
Modeling and version control both play key roles in industrial-scale software development. Despite some attempts to integrate the two, most modeling tools and version control systems fail to play nicely together. Anyone who has tried merging model files knows what a nightmare it can be. Others curse the modeling tools that lock them out while another user edits.
With multiple developers interacting on a large project, it’s generally not feasible to divide the system into isolated modules, one for each developer. We thus have to cope with integrating the work of several simultaneous developers on a single module. It isn’t acceptable to lock all other developers out while one works on the module. Nor is it efficient for developers to have to use manual processes to resolve merge conflicts, nor waste time debugging problems caused by imperfect merges. Yet equally we need multiple developers in order to meet our deadlines, and we need versioning in order to be able to record what we have shipped, and to see what has changed as an aid to documentation, bug hunting and impact analysis.
The ideal solution would be to bring the benefits of version control to models, without ever requiring a merge or locking users out. Users would work on a consistent, up-to-date view of the models, and could commit a set of changes to make it available to others. They could examine the changes they have made, with the freedom to view them in whatever format seems most appropriate: graphically, textually, as a tree. They could write a version comment for the changes and release them to others as a new version. The process for versioning would be low-ceremony: ideally a single click would suffice. The versions could be stored in any major version control system: a local Git repository, a team’s SVN, on GitHub, Bitbucket etc. Users could inspect and compare versions to see other users’ changes or older states, both within the modeling tool or using the version control system’s own functions.
That’s the vision, then. How hard can it be? 🙂 [TLDR: skip to the video at the end!]
Contents
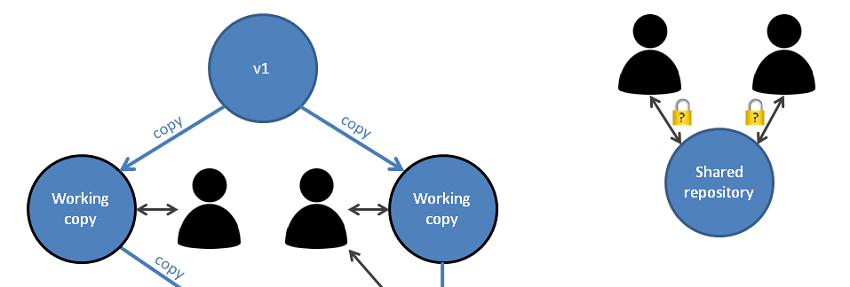
It turns out there are two different ways to approach the problem of multiple users. The first way gives each user their own copy of the entire set of files and allows any changes, with the first user to version getting a ”free ride”, and others having to merge their changes into that version after the fact. The second way allows users to work on the same set of models, with fine granularity locks to prevent conflicting changes yet allow multiple users’ work to be continuously integrated as they save it.
1.1 Clone: merge after the fact
The first way has its origins in the management of simple textual source code files. Rather than the editor tool handling collaboration, that responsibility is deferred to the version control system. In today’s modeling tools, the first way is seen in approaches like EMFCompare.
The file-based approach of EMF Compare is easy to explain: model files are treated like source code files, so all the normal operations of EGit or similar are available – but also required. The simplest EMF Compare + EGit integration I have seen is in a video by Philip Langer for EclipseSource, https://youtu.be/NSCfYAukYgk. Even there, versioning with a single simple conflict requires a long sequence of operations: ”branch + checkout, save, add + commit, checkout, pull, merge, resolve conflicts, save, add, commit, push”. Even without a conflict, the sequence is ”branch + checkout, save, add + commit, checkout, pull, merge + commit, push”: all manual operations which the user has to remember and find within the various menus of Eclipse.
Is this complexity essential, or could another way show it to be accidental complexity, introduced by applying tools and methods designed for simple text files to the rather different world of models? Indeed, could the more structured nature of models actually help us avoid the need for this complexity?
