

Creating a new language is for many a mysterious activity. Even experienced programmers wonder: where do I start to make a language that works in practice?
This is a good question to ask and we are going to provide an answer to it in this article.
While the idea of creating a language could cause enthusiasm in some readers, others will wonder why someone should want to create a language in the first place.
We think a language could be created for different reasons:
- to represent concepts of a specific domain, i.e. for creating Domain Specific Languages
- to experiment with new programming paradigms
- to create a new general purpose language with a different balance between productivity, conciseness and flexibility w.r.t. the existing alternatives
- just to learn more about this fascinating topic
These reasons have lead to the creation of hundreds of programming languages in a world populated by millions of developers and thousands of projects starting every day. So why not many more languages are created?
The cost of developing languages
Because building languages is costly in general. It requires strong competencies and a significant effort. To build a language you need to put together a lot of pieces: you will need to parse your code, to validate it, to interpret it or to compile it and finally, you will need supporting tools. Your users will probably demand an editor, maybe a build system. Every little piece of software that makes working with your language more bearable.
In addition to that, you need some competencies in language design and those are acquired only with experience on the field.
Creating languages with a limited effort
There are different ways to build languages: you could decide to use Language Workbenches such as Xtext or Jetbrains MPS. You would reduce the complexity of your task, if and only if you know how to use such tools.
The problem is that learning how to use them is a significant accomplishment and while Language Workbenches work very well in some contexts, they are not always the right solution.
So in this article, we are going to take a different route: we will see how to build a language with less than 1.000 lines of code, using a concise language named Kotlin.
Build a DSL using less than 1000 lines of code thanks to Kotlin Click To TweetThe philosophy of our approach
Our philosophy follows a simple principle:
What is not there, cannot be broken
Following this principle, we adopt an approach that minimizes dependencies and privileges simple approaches, because of their robustness.
This is the way we prefer when we need to build a solution we can rely on. If we receive an emergency call because our service is down at 4 AM we want to be able to fix it, and fix it quickly. We do not want to fight with the 10 layers of a complex technology we do not completely understand. We want to go back to sleep.
The best way to start a simple, concise system is by using a simple concise language. We picked Kotlin.
In addition to Kotlin, we are using a few dependencies. Solid, well-understood stuff that can save us time. The first and most relevant dependency is ANTLR: ANTLR is a parser generator. You give it to it a description of a grammar in EBNF format and it generates a parser for such grammar for you.
What we are going to build
To process a language we will need to go through different steps:
- Parsing: reading the code and understanding it
- Validation: checking if the instructions written make sense
- Execution: execute the instructions received
The process is the represented in the picture below.
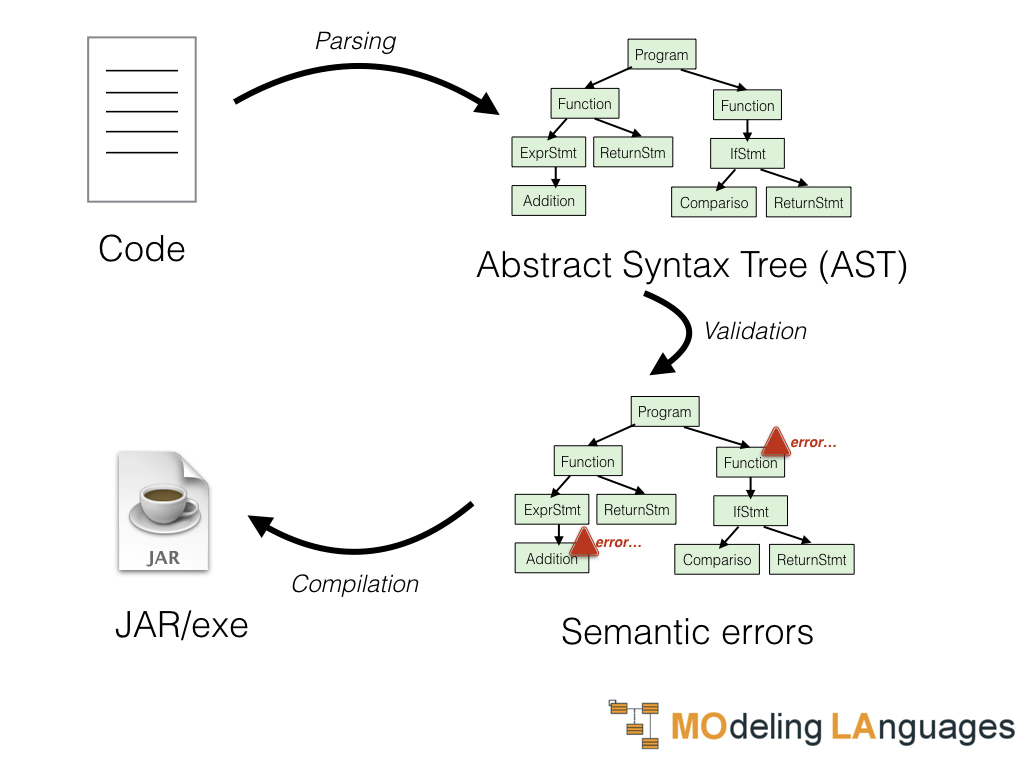
Let’s look at each step separately.
