

A big challenge with the migration of certain legacy applications is that much of the business logic is inside triggers which are written in the PL/SQL language and scattered across the application layers. Among others, this is often the case with the migration of Oracle forms.
In the paper, Model-based Assisted Migration of Oracle Forms Applications: The Overall Process in an Industrial Setting, co-authored by Cristo Rodríguez, Kelly Garcés, Jordi Cabot, Rubby Casallas, Fabian Melo, Daniel Escobar and Alejandro Salamanca we present a model-based migration method that helps developers understand and replicate the business logic of Oracle form (and other legacy technologies) in new platforms. The full paper will appear in the Software: Practice and Experience Journal. Read on for a quick summary or take a look at our current pre-print copy of the work.
Introduction
Most organizations wish to migrate their legacy applications to new architectures and technologies, pressured by factors such as high maintenance costs, technical debt, inability to cope with incoming requirements and regulations, incompatibility with other systems, ceasing support by vendors, and lack of experts on out-of-date programming languages and technologies.
A migration project involves two main phases: i) reverse engineering; and ii) forward engineering. Reverse engineering aims at understanding the current system through representations at a higher-abstraction level (e.g., different kinds of software models) compared to that of code. The reverse phase may include restructuring the source system to favor quality attributes in the target application. Forward engineering is the process of transforming those high level representations into the physical implementation of an application.
There are many challenges in a migration project: insufficient documentation, lack of knowledge about the legacy technology, unclear application’s architecture and software structure, and a big deal of uncertainty about how to estimate and plan the project. Migration of Oracle forms is a specially interesting technology to target in a migration project. Forms applications are present in many sectors. Results of a tool usage survey, carried out by the Oracle User Group Community Focused On Education (ODTUG) in 2009, indicate that 40% of 581 respondents (application developers) use Oracle Forms.
We undertake a long collaboration with Asesoftware, a Colombian software company that offers migration services to its clients who desire to translate source code to other technologies such as Java or .Net. As a result of this work, we have managed to incrementally propose a technology-independent migration method supported by a commercial product called SMoT (Smart Migration Tool). SMoT is based on Model-Driven Engineering (MDE) techniques. SMoT was designed to tackle the challenges mentioned above.
One cornerstone component in our solution is the languages (referred to as metamodels) describing 4GL technologies. These languages, together with parsers, editors and model transformations, strive towards technology independence. One important contribution is that people who do not know very well Oracle Forms technology can work using the high level abstraction views not only to understand the architecture but also to modify and reorganize, at that level, the initial application to favor quality attributes in the target application. Once decision-making is performed, SMoT is able to produce an application written in the target language. It is worth noting that SMoT addresses the code translation of the application structure that refers to the graphical interface arrangement (i.e., basically through forms) and how the interface is mapped to database tables to perform basic CRUD (Create/Read/Update/Delete) functionality.
Besides the structure, a characteristic of these applications is that most of the business logic is inside small programs written in PL/SQL which are triggered by events. Like other works, we aim at reverse-engineering the PL/SQL code in order to achieve a much more complete migration. Nevertheless, a fully automated translation of the application business logic expressed in the PL/SQL code is out of the paper’s scope. For leveraging program comprehension, SMoT executes an algorithm that matches the PL/SQL blocks against a catalog of code patterns. A code pattern is a set of statements that frequently appear together in the code and that implement a specific business logic validation or functionality. After that, SMoT displays the PL/SQL code {classified according to functional purpose. Finally, in the generation step, the approach embeds the PL/SQL snippets, marked as “to migrate”, in strategical locations of the target code for developers to manually translate them. The difference with respect to previous works is that our approach goes beyond the syntactic level: it specifically targets the semantics of the PL/SQL code.
In addition, to tackle the challenges related to project management, on top of the legacy/intermediate models, SMoT has functional features to help developers to estimate, plan, and track the project progress.