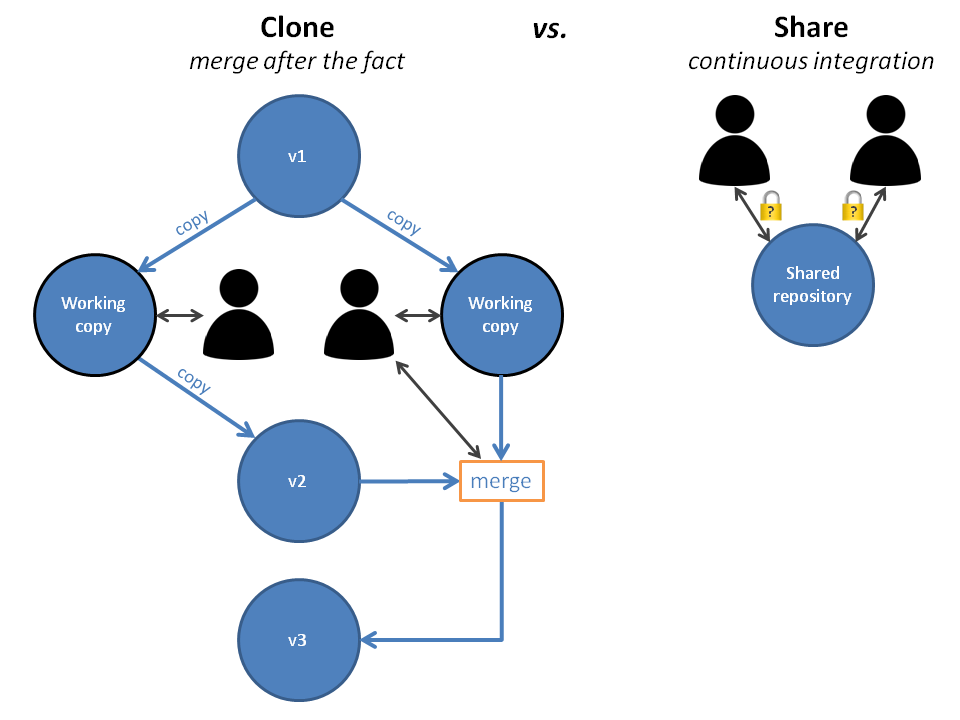
Figure 1. Two ways to collaborate: Clone vs Share
The second way has its origins in the richer structures of databases. In today’s modeling tools, the second way is seen in MetaEdit+ or the commercial version of Obeo Designer. The basics of the approach are similar between the tools, but here we’ll discuss the approach taken in MetaEdit+, which perhaps adds a few useful twists.
Figure 2 shows the architecture of multi-user MetaEdit+ [1, 2]. The heart of the multi-user environment is the Object Repository, a database running on a central server. All information in MetaEdit+ is stored in the Object Repository, including modelling languages, diagrams, objects, properties, and even font selections.

Figure 2. MetaEdit+ multi-user architecture.
The Object Repository itself is designed to be mostly invisible to users. The use of the repository is visible only when a user starts or exits MetaEdit+, opens or closes projects, and commits or abandons transactions. Objects are loaded as needed and cached by clients when read, and thus are only read once per session over the network: performance after that initial read is identical to normal objects. Because of the JIT loading of objects, and no need to parse XML, performance of opening a model compares favorably with XML-based tools [3], particularly for large models.
Fine granularity locks ensure no conflicts, while letting users work closely together in parallel. Making a change automatically takes a fine granularity lock, down to the level of a single property, preventing conflicts without preventing users working closely together. When a user has finished making a coherent set of changes, he can commit and his changes are then automatically available to other clients, with no need for manual integration, merge, pull etc. This guarantees consistent and up to date information to the whole team.
An extra layer of consistency is familiar from ACID rules for database transactions: during a transaction, users see a consistent view of the repository as it was at the start of their transaction. This gives the ease of Google Docs multi-user editing, without the distraction of others’ half-finished changes happening before your eyes.
2. Examining what has changed
MetaEdit+ has supported multi-user collaboration with continuous integration since 1996. However, support for showing changes, versioning, and integration with external Version Control Systems has been slower to come. We will deal with showing changes here, and cover version control integration in the next section.
2.1 View modeling changes as a tree
The Changes & Versions Tool shows what changes users have made, helping them document the version history of their models. The history is shown as a tree with Versions at the top level, containing that user’s Transactions, containing Graphs and Objects that changed in that transaction.
By default the tree shows only the current Working Version of the current user, but ‘Show all versions’ broadens this to previous versions and all users. Users can choose ‘Ignore representations’, so simple graphical rearrangements of diagram elements do not clutter the display.

Figure 3. Changes & Versions Tool, showing changes as a tree
Color and symbols are used to highlight specific types of change: green for new, red for deleted, black for changed, and gray for elements that are not themselves changed, but which are parents for changed elements.