First of all, we need to analyze the code and understand what the user of the language is trying to tell us. This first phase is called parsing. It takes the code written in our language and provides us with a representation of the information contained in that code. This representation is called an Abstract Syntax Tree (AST).
Once we have understood what the user is trying to tell us we need to verify if it makes sense. For example, the user could write code to sum two integers (which is ok) or two dates (which is not ok). We could be able to build in AST in both cases but in the latter, we would need to report a semantic error.
If the user wrote something that makes sense we can allow to execute such code. The two main alternatives to execute the code are using an interpreter or a compiler. In the first case, we will have simply a piece of code that will examine the AST and do something according to the content of the AST. In the second case, instead, our compiler will analyze the AST and generate some executable format to be later executed. Now, our compiler could generate different executable formats. We will consider two cases: the generation of JVM bytecode and the generation of native executables by relying on the LLVM.
…but there is still something we are going to need
These three steps would be sufficient to produce a language that can be executed. However in practice we are going to need an editor to support our language. Users are picky these days, so let’s forget about expecting users to just open notepad, ok?

Now, we cannot dive also in how to build a supporting editor in this article, however this is an aspect that you as a language designer needs to consider.
Typically to decide what kind of editing support you want to offer to your users you should consider their typical workflow. Is your language something that is going to be used together with well-established programming languages? If that is the case you could build your editors as plugins for IntelliJ IDEA or Visual Studio Code. In the latter case you may want to look into the Language Server Protocol.
If your editor is going to be standalone you could consider using this framework I created: Kanvas.
How much effort is going to cost me?
In this article is not going to be a detailed tutorial on building a language. That would be way too long. What we are going to do is giving you the big picture and explain the strategy and how complex each step would be. We are also going to use examples from the book I wrote on building languages.
We are taking the examples provided there to give you an estimate in number of lines for each step. Note that our estimates include blank lines and comments, because we are not stingy and most importantly because we are too lazy to remove them from the count. The examples we are going to consider are about simple but complete DSLs. Of course you can build languages significantly more complex but still it should give you an idea about the relative complexity of the different phases.
Having said that, now is time to jump in and look at the different phases necessary for building a language.
The 'What is not there cannot be broken' philosophy applied to language design Click To Tweet1. Building a parser
The goal of this step is to transform the program from a format that is easy to produce for the user (the code), to a format that is easy to process and execute (the Abstract Syntax Tree).
We have anticipated that we are going to use ANTLR in this phase. ANTLR is a tool that given a description of the language can generate two pieces of software for us: a lexer and a parser.
- A lexer will be a class that given the original code will recognize the single elements in it and returns a sequence of tokens. The tokens could be identifiers, operators, keywords, number, etc. It will also remove things like whitespace and comments.
- The parser will be another class that will take the list of tokens produced by the lexer and output a first tree named parse tree. This tree will be a first structure grouping the tokens into a hierarchy of nodes.
