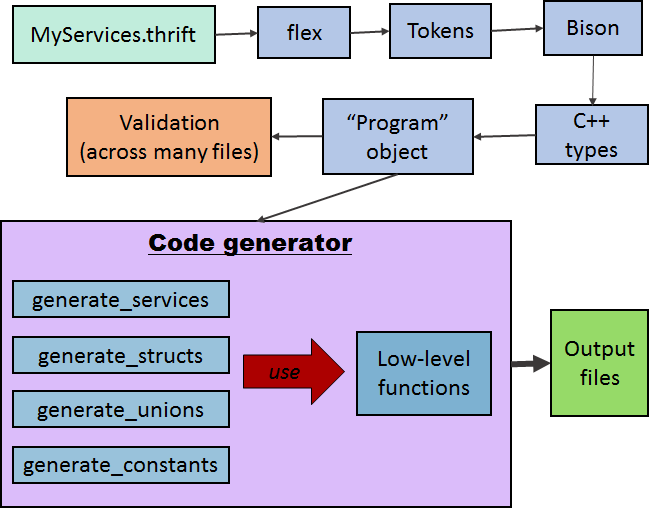
In order to be able to generate output for any language, it is necessary to have a structured in-memory representation (model) of the content of the IDL file. The existing implementation performs this manually using traditional tools: flex for lexing, Bison for parsing and C++ for code generation. These C-based tools require a lot of input from the developer; being imperative by nature. With flex, one defines the “tokens” of the language (such as keywords) using regular expressions. When an expression is matched, an associated block of code is executed. These “tokens” are then fed into Bison – a parser generator – to generate the abstract syntax tree (AST). However, the semantics and datatypes of the IDL are left to the developer to configure.
Consequently, in the existing implementation, constructs such as services, functions, structs and even simple data types each have their own C++ classes, which are manually constructed during the compilation process from Bison. The existing implementation does indeed build a model of the language, but the process is much more complex and verbose than it needs to be due to the choice of tools.
Flex/Bison
C++ compiler architecture
A model-driven implementation of Thrift
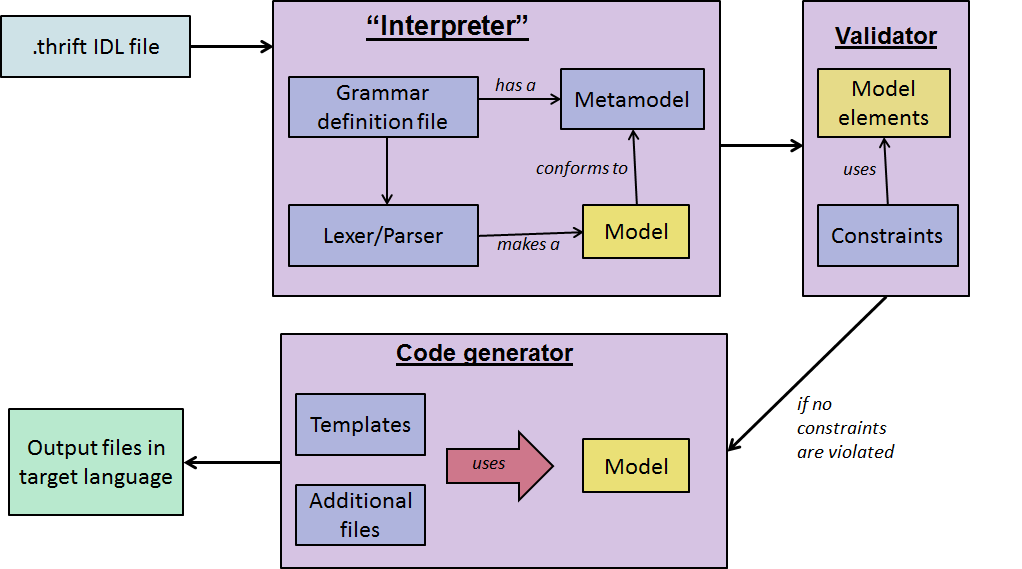
By contrast, our implementation uses Xtext to greatly simplify this process. Xtext is a framework for building and supporting domain-specific languages. At its core is a grammar definition language, which allows the language designer to declare all of the language’s constructs and their relations in a single file using an intuitive EBNF-like notation. From just this file, Xtext can automatically generate the code required to handle all of the low-level lexing and parsing tasks; and even a text editor (with syntax highlighting and error reporting on-the-fly) specifically for the language defined by the grammar file. Once we’ve defined Thrift’s grammar – which was relatively simple, given the availability and Xtext’s simple syntax, we can simply pass in a Thrift IDL file and get back an EMF model. Indeed, Xtext generates an Ecore metamodel for the grammar definition, and can automatically generate an instance which conforms to this metamodel from a given input file.
