
I see some confusion on the relationship between these three concepts: executable models, code-generation and model interpretation. This was true when I first wrote this post (in 2010). Still true today (in 2023!).
An executable model is a model complete enough to be executable. I’m fully aware that this definition is ambiguos (see the interesting discussion we had in LinkedIn about this issue) but the truth is that the executability of a model depends more on the execution tool we use than on the model itself (e.g. some tools may require a more complete and precise model specification while others may be able to “fill the gaps” and execute more incomplete models).
The most well-known family of executable models are the Executable UML methods (see also the most classic book on this topic). Executable UML models make extensive use of an Action language (kind of imperative pseudocode, see for instance the Alf action language ) to precisely define the behaviour of all class methods. The OMG itself has standardized this notion of Executable UML models, more specifically, the Semantics of a Foundational Subset for Executable UML Models (FUML). Surprisingly enough, the current version of this standard does not include either a definition of what an Executable Model is.
Code-generation and model interpretation are then two different alternative strategies to “implement” execution tools.
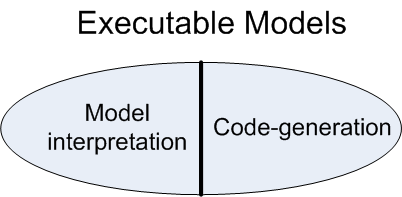
The code-generation strategy involves using a model compiler (many times defined as a model-to-text transformation) to generate a lower-level representation of the model expressed with an existing programming languages and platforms (e.g. Java). Then the generated code can executed as any other program in that target language. Instead, the model interpretation strategy relies on the existence of a virtual machine able to directly read and run the model ( example of a proposal for a UML virtual machine).
Initially, most MDD approaches opted for the code-generation strategy as it is a more straightforward approach. But now most vendors are going for the model interpretation strategy, especially in the low-code domain, where offering this more “easy-to-use-and-deploy” strategy for your models is one of their selling point.
Taking a bird’s-eye view, the benefits and drawbacks of each approach are clear and Johan den Haan already described them for me.
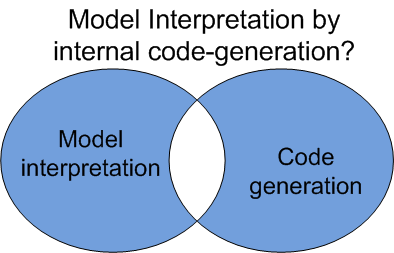
However, often there is no such clear-cut distinction between the two approaches. This is similar to what happens in the programming world with the discussion around compiled and interpreted languages. We see more and more how for the same language we have both options including combinations of them.
For instance, I could imagine a modeling virtual machine implemented using an internal on the fly code generation approach. So, even if the user is not aware of this internal compilation, the virtual machine would be internally “cheating” and disguising itself as a wrapper on top of a code-generation strategy.
In this PhD Thesis work, Evolution of low-code platforms, Michiel Overeem includes the following figure that does a fantastic job in illustrating more mixed alternatives.
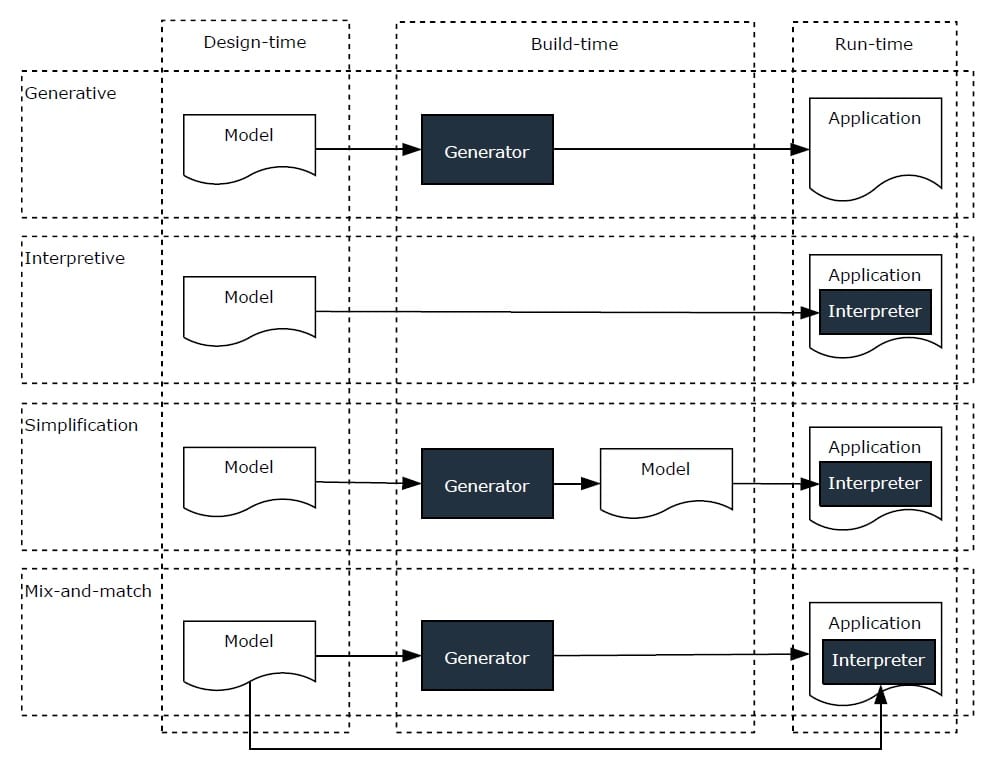
The first two approaches are the “pure” ones commented above. It then covers also two mixed scenarios. In the first mixed one (“simplification”), the model is simplified before being passed over to the virtual machine. This allows us to benefit from an interpretation approach while, at the same time, reducing the cost of building the infrastructure. In the second (“mix-and-match”), parts of the model are generated and others are interpreted.