It is interesting to notice that from the same description ANTLR is able to generate lexers and parsers in Java, C#, C, Python, Swift, JavaScript, and Go. Quite impressive, eh?
If you wish to learn more about ANTLR we would suggest taking a look at the ANTLR mega tutorial.
Now, we could work directly on the parse tree. However, the parse tree is expressed using instances of classes generated by ANTLR that are not well suited to support the following phases. For this reasons I normally write my own classes to represent the different concepts of the language and then perform the mapping from the parse-tree (composed by ANTLR classes) to the AST (composed by my fancy Kotlin classes). While performing this translation I also take advantage of the translation process to perform some simplifications.
They way I typically operate is to:
- Generate a lexer using ANTLR
- Generate a parser using ANTLR
- Define the metamodel classes in Kotlin
- Define the mapping between the parse-tree provided by ANTLR and the metamodel classes we defined in Kotlin
So this first phase that we called parsing can be seen as a sequence of these operations:
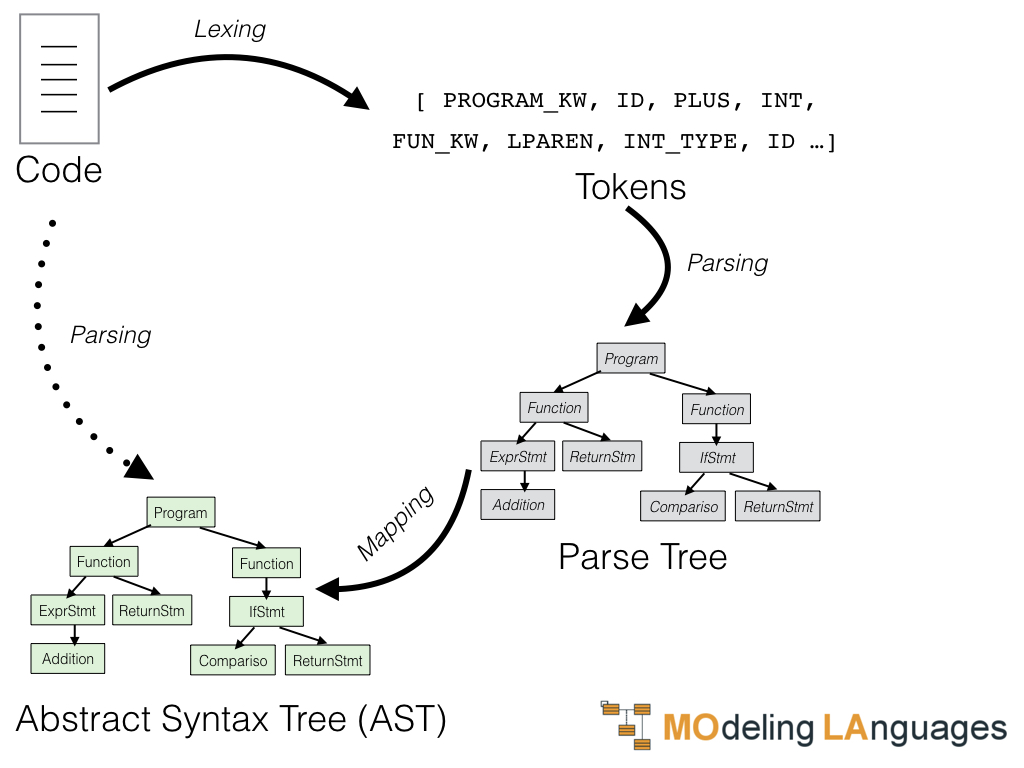
1.1 Define a lexer using ANTLR
Lines in the examples: 53-84
The bulk of defining a lexer using ANTLR consists in defining the rules we are going to use to split the code to process into tokens.
