

As all of you, I’ve also been playing with ChatGPT. I’ve tried it to generate code and models from simple prompts. With impressive but mixed results. ChatGPT will NOT definitely replace programmers. Even less modelers. But it still may revolutionize software development, especially, model-driven software development. In this post, I explain how.
Firsts experiments with ChatGPT
For instance, regarding code generation, I ask it to create a simple WordPress plugin (as this seemed indeed possible) to display my most popular slideshare presentations in any page thanks to a new WP shortcode. The result was a piece of useful but incomplete code with some small errors regarding the use of the slideshare API due to mixing up API versions. I was able to improve the results by chatting with ChatGPT. But of course, I could only do so because I have enough experience in building WP plugins to know what was missing.
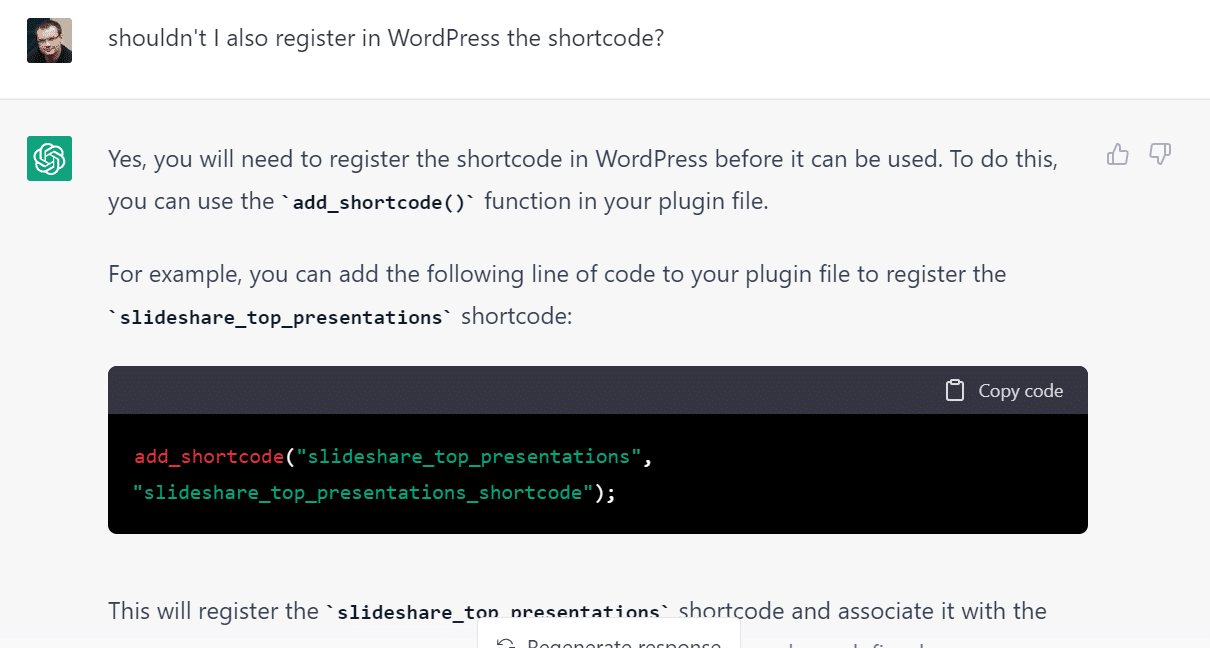
Asking ChatGPT to complete the generated code as it forgot that shortcodes need to be registered in WordPress before being able to use them
When it comes to generating models, ChatGPT confessed it cannot draw diagrams but I was pleasantly surprised to see that ChatGPT knows the PlantUML syntax so we can use it to create textual models. You can even teach ChatGPT new syntaxes via examples. Again, the results were useful but far from perfect. If you ask ChatGPT to create a class diagram for a purchasing system you get a mostly correct PlantUML model (sometimes it makes some mistakes with the syntax of associations) that could be used as inspiration for the real model you’ll need to create. To me, it looks mostly useful as a way to double-check whether you’re missing something (e.g. you may see in the ChatGPT model an attribute you didn’t have and that, indeed, it should be part of your model). And, since every time you ask, you get an entirely different result, it could also be used to see variations of models in the domain that could potentially propose some interesting alternative design suggestions.