In a nutshell, the contributions of this work are:
- a platform-independent migration method that goes beyond the technical translation from source to target, as it includes managerial steps such as planning and project progress tracking. It is worth noting that said translation tackles the application structure;
- a technical contribution regarding the comprehension of PL/SQL code;
- lessons learned in applying our method to an industrial setting.
Model-based assistant migration process
We have designed the migration approach to be Technology-independent. For each new source or target technology, we have to develop some assets (referred to as the Base migration process) that are then reused for every project that conforms to such technologies (this is called Migration application process).
Base migration process
This process is carried out if the business analysis shows that the migration is financially viable. The analysis studies the business value that the migration from a particular source to a target technology would bring to the company. The study includes: i) identification of stakeholders and migration goals; ii) evaluation of similar migration efforts of competitors; and iii) definition of plan and cost estimation for the base migration process.
Therefore, the base migration process starts with the business analysis and its end state is the tooling that assists users (such as analysts, architects, developers) in migration projects. This process should be led by a team consisting of Model-Driven Reverse Engineering (MDRE) experts, legacy experts, and software architects. This process has the following steps:
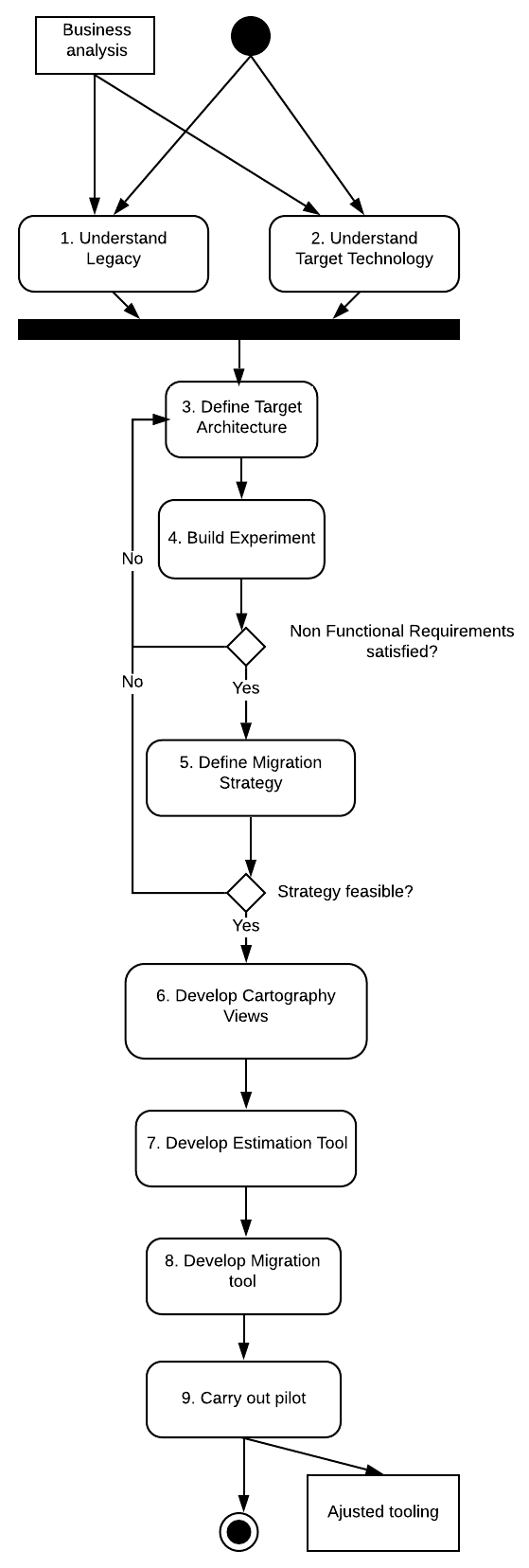
Note that, once the team members establish the migration strategy (in step 5), they decide the scope by answering the following questions: i) which constructs of the legacy are kept as-is?; ii) which constructs of the legacy are worth migrating to the target?; iii) which are the mappings between these constructs and the target technology?; iv) which parts of the legacy will be migrated (semi)automatically?; v) which parts of the legacy will be migrated by hand?; how to properly indicate to developers the location where code completion is needed?; and vii) what kind of mechanism will preserve automatically generated code from mistakes manually introduced by developers?. Answers to these questions serve to specify the requirements for cartography (abstraction of the legacy applications), planning and code translation.