Model-driven implementation for Thrfit’s compiler
Once we have obtained the model, we can use it in conjunction with other tools (which support EMF models) to perform model management tasks. Naturally, the next step is validation. Although Xtext’s grammar language provides powerful constructs, it cannot enforce complex semantic constraints. For example, we might want to ensure that no two functions have the same name or signature within a given service. For this task, we use the Epsilon Validation Language (EVL). This allows us to express validation rules using a language specifically designed for this purpose. Consequently, the semantics of the IDL can be expressed idiomatically. Furthermore, EVL allows us to define messages for unsatisfied constraints, and even allows for quick fixes to be applied to the model upon encountering a failed constraint.
The final step in the compilation process is code generation. This is effectively a model-to-text transformation, and the Epsilon Generation Language (EGL) provides an ideal solution for such a task. EGL is a template-based language featuring static and dynamic sections. Static sections are output verbatim, and dynamic sections contain code – in this case, Epsilon Object Language (EOL). Using EOL, we can query model elements and use them to generate the appropriate output from EGL templates. Furthermore, these templates can be parameterised and orchestrated using EGX. This allows us to co-ordinate the execution of EGL templates (such as the order and output directories) from a single EGX file, and makes the templates more modular as each template is responsible for generating a given output file. We can also declare constants and perform any pre-processing before executing these templates, so that our model is easier to query for the purposes of code generation. EOL allows us to define extended properties and operations on specific model elements, so such “utility methods” are contained in a separate EOL library file.
Benefits and shortcomings
Quantitatively, we observed a substantial reduction in lines of code compared to the existing implementation for both Java and Ruby. The benefits are especially apparent at the parsing stage – our grammar definition for Thrift’s IDL is around 150 lines of human-readable notation which clearly expresses the language constructs in a declarative manner. Compare that to the more low-level, imperative style of the existing implementation; which has the language’s constructs distributed across many files. With Xtext, we can easily make changes to the language by just updating the grammar definition, and regenerate the (meta-)model. By contrast, making an equivalent change in the existing implementation would require the developer to make changes in multiple places; in flex, Bison and other C++ files used during parsing.
The benefits in terms of validation and code generation are also significant but admittedly less spectacular; this is due to the inherent complexity of the validation logic and the generated code, as opposed to the choice of tools. However, EGL offers a much more readable and modular way to generate code. This is especially true of static sections; where the C++ implementation must manually handle indentation, new lines and numerous calls to the output stream; which arguably hinders readability. Furthermore, the code generation in the C++ implementation is handled by a single file for each language. For example, the Java generator is a single file with over 5000 lines of code and contains over a hundred functions which are used to generate the output files. This is necessary for re-use and conciseness, but means that the reader must constantly be looking at lots of functions at once to deduce the output for a single section of code. By contrast, EGL is arguably better in terms of traceability due to its template-based nature. That said, our architecture also attempts to adhere to the DRY (Don’t Repeat Yourself) principle by using “helper” functions. We use a separate EOL file to perform common tasks (which are cached as attached properties on model elements), such as resolving Thrift’s complex type system. This allows our templates to read similarly to their output files, rather than containing lots of complex dynamic code sections. For such sections, we use a separate EGL file and wrap these in operations, which are then called by the main templates. In such circumstances, the inherent complexity of the code generation logic means there are few, if any, benefits in terms of conciseness and readability over the C++ implementation; since querying model elements becomes no different to accessing properties on objects.
Comparison of the implementations in SLOC and file sizes:
| Stage/Implementation | C++ (existing) | EMF (model-driven) |
|---|---|---|
| Language definition (parsing & validation) | 3419 (105 KB) | 447 (14 KB) |
| Language-agnostic code | 712 (22KB) | 1036 (26 KB) |
| Java generator | 5129 (187 KB) | 2224 (73 KB) |
| Ruby generator | 1231 (40 KB) | 422 (14 KB) |
| Overall total | >10491 (~395 KB) | 4149 (~128 KB) |
Overall, we argue that the main benefits of a model-driven implementation stem from the use of specialised tools. This in turn makes the implementation more cohesive, readable and modifiable. That is, the MDE tools and languages such as Xtext and Epsilon do not contain general-purpose programming concepts and constructs, but in return offer more useful features for their specialised purposes. In other words, they capture the semantics of the problem domain better than general-purpose tools such as C++; which arguably contain more “ceremony“.
Ultimately, it is for the developers and maintainers of a framework to decide the approach and tools are more understandable and easier to work with. Certainly, MDE tools are not without their flaws; namely the lack of comprehensive documentation and the smaller support community compared to more established, general-purpose tools and languages. For reference, our model-driven implementation is available on GitHub, and the official implementation is on Thrift’s website.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Does the XML of the metamodels count in the final loc?