For example, we are going to say that:
- the word “input” corresponds to a token of type INPUT
- a sequence of digits is a token of type INTLIT
- a sequence of digits with a dot in between is a token of type DECLIT
- the symbol “+” should be recognized as a token of type PLUS
This is how these and a few more rules can be expressed in an ANTLR lexer:
// Whitespace NEWLINE : '\r\n' | '\r' | '\n' ; WS : [\t ]+ -> channel(WHITESPACE) ; // Keywords INPUT : 'input' ; VAR : 'var' ; ... // Identifiers ID : [_]*[a-z][A-Za-z0-9_]* ; // Literals INTLIT : '0'|[1-9][0-9]* ; DECLIT : '0'|[1-9][0-9]* '.' [0-9]+ ; // Operators PLUS : '+' ; MINUS : '-' ; ...
It is fairly easy and intuitive to specify lexer rules. There are some advanced topics to consider, like “island languages”: i.e., a portion of code that must processed differently. Think about Java code into a JSP: some words corresponds to keywords when used inside a Java block but are just text outside. Anyway, with a good ANTLR manual and some experience building lexers is reasonably easy.
1.2 Define a parser using ANTLR
Lines in the examples: 41-44
Defining a parser using ANTLR is somewhat similar to defining a lexer. We still have to specify rules but we are specifying rules that organize the tokens into a tree, instead of organizing the code into tokens. Also, the lexer produces a list of tokens, while the parser produces a tree, with one element at the top and below it other subelements until we reach the tokens, which are the leaves of the tree.
These are some rules we could define:
- a statement could corresponds to an assignment, a print or the single token EXIT
- a print is composed by the sequence of the tokens PRINT, LPAREN, followed by the an element of type expression, and a token RPAREN
- an expression can be defined in many ways and the precedence of different operators should be considered. In order of precedence, the first alternative to compose an expression is the sequence of: another expression, the DIVISION or the ASTERISK token, and then another expression
statement : assignment # assignmentStatement
| print # printStatement
| EXIT # exitStatement ;
print : PRINT LPAREN expression RPAREN ;
assignment : ID ASSIGN expression ;
expression : left=expression operator=(DIVISION|ASTERISK) right=expression # binaryOperation
| left=expression operator=(PLUS|MINUS) right=expression # binaryOperation
| value=expression AS targetType=type # typeConversion
| LPAREN expression RPAREN # parenExpression
| ID # valueReference
| MINUS expression # minusExpression
| INTLIT # intLiteral
| DECLIT # decimalLiteral
| STRINGLIT # stringLiteral ;
Typically defining parser rules requires a bit more experience compared to building lexer rules. There are typical patterns that recur from language to language, like the way we specify statements or expressions.
What will ANTLR give us when executed on our grammar? A parser and a set of classes, one for each rule. Let’s see an example:
class MyGeneratedParser {
...
public static class StatementContext extends ParserRuleContext {
public StatementContext(ParserRuleContext parent, int invokingState) {
super(parent, invokingState);
}
@Override public int getRuleIndex() { return RULE_statement; }
public StatementContext() { }
public void copyFrom(StatementContext ctx) {
super.copyFrom(ctx);
}
}
public static class PrintStatementContext extends StatementContext {
public PrintContext print() {
return getRuleContext(PrintContext.class,0);
}
public PrintStatementContext(StatementContext ctx) { copyFrom(ctx); }
@Override
public void enterRule(ParseTreeListener listener) {
if ( listener instanceof StaMacParserListener ) ((StaMacParserListener)listener).enterPrintStatement(this);
}
@Override
public void exitRule(ParseTreeListener listener) {
if ( listener instanceof StaMacParserListener ) ((StaMacParserListener)listener).exitPrintStatement(this);
}
}
public static class ExitStatementContext extends StatementContext {
public TerminalNode EXIT() { return getToken(StaMacParser.EXIT, 0); }
public ExitStatementContext(StatementContext ctx) { copyFrom(ctx); }
@Override
public void enterRule(ParseTreeListener listener) {
if ( listener instanceof StaMacParserListener ) ((StaMacParserListener)listener).enterExitStatement(this);
}
@Override
public void exitRule(ParseTreeListener listener) {
if ( listener instanceof StaMacParserListener ) ((StaMacParserListener)listener).exitExitStatement(this);
}
}
public static class AssignmentStatementContext extends StatementContext {
public AssignmentContext assignment() {
return getRuleContext(AssignmentContext.class,0);
}
public AssignmentStatementContext(StatementContext ctx) { copyFrom(ctx); }
@Override
public void enterRule(ParseTreeListener listener) {
if ( listener instanceof StaMacParserListener ) ((StaMacParserListener)listener).enterAssignmentStatement(this);
}
@Override
public void exitRule(ParseTreeListener listener) {
if ( listener instanceof StaMacParserListener ) ((StaMacParserListener)listener).exitAssignmentStatement(this);
}
}
...