Migration application process
The process starts with the legacy system of a particular client. Its end state is the target application. The development team (including analysts, architects, developers and testers) is supported by the migration tooling built in the base migration process. The instantiation consists of four phases, each of which comprehends one or more steps as depicted in the following figure.
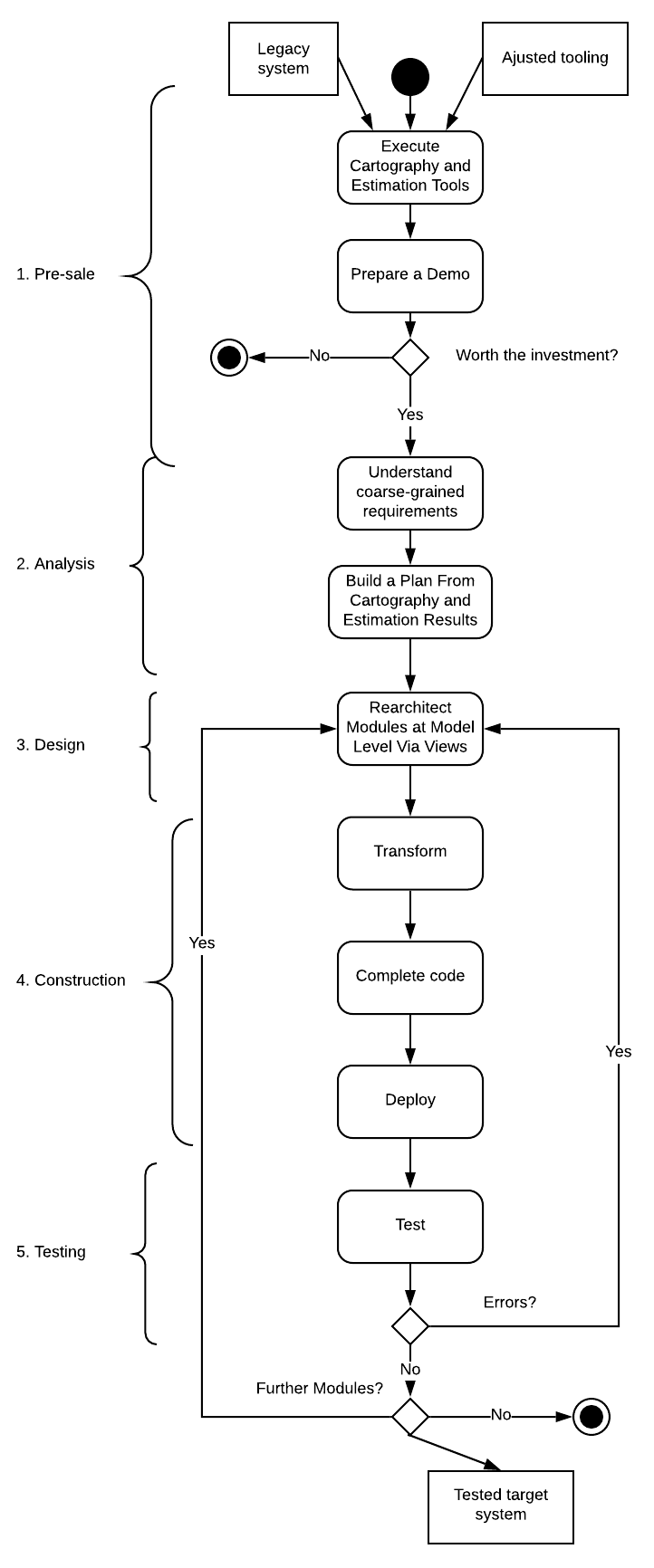
Model-based migration support
As an example, for the Oracle forms case study, we ended up developing the following models and model transformations for steps 6-8 of the base migration process that were then applied to the concrete migration project carried out by AseSoftware.