2.2 Graphical comparison to highlight changes
For a selected graph version in the Changes tree, ‘Open’ will open the current diagram and highlight the elements changed in that version.
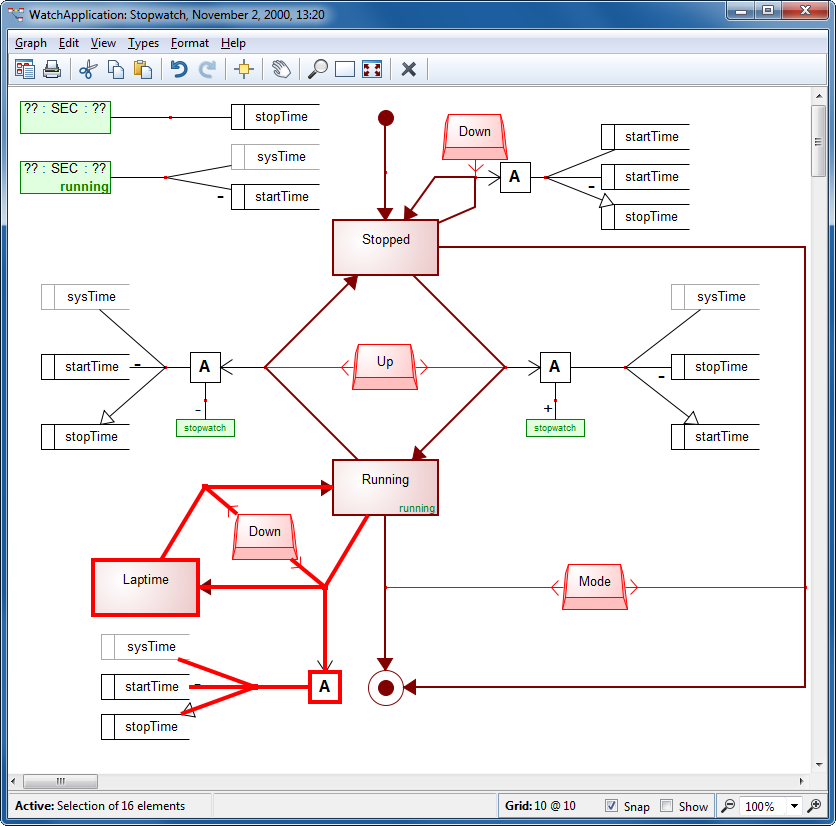
Figure 4. Highlighting model changes graphically.
For many cases, this highlighting gives a quick, intuitive, graphical overview of what has changed, shown in the context of the current state of the model. For the full details, users can use the tree or textual Compare.
2.3 Textual comparison with model links
From the Changes tree, users can choose ‘Compare’ to diff the selected Version, Transaction or Graph with its predecessor. This will open a text comparison of the selected state with its previous state. The text elements have Live Code hyperlinks, so double-clicking a link will open that element in its current context in the model.
The text lists the graph, its objects and relationships, together with all their details and links to any subgraphs. This approach is intended as a good compromise between coverage and readability, and can be customized where necessary: domain-specific diff.
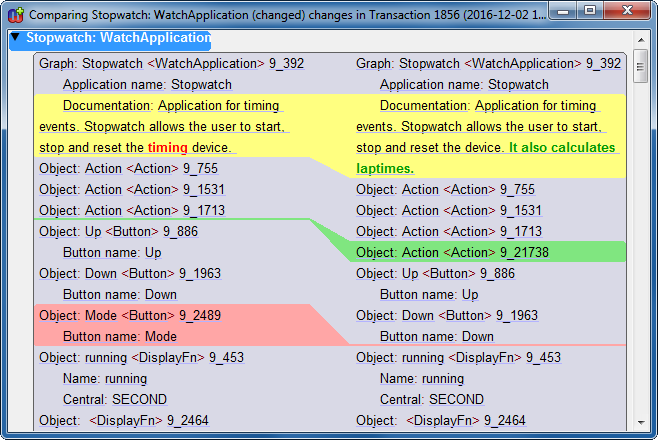
Figure 5. Showing model changes textually.
When comparing a Version, the comparison is to the previous Version, hence multiple graphs across multiple transactions. Rather than show each graph many times, each time with just the changes made in a single transaction, the changes will be combined and shown from the initial state to the final state. Only if other users have committed transactions interleaved with this user’s, those changes will be filtered out of this user’s view by splitting into more than one textual comparison. Each change is thus shown once, in the Version of the user who made it, and can thus be documented once, without the confusion of interleaved changes made by others being highlighted too.