As hinted in my mixed scenario above, there are even other ways to combine the approaches based on your goals and resources. Let me give you one final example I’ve also seen in practice: a code-generator approach but where the code was heavily depending on a library provided by the same vendor and had no use without that library. In this case, the library is a kind of core component (you could even call it a virtual machine) for the generated code, which more than “real code” is a kind of “configuration code” for the virtual machine offering the core behaviour.
As usual, the key point is to have in mind the pros and cons of each global approach and then decide how to best combine those strengths depending on the constraints of your specific scenario.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Congratulation for the article. But I’m NOT sure about an hybrid approach TO EXECUTE model. Model Interpretation AND Code Generation look LIKE Interpreted AND Compiled Languages. Each one WITH them benefits AND harms.
And I have a doubt about the Executable UML. WHERE IS OCL USING IN this context?
Nice Regards,
Neto
I´m NOT sure about the benefits OF an hybrid approach either, I just wanted TO say that SOME hybrid strategies ARE possible (whether they make sense RIGHT now it IS a different story)
OCL could be AS prominent AS you want. OCL is still important to define the constraints/business rules of the system and could also be used to specify the behavior of the class methods.
The problem is not what we could do with OCL, the problem, as usual, is the tool support. Support for OCL is still quite limited (see this, a little bit old, survey ). This is even worse when looking at OCL support in code-generation or model interpretation tools.
A little history:
The first complete action metamodel and semantics for UML were incorporated into the UML 1.5 standard, the last version of UML 1. At the time, the action semantics submission team took some pains to ensure that the syntax of OCL 1 could be mapped into the action metamodel and that the semantics would be largely consistent with those then defined for OCL. The hope was that this could eventually provide the basis for a normative metamodel mapping for OCL, unifying the OCL expression language with the rest of UML.
However, the OCL 2 submission team decided not to take this approach. Instead, they decided to create a specialized metamodel for OCL as an extension of UML expression abstract syntax metamodel and define its semantics as a constraint language separately from any of the behavioral modeling constructs already in UML. And, unfortunately, the tool support for the resulting OCL specification has been largely non-existant (other than a growing amount of parsing and basic static checking support in some UML tools).
In the meantime, the UML 2 submission team (which was largely separate from the OCL 2 team) did a major revision of the UML activity metamodel, integrating it with an action metamodel strongly influenced by what was in UML 1.5. The precise execution semantics of the Foundation UML (fUML) standard mentioned by Jordi is based on this UML 2 activity/action metamodel, and the Alf submission to the OMG action language RFP is based on fUML.
Now, one possible response to the action language RFP would have been to propose an imperative extension to OCL syntax and map that to fUML (as required by the RFP). In fact, the OMG MOF Query-View-Transformation (QVT) standard already provides an imperative extension to OCL as part of its operational mapping (though this is not further mapped in the QVT standard to the UML action metamodel).
However, there was a strong feeling on the Alf submission team that the OCL syntax had not succeeding in becoming “mainstream”, that there were no successful commercial UML action languages based on it and that several existing UML execution tools just used C++ or Java as their action language, so the community was familiar with that traditional syntax. As a result, Alf has a Java/C++/C-legacy syntax, rather than being generally OCL-like, though an OCL-like “arrow” syntax was adopted for data-flow/collection operations. There is actually a discussion of the relationship of Alf to OCL in the introductory section of the current draft spec that might be of interest (available through the link Jordi gave).
So what is “Executable UML”? Well, from the emerging standards viewpoint at OMG, I personally would say that “Executable UML” is the ability to program completely in UML, using the precise execution semantics of the fUML subset and the Alf action language.
Thanks for a very clear article that solidifies the relationships between some often-used terms.