} // end of my generated parser
So when invoking our parser on the code of our language we will obtain a parse tree, composed by the instances of these <RuleName>Context classes generated by ANTLR.
1.3 Define the metamodel classes in Kotlin
Lines in the examples: 116-132
The problem is that the parse-tree classes generated by ANTLR are awkward to work with. For these reasons I normally prefer to define my own classes for the rules and proceed to translate between the ANTLR generated classes and my own classes. We will see how we can define such classes in Kotlin.
We define them as data classes. Data classes are very useful to represent immutable values. They can be defined very concisely. Consider any of the following data classes: to define them in Java we will need to specify the fields, a constructor receiving the values and assigning them to fields, getters for each field, an hashCode, an equals and a toString method. This would amount to a fair number of lines of boilerplate. In Kotlin things are much, much cleaner.
In addition to data classes we define a few interfaces. They represent rules that can be specified in multiply ways like an Expression or a BinaryExpression.
interface BinaryExpression : Expression {
val left: Expression
val right: Expression
}
data class SumExpression(override val left: Expression,
override val right: Expression,
override val position: Position? = null) : BinaryExpression
data class SubtractionExpression(override val left: Expression,
override val right: Expression,
override val position: Position? = null) : BinaryExpression
data class MultiplicationExpression(override val left: Expression,
override val right: Expression,
override val position: Position? = null) : BinaryExpression
data class DivisionExpression(override val left: Expression,
override val right: Expression,
override val position: Position? = null) : BinaryExpression
1.4 Define the mapping between ANTLR and the metamodel classes
Lines in the examples: 70-96
We have our parse-tree, produced for us by the parser, and we have our Kotlin classes. We want now to translate the parse-tree into the AST, composed by instances of our data classes. To do this we are going to define extension methods for the classes of the parse-tree. They are basically methods of a class that can be defined outside the class declaration. In this case, we are adding methods to the parse-tree classes generated by ANTLR. The methods we are going to define are all named toAst and will translate the parse-tree node considered in the corresponding AST node.
Most of the translations are very simple and direct. Consider for example the case of TypeContext:
fun TypeContext.toAst(considerPosition: Boolean = false) : Type = when (this) {
is IntegerContext -> IntType(toPosition(considerPosition))
is DecimalContext -> DecimalType(toPosition(considerPosition))
is StringContext -> StringType(toPosition(considerPosition))
else -> throw UnsupportedOperationException(this.javaClass.canonicalName)
}
Other translations could require some adaptations:
fun BinaryOperationContext.toAst(considerPosition: Boolean = false) : Expression = when (operator.text) {
"+" -> SumExpression(left.toAst(considerPosition), right.toAst(considerPosition), toPosition(considerPosition))
"-" -> SubtractionExpression(left.toAst(considerPosition), right.toAst(considerPosition), toPosition(considerPosition))
"*" -> MultiplicationExpression(left.toAst(considerPosition), right.toAst(considerPosition), toPosition(considerPosition))
"/" -> DivisionExpression(left.toAst(considerPosition), right.toAst(considerPosition), toPosition(considerPosition))
else -> throw UnsupportedOperationException(this.javaClass.canonicalName)
}
You see, in this case we take nodes that in the parse-tree were all of type BinaryOperationContext and we map to nodes of different types in the AST. Depending on the operator we generate AST nodes of type SumExpression, SubtractionExpression, MultiplicationExpression, or DivisionExpression. This is an example of refinements we may want to do when translating from the parse-tree to the AST.