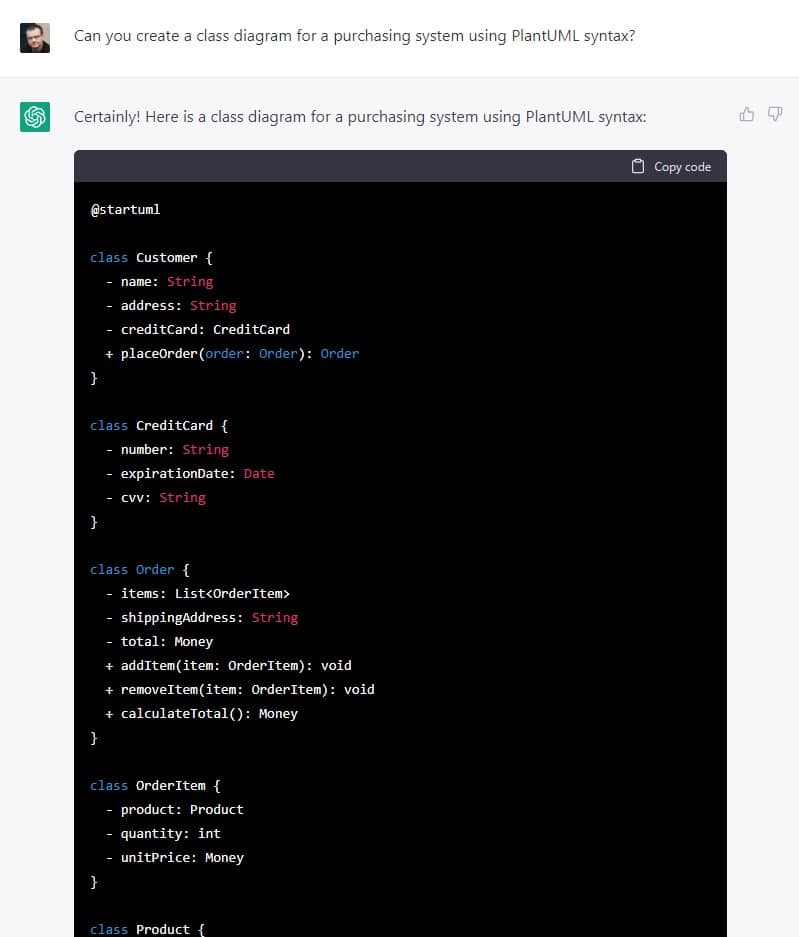
Generation of a class diagram with PlantUML textual notation with ChatGPT
Will LLMs replace programmers? And modelers?
With ChatGPT and the growing popularity of all types of Large Language Models (LLM) trained to perform many different tasks, including all types of code-related ones such as writing code based on an initial prompt, many people started to wonder whether this was the end of programming as a profession.
Clearly, this is not the case. So far, LLMs excel only at generating boilerplate code while making mistakes at more complex tasks. And if you’re a programmer, I do hope your job involves more than writing repetitive boilerplate code!!!! As Kai-Fu Lee puts it, the more creativity a job requires, the more humans excel at it and the worse AI systems perform.

Moreover, any type of complex program generation would require a very precise specification of what needs to be created. And that’s our job, the job of the modeling experts. So we are even safer than programmers!
From models to prompts (or my belief that LLMs will replace code generators)
This idea of a component that excels at generating repetitive code from models sounds familiar, doesn’t it? In model-driven development, this is what we know as code generators: model to text transformations that apply a set of rules on an input model to generate code.
So, hear me out, my prediction is that we will soon see LLMs-based generators in low-code platforms. You’d still create the models but then those formal specifications and software models would be translated into a set of precise prompts for an underlying LLMs in charge of generating the actual code. Same as current rule-based and manually written code generators, there is so much you can generate and there will always be some manual coding involved as soon as you need something not completely typical. But again, this is already a limitation of current generators not a new one imposed by the use of LLMs.
There are obvious drawbacks to this idea. To begin with, the output will not be deterministic. I’m pretty sure that with some proper prompt engineering we would manage to get always similar results but this could be an issue. Another issue is that we can never be 100% sure of the quality of the generated code. “Traditional” code generators can be certified, LLM-based ones no (at least not now). So forget about using these LLM-based low-code platforms for critical applications (but I’d argue low-code platforms do NOT target these type of applications and focus on more consumer-oriented data-driven ones anyway).
But there are also obvious benefits. The biggest one would be the capacity to target any platform immediately and at no additional cost. Now you don’t need to create (and maintain!) a new generator for every platform you want to generate code for. With a single LLM you can target all of them. And as long as you keep updating the LLM version you’re using, you’ll be able to immediately target new platforms and new versions of such platforms to always generate up-to-date code. And once you embed an LLM into your platform, you could use the same LLM for other tasks beyond code-generation such as the validation of the models via a verbalization in natural language to discuss them with the client (something that right now takes a lot of effort and requires some non-trivial model-to-model transformations).