3. Version Control System integration
Whereas the “clone” approach to collaboration gives rise to versions as a welcome side-effect, the “share” approach does not itself create versions. MetaEdit+ supports integration with Version Control Systems using its API command-line operations and MERL (the MetaEdit+ Reporting Language, in which generators are written). The VCS operations are invoked from the Changes & Versions Tool, and use generators to call the necessary commands. Full implementations with generators for Git and TortoiseSVN integration are included for Windows, and users can build on these to add support for other VCSs or platforms.
Before looking at the details, let’s take a step back to consider the role of VCSs in software development, and in modeling in particular.
From humble beginnings as simple text file archivers, Version Control Systems have grown to play a key role in software development. Modern VCS functionality handles three main tasks:
- Archive: maintain older versions and allowing developers to return to them
- Collaboration: integrate the work of multiple developers
- Branching: handle long term parallel variants.
VCS support for collaboration and branching is based on (semi-) automated merging of text files. Despite much research, automated merging of model files has proved less than ideal. Approaches that worked on simple text files struggle with the more complex and strongly interlinked model data.
MetaEdit+ thus provides its own solutions for collaboration and branching, and for the core use cases these work better for models than VCS merging does for text:
- Collaboration is handled by the multi-user version, as described above
- Branching is handled in the modeling languages, using principles from Product Line Engineering: rather than copy a file wholesale to make a small change, have a language that specifies the variability or differences from a core model.
The role of a VCS in modeling thus returns to its original core function: archiving versions along with human-readable documentation of their changes. The change highlighting and Compare functions of the Changes & Versions Tool already help the user in documenting changes and exploring them later from within MetaEdit+. To add the ability to return to an earlier version of the repository, or open the latest or an earlier version on another PC, we leverage existing external VCS functionality, integrated with MetaEdit+ via MetaEdit+ API command-line operations and MERL.
3.1 What to version and how
A user can make changes and commit in one or more transactions, and when ready to version, can press ‘Save Version’ in the Changes & Versions Tool. The VCS integration puts the current state into the VCS working directory, and makes a VCS version from there.
The VCS working directory is kept separate from the MetaEdit+ directory, because VCSs cannot work sensibly with a live set of database files. MetaEdit+ copies the repository into the VCS working directory. It also writes the current textual snapshots of each graph and the metamodel. These textual files add about 10% to the initial size, but as only small parts change in subsequent versions, the ongoing increase is significantly less. The improvement in the ability to compare versions within the VCS itself is well worth it. The VCS working directory contains the textual snapshots of the graphs, a metamodel subdirectory containing the generators and metamodel snapshot (useful for diffing during language evolution), and a versionedDB subdirectory containing the MetaEdit+ repository files.
The standard way of using command-line VCSs – manually change a file, and in a separate command manually tell the VCS that the file has changed – is not necessary in a situation where a tool can guarantee that what is in the working directory is the exact state of the next version. Only a few VCS commands are thus needed, and MetaEdit+ will handle calling them. The commands are specified in a few MERL generators called by the various phases of the Save Version action. The bulk of the generators are for any VCS, with the differences isolated into generators with a suffix for the VCS name when necessary – e.g. _vcsCheckIn_git() checks in the current working directory contents, adding and committing them locally, and syncing and pushing them to a remote Git repository if one is defined.
Having the commands in MERL generators allows users to add integration for new VCSs, and to tweak existing integration if necessary. For instance, the default integration follows most customers’ wishes in not including source code generated from the models, but if a particular customer wanted that, adding it for all VCSs would be a single line in the generic _vcsCheckIn() generator. Another customer might choose to generate source code into a separate VCS repository.
Creating a version starts by emptying the working directory, allowing us to avoid old files being left when graphs etc. have been deleted. The contents of the working directory are thus exactly what we want in the next version, with no conflicts or merges necessary. In the multi-user version, we want this new version to succeed the latest version in VCS, not the previous version made by this user: the multi-user repository commit already makes sure we have all the other users’ changes.
Since the MetaEdit+ multi-user server already integrates the work of multiple users, versioning in a multi-user environment is as easy as with a single user. No need to fetch others’ changes and deal with diff, merge and conflicts: one click is enough to publish as the next version in a single, consistent trunk.