Overall for step 1
Lines in the examples: 314-322
At the end of this phase, we went from the code to a representation of the information in our AST classes. The total amount of lines of code we needed for the whole phase was slightly above 300 lines, including both the ANTLR grammar and the Kotlin code.
2. Building a validator
In this phase, we are going to process the AST to verify that everything is correct so that we can proceed to actually use the AST for something meaningful like execution or generation of some artifacts from it.
To do this we need to do basically three things:
- define typesystem rules
- resolve references
- implement other specific checks
One of the many differentiators of external DSLs with respect to internal DSLs is the possibility of defining specific validation rules and providing very specific information in the error messages. This is very important also considering that users of your DSL could be non-technical persons or could be just learning your language, so they could use some help and directions as they meet a problem. Error messages produced during validation are the perfect place for providing that guidance.
2.1 Typesystem rules
Lines in the examples: 32-54
Many languages have some typesystem rules. If your language permits to process values of different types you could support numbers, strings, characters, dates, custom structures, arrays and more. Typically not all operations can be performed on all values. For this reason you may need to implement typesystem checks to be executed at runtime or at compile time, depending on your language being statically or dynamically typed.
In the case, your language is statically typed these checks should be performed as part of your compiler or during a validation phase of your interpreter.
Now, to evaluate typesystem rules you need also to calculate the type of expression. Think about this piece of Java code:
foo.bar(zum).myMethod();
To validate this simple piece of code we need to answer different questions. If we want to understand if the method myMethod can be called on foo.bar(zum) we need to understand first the type returned by the method bar. Now, it is possible that there are different methods named bar, so we need to understand the types of foo and zum to figure out which method is invoked. Once we do that we can look at the return type of such method and verify if myMethod can be called in this context.
The typesytem rules should help us answer all of these questions. Now certain rules are rather simple and they can be defined like this:
fun ValueDeclaration.type() =
when (this) {
is VarDeclaration -> this.value!!.type()
is InputDeclaration -> this.type
is Param -> this.type
else -> throw UnsupportedOperationException(this.javaClass.canonicalName)
}
Here we add an extension method to a data class defined in Kotlin, so that now we can invoke the method type on the corresponding nodes representing value declarations. Here we say that the type of a declaration is:
- the type of the initial value in case of VarDeclarations
- the type defined in the declaration itself for InputDeclarations and Params
We also need to define typesystem rules for all the expressions of our language:
fun Expression.type() : Type =
when (this) {
is IntLit -> IntType()
is DecLit -> DecimalType()
is StringLit -> StringType()
is SubtractionExpression, is MultiplicationExpression, is DivisionExpression -> {
val be = this as BinaryExpression
if (!be.onNumbers()) {
throw IllegalArgumentException("This operation should be performed on numbers")
}
if (be.left!!.type() is DecimalType || be.right!!.type() is DecimalType)
DecimalType() else IntType()
}
is ValueReference -> {
if (!this.ref!!.resolved) {
throw IllegalStateException("Unsolved reference")
}
this.ref!!.referred!!.type()!!
}
is FunctionCall -> {
if (!this.function!!.resolved) {
throw IllegalStateException("Unsolved reference")
}
this.function!!.referred!!.returnType!!
}
...
}
There are different typical cases:
- literals have typically an obvious type: a string literal will have type string and an integer literal will have type int
- to understand the type of a reference we need to find the corresponding declaration and check the type there
- for functions or method calls we need to find the function or method being invoked and check its return type
- in case of mathematical operations the type of the result typically depends on the type of the operands. For example adding integers should result in an integer value, while adding reals should result in a real value
Most languages tend to have these rules, plus other specific to the language.
2.2 References
Lines in the examples: 20-133
One important thing to do during the validation phases is that symbols used in the code have been declared somewhere. If you see an expression like foo + 2, you need to check that there is a local variable named foo, or a parameter or a field with that name.
The typical approach to resolve symbols is to look for declarations close to the point in which a reference has been used. You first look for the most local variable declarations and then you move up until you look for global variables with that name. If you do not find any match then you have an unresolved reference and you can trigger an error.