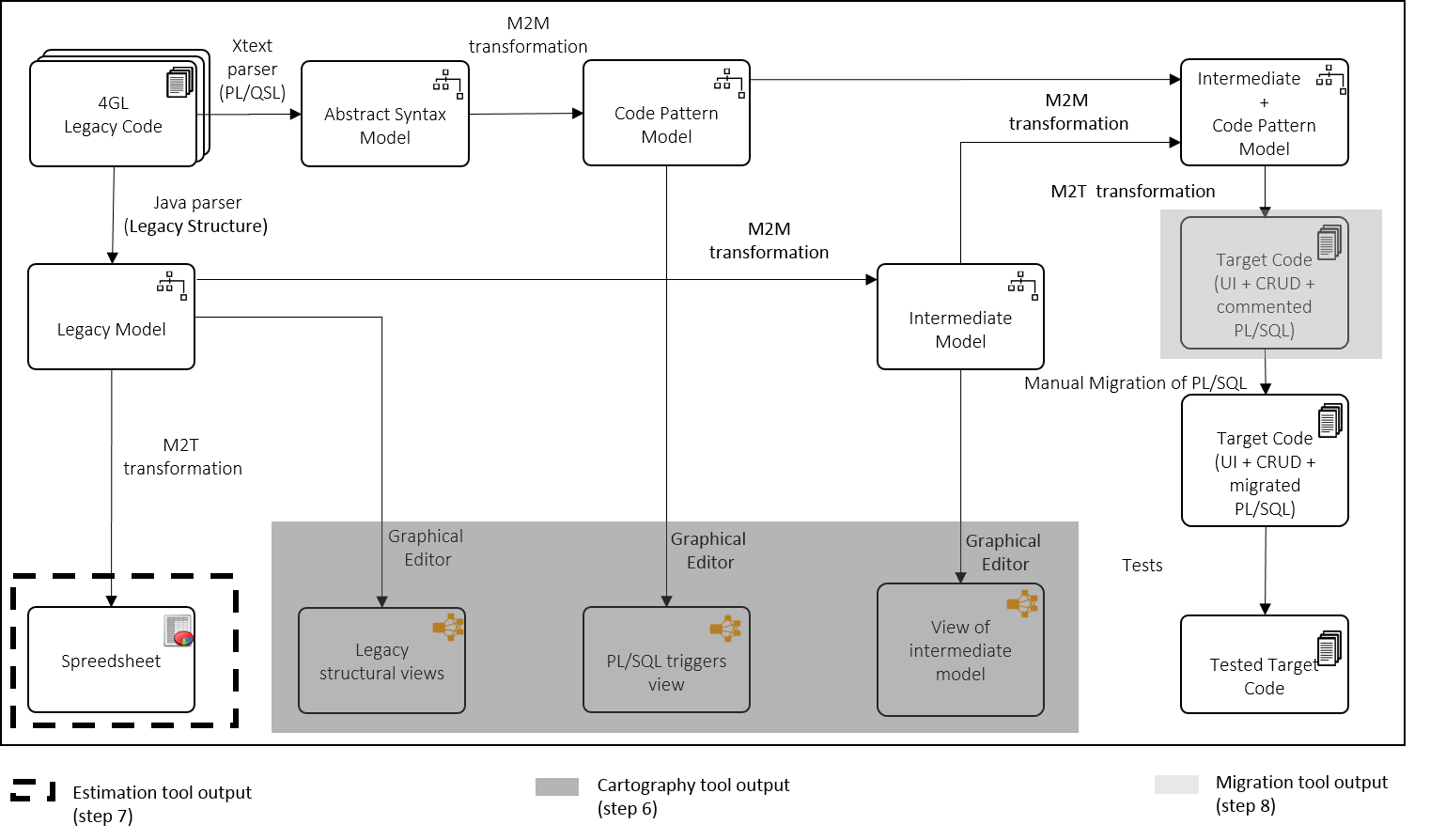
Note that the tooling follows the three stages of model-based reengineering: reverse engineering, restructuring, and forward engineering. The reverse engineering stage covers the injection of source code into the legacy and code pattern models. In turn, the restructuring stage covers the decisions that developers can make on top of the intermediate and code patterns models. Finally, the forward engineering stage takes these models as input and produces the target code.