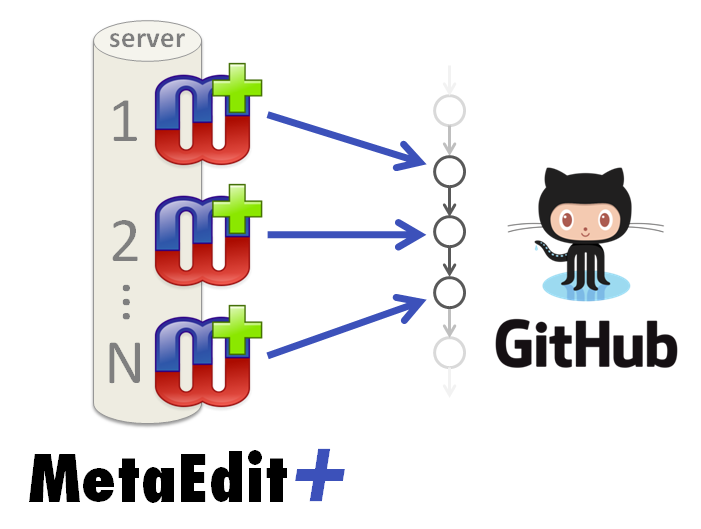
Figure 6. Multi-user repository integrated with external version control system.
3.2 Comparison with versioning at Google
But can an approach based on a single trunk really work at scale, even if it is helped by a modeling tool server? Evidence from what is probably the largest code repository in the world shows it can, and arguably even better than a versioning process with higher ceremony and complexity.
Google uses single trunk-based development in one monolithic repository with 1 billion files and tens of thousands of users [4]. They change 15 million lines of code per week – equivalent to the total size of the Linux kernel. As with MetaEdit+, all normal work takes place on a single trunk, at its head. Use of long-lived branches with parallel development on the branch and mainline is exceedingly rare. Releases are marked as branches, with some bug fixes later cherry-picked into them from the trunk. (If a MetaEdit+ user has chosen to version generated source code for releases, a similar cherry-picking approach can be used to back-port a change on the modeling trunk to a current code release. In this way, a single trunk for model versions can co-exist alongside a GitFlow approach for code.)
Where there is a need for different behavior of variants, Google’s approach is similar to the MetaEdit+ Product Line Engineering approach: rather than branching, include both behaviors and use configuration. “[Different] code paths commonly exist simultaneously, controlled through the use of conditional flags. This technique avoids the need for a development branch and makes it easy to turn on and off features through configuration updates.” Generation allows MetaEdit+ to add an extra level of flexibility: the variation point can be realized at generation time, not just compilation time or runtime. This results in smaller, simpler, faster code for each variant — useful for cases like JavaScript on a busy website or an Internet of Things device.
4. Conclusion — and video!
Maybe you’ve been waiting for years for a way to collaborate on models and include them in your version control system. You have welcomed improvements in ways to compare models, but perhaps always felt that there still could be a better way. Maybe you’ve even worked as a researcher, battling the difficulties of XML and the intricacies of IDEs to push things forwards.
The approach shown here is quite different, but then so perhaps are the results. We have found it to be simpler and more scalable: definitely worth a look. But rather than tell you more, we can show you: watch the video, compare with how you do it today (or the Eclipse video from above), and let us know what you think.
5. References
1 Steven Kelly: CASE tool support for co-operative work in information system design. Information Systems in the WWW Environment, 1998, pp. 49–69 (Ch 5 here)
2 Steven Kelly, Kalle Lyytinen, Matti Rossi: MetaEdit+: A Fully Configurable Multi-User and Multi-Tool CASE and CAME Environment. CAiSE, 1996, pp. 1–21 (Ch 3 here)
3 Language Workbench Challenge, 2014, http://www.languageworkbenches.net/2014/08/lwc2014-the-participants/
4 Rachel Potvin and Josh Levenberg, 2016. Why Google Stores Billions of Lines of Code in a Single Repository, Communications of the ACM, vol 59 pp. 78–87 (https://doi.org/10.1145/2854146, Video: https://youtu.be/W71BTkUbdqE)
Dr. Steven Kelly is the CTO of MetaCase and co-founder of the DSM Forum. He has over twenty years of experience of consulting and building tools for Domain-Specific Modeling.


An expanded version of this article was published in the BigMDE 2017 proceedings: http://www.metacase.com/papers/Collaborative_Modeling_with_Version_Control_final.pdf