I think caching can be considered the mixed strategy. The model is interpreted according to the inputs that come in, but the generated behaviour (code/workflow/algorithms/…) can be cached such that if the same inputs come in, the cached response can be then used instead of going back to the model.
This can be taken further by trackoing the inputs that come, and on updating the model, pre-caching the responses for the more popular requests, in a compilation-like step. Is this compilation or interpretation? To me, it’s still interpretation because the USER interaction drives what IS cached (OR pre-cached) instead OF a design-TIME decision.
But I also think that model interpretation IS MORE conducive TO a declarative approach while code generation works better FOR an imperative approach (ACTION languages AND whatnot). IN this sense, the caching can be seen AS a bridge BETWEEN the two worlds that replaces design-TIME decisions WITH run-TIME ones.
Specially the `little history` about the UML, execution environments, and OCL.
I did this question cause some years ago, I head so much people talking about `OCL could be the future to UML Executable`. And I did not agree with this idea because I thought OCL ambiguous, and a hard syntax for commercial use (among others reasons). And in one occasion, I either told that OCL will be forgot as many others proposes because will not exist tools to support it at all (maybe it can be concrete).
So now, as I could see, the new hot point in executable UML are action semantics and Alf.
Congratulations for the portal.
Best Regards,
Neto
Just wrote a post on this:
http://abstratt.com/blog/2010/08/07/model-interpretation-vs-code-generation-both/
The gist: even if you choose code generation for producing the application, model interpretation provides a more natural way for developing the models themselves.
Feedback welcome. Cheers,
Rafael
Another great post jordi. Good description of the differences between executable models, code-generation and model interpretation.
I believe the key issue or challenge with process modeling is the unfamiliarity of most business users and even analysts with how to do this and also the lack of availability of easy-to-use tools that are better than just using Visio or PowerPoint.
Our team has been using the AccuProcess Modeler in the recent months and have found this to be a great tool which anyone can use without a lot of formal training. It includes process modeling, documentation and even process simulation for the as-is and to-be processes. It is available at: http://www.accuprocess.com
Thanks.
Good points everybody.
Jordi, another OPTION that could reduce the gap BETWEEN code generation AND model interpretation IS TO go towards a “lightweight” code generation approach. FOR instance, IN our toolsuite (WebRatio, http://www.webratio.com, a MDD tool supporting the DSLs BPMN FOR business processes AND WebML FOR web application design) we generate the code but ONLY IN terms OF XML descriptors OF generic Java components that we develop AND deploy once AND FOR ALL [1]. This definitely makes the “code” generation simpler, since you don’t really generate code but something more close to an efficient representation of a piece of the model (and btw allows for quick lookup of the generated artifacts). And one could even imagine the generic components as very small model interpreters that interpret the XML descriptors at runtime.
Jordi, I would put this scenario in the intersection between the two sets in your last picture (although possibly a little bit more on the code generation side).
[1] For more details see our paper at Tools 2008: R. Acerbis, A. Bongio, M. Brambilla, S. Butti, S. Ceri, P. Fraternali. Web applications design and development with WebML and WebRatio 5.0 , TOOLS Europe 2008, Switzerland. Springer LNBIP Volume 11, ISBN 978-3-540-69823-4, pp. 392-411.
I think we are caught up in the abstract when we need to get tools down to programmers, rather than higher level workers. There are many ways to go about model to code transformations. I think one of the reasons why interpreters are appealing, is because we can update the “model” on the fly and correct problems. But is that the problem we are trying to solve?
This is really a question of expressiveness. If we write code that would be better represented in a model. Then we could use any tool that would allow us to make such representation. A personal benefit I see in generation. Is that the generated code can be made much easier to read, unit test and debug than the generator tool. I personally have migrated an entire accounting system with my own automatic migration tools, and I can say that stepping through a debugger is not always fun.
Hello,
let me point to another blog’s post ON this, WHERE you can see an ideal continuation OF the discussion:
http://blog.webratio.com/2011/05/16/why-code-generation-IS-better-than-model-interpretation-FROM-our-customers%e2%80%99-point-OF-VIEW/
Marco
I’m glad you are raising this issue. The Enso project is exploring 100% interpreted approach, and it works very well. http://enso-lang.org/
But my main point is that if you are interested in this topic, you should definitely study Partial Evaluation, because it is a very effective way to *turn an interpreter into a compiler*. Yes, it sounds like magic, but it actually works. I’ve done some work on this too:
http://www.cs.utexas.edu/~wcook/publications.htm#mod
http://www.cs.utexas.edu/~wcook/Civet/
I suppose I should add a reference to the standard textbook on Partial Evaluation, which is
free online:
Partial Evaluation and Automatic Program Generation.
N.D. Jones, C.K. Gomard, and P. Sestoft
With chapters by L.O. Andersen and T. Mogensen.
Prentice Hall International, June 1993. xii + 415 pages. ISBN 0-13-020249-5.