How do YOU see the role of LLMs in model-driven development?
Do you agree with my perspective? Do you have a more (or less) ambitious one? What’s your take on the future role of LLMs in model-driven engineering? What other tasks in software engineering (and, of course, model-driven engineering) will be reduced to prompt engineering? Looking forward to read your comments!
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


> To begin with, the output will not be deterministic.
Maybe an alternative would be to make such LLMs output templates rather than code? Or interpreters for your models?
The non-determinism is really intrinsic to LLMs but my guess is that we could at least minimize it with proper training (e.g. showing examples following similar templates) and consistent prompts. Not sure how to use LLMs to interpret the models
thank you Jordi, great post! My expectation is that people will build on open source LLMs like gpt-neoX (https://huggingface.co/docs/transformers/model_doc/gpt_neox)
Though ultimately, minima in the cost/precision ratio will decide what you can really do that has value.
I wonder how the need to “fight” the non-determinism will affect the cost/benefit ratio here: my feeling is that the more applications you build from your models, the more the cost of writing a generator is compensated by the cost of having to ensure a reasonable level of consistency in outcome. So, in a lowcode environment do you really benefit from using a GPT-style backend or is it more cost-effective in the long run to invest in building an actual code generator? Especially, where your business model isn’t about supporting arbitrary target platforms.
The key here is “in the long run”. I think at the very least, LLMs can offer a quick way to extend your MDE tool with code-generation capabilities to see: 1- What target platforms your user prefer and 2- What types of generations they want for these platforms.
Then you can build a “real” code generator for those combinations
Yes, agreed on the non-determinism aspect of the LLMs.
My point was more to say: as a developer, I can ask a LLMs to propose a template rather actual code (ChatGPT knows about T4 at least, tried it quickly) and once we found a template that fits our need, freeze it and stop using LLMs.
Very good suggestion. I had not thought about this possibility!
Software development tasks, to my experience, fall into three different levels : repetitive, craftsmanschip, and creative shaping, say, similar to architecture of buildings. Plus all the post-delivery tasks like maintenance and bug-fixing, migration to new platforms, fusing of systems, splitting into independent systems etc.
GPT, which is seen by the articles fit for repetive tasks, could be brought to the craftmanship level by training it on code, documentation and test suites altogether.
An experienced programmer, given a user story or a sketch of documentation, will fill in the specification gaps out of her/his experience and technical and domain knowledge. It would be interesting to see if this gap-filling capability can be learnt just by relying on the above-mentioned inputs.
Interesting article. I honestly believe that the opposite will actually happen: LLM will be used to create to understand requirements expressed in natural language, but they will NOT generate code: LLM will just generate models for a low-code platform that will finally generate the code.
The point is that debugging large amounts of LLM-generated code can be extremely expensive, and I feel that an LLM can make errors in a much more subtle “apparently correct” way than a human. Kind of the same problem you can see playing with ChatGPT.
Using LLM to generate “models” for a low-code platform is a much better approach, because models, expecially diagram-based models (UML models, for instance) have a mugh higher level of abstraction and therefore they are definitely more understandable and checkable by humans.
Once verified that an LLM-generated model is correct (which can be done in a cost-effective way), code generation will be done by the low-code platform in a strictly predictable and reliable fashion.
By the way, this is exactly the approach we are applying on Livebase, the diagrammatic low-code platform for enterprise backends we are developing and operating since 2012.
I believe that ChatGPT can generate a nice Plantuml schema, if its provided exact instructions, there are some nice examples in the internet, as here https://blog.ouseful.info/2022/12/12/generating-diagrams-from-text-generated-by-chatgpt/ or here https://www.youtube.com/watch?v=D3C3tZFyT8Q So there is definitely a future, however its important to be as much specific as possible. We have to learn how to ask questions to get the right answers. Another interesting thing, things may be in refactoring large UML models, I want to test it. So it should be a problem for an LLM to generate flow, bpm, uml diagrams to a certain complexity. Working with the code is a different issue because of its low-level structuring and dependencies etc. So how to get to the executable code? Through UML – Low Code platform or higher level structured language, like http://www.teseron.io (it’s our project ) . We plan to develop UML – executable code examples, as we work with high-level structures in our coding paradigm.