Discovery of PL/SQL pattern occurrences
A key element in the model-based tooling above is the PL/SQL View. This view allows the legacy expert to plan which triggers are worth migrating to the target application. The expert displays and navigates the Code Pattern Model by using the view. The purpose is to mark each trigger either with the label “to migrate” or “to skip”. Based on this, the generation step either embeds or does not embed the source PL/SQL code in the target code for the developer to manually transform it. In this view, triggers are classified by category based on an automatic analysis of the PL/SQL code according to a predefined number of patterns representing common ways of implementing specific business logic validation or functionality. For instance, in master/detail forms, the code that prevents orphaned records is common.
Patterns are classified into the following four categories:
- Field validation: ensures that the application receives correct and useful data;
- Field population: derives new information from user inputs;
- Model constraints: enforces entity integrity constraints, such as foreign keys and unique keys; and
- Miscellaneous.
This classification was influenced by the strategy followed to build the catalog. Firstly, we manually identified common patterns in a dataset of applications provided by Asesoftware. After that, we relied on experts’ opinions to improve the patterns list. Finally, for the sake of alignment, we compared our patterns with the classification that the same Oracle Forms community gives to the triggers (e.g., WHEN VALIDATE; ON POPULATE and ON CHECK).
Each pattern is described by means of a template with the following items: abbreviation, name, purpose, pseudocode (i.e., the pattern specification), and parameters (the parts of a pattern that are dynamic). Note that some patterns can be grouped in families of closely related syntactic variations that express the same functionality; e.g., a SELECT-INTO or FETCH statement could be used to retrieve records from the database without changing the code semantics. For illustration purposes, the pattern that describes the code given in Listing 1 is presented below.
An algorithm matches the patterns in the catalog against the Abstract Syntax Model of the code.
Results and Lessons Learned
The application of our method showed significant time savings in all phases of the migration process (again, look at the paper for the full details) while also improving the quality of the code in the new platform implementation. This was indeed a successful example of the transfer of MDE techniques to industry as Asesoftware has created an automation department where developers apply MDE techniques on their own to solve the company’s challenges. We attribute this success to:
- a formal training to the company employees by university experts on MDE;
- involving management members as project stakeholders; and
- a clear scope and a shared vision of the project
Despite the positive view of MDE, we did run into some troubles when trying to use existing MDE tools in an industrial setting. As an example, even if declarative transformation rules as the ones provided by ETL are conceptually better and simpler, we found that they were not expressive enough to cover all our needs and therefore we were forced to “pollute” ETL code with imperative Java constructs to manipulate strings and fine-tune the rule application ordering.
Another example would be the building of the XText-based abstract syntax metamodel for PL/SQL. There, we had to go back and forth between the grammar and Xtext in order to solve ambiguity problems and get a readable metamodel. Finally, we developed unit tests for the m2m transformations. Such tests aim at detecting regressions by comparing gold standard models with the models outputted by the last versions of the transformations. In this part, we encountered that Epsilon Ant tasks have problems when loading models produced by XText. We arrived to a workaround that programmatically calls the tests.
This last point led us to one reflection: practitioners perceive that the maintenance and documentation of MDE tools are poor, which may discourage them from using the MDE paradigm.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


This is such a practically relevant and hands-on application of model-driven engineering. There should be many more of these applications out there. IMHO, legacy migration is the killer app of MDE.