Here is some code I used in actual DSLs to check references:
this.specificProcess(ValueReference::class.java) {
if (!it.symbol.tryToResolve(this.variables) && !it.symbol.tryToResolve(this.inputs)) {
errors.add(Error("A reference to symbol '${it.symbol.name}' cannot be resolved", it.position!!))
}
}
this.specificProcess(Assignment::class.java) {
if (!it.variable!!.tryToResolve(this.variables)) {
errors.add(Error("An assignment to symbol '${it.variable!!.name}' cannot be resolved", it.position!!))
}
}
this.specificProcess(OnEventBlock::class.java) {
if (!it.event.tryToResolve(this.events)) {
errors.add(Error("A reference to event '${it.event.name}' cannot be resolved", it.position!!))
}
}
this.specificProcess(OnEventBlock::class.java) {
if (!it.destination.tryToResolve(this.states)) {
errors.add(Error("A reference to state '${it.destination.name}' cannot be resolved", it.position!!))
}
}
You can see that I have used multiple times the very same patterns. First I select all nodes of a certain type in my AST. For example all value references. Once I have one of those I check if there is a variable or an input having a matching name. If I cannot find a match a throw an error. Also for assignments, I follow a very similar approach, with the difference that just variables can be assigned, not inputs.
In this particular DSLs I have also states that can be referred in specific statements (OnEventBlocks). So for all of them I check if the references to the event and the destination state used in the statement are correct. I look for matches among all the events and all the states, respectively. This case is easy because I do not have multiple scopes, but the principle is the same.
2.3 Other validation rules
Lines in the examples: 46-76
Typesystem and reference resolution are part of the validation of basically every language. In addition to those checks there are a number of others that tend to be language specific. A very common one is a check on duplicate names. For example, in a DSL of mine I did not want to allow the declaration of two events with the same name:
val eventsByName = HashMap<String, Int>()
this.specificProcess(EventDeclaration::class.java) {
checkForDuplicate(eventsByName, errors, it)
}
Then there are really specific things. For example, in one DSL I wanted the exit statement to be used only as the last statement of a block, because what follows is unreachable. I also wanted to have exactly one state to be marked as the start state. So I defined this custom logic as part of the validation:
// in a block no statements should follow the exit statement
this.specificProcess(StatementsBlock::class.java) {
val index = it.statements.indexOfFirst { s -> s is StaMacParser.ExitStatementContext }
if (index != -1 && index != (it.statements.size - 1)) {
it.statements.subList(index +1, it.statements.size).forEach { s ->
errors.add(Error("Unreachable statement (following an exit statement)", s.position!!))
}
}
}
// we have exactly one start state
if (this.states.filter { it.start }.size != 1) {
errors.add(Error("A StateMachine should have exactly one start state", this.position!!))
}
Overall for step 2
Lines in the examples: 98-263
We have seen that there are kinds of validation checks that we want to perform over and over across our languages. Aside from those, there are custom rules that really depend on the nature of the language. Whatever the nature of your checks I think that validation is very important to guide your users when working with your language.
We have seen that the effort to provide validation is not huge. We should also consider that is has a huge ROI: every line of validation we write we help and guide the users every time they interact with our language, so this is a part of your language infrastructure on which you may want to invest and that you may want to revisit and refine over time.
3. Executing the code
We will look at three alternative ways to execute your code:
- Building an interpreter
- Building a JVM compiler
- Building a LLVM compiler
You need to provide to your users at least one option. While nothing prevents to give them more than one, typically it is not needed. For some projects, I ended up implementing an interpreter and a compiler because the interpreter was used as part of some simulators while the compiler produces the executable delivered for the usage outside the development environment. In most of other cases have either an interpreter or a simulator was enough.
The difference from the two compilers is that the first produces applications that run on the JVM and could re-use libraries written in Java, Kotlin, Scala, and the other JVM languages. Targeting the LLVM we can instead generate native executables and reuse all libraries that are written in C or have bindings for C. If we need to reuse some sort of runtime environment that determines what compiler we are going to write.
3.A Building an interpreter
Lines in the examples: 136-181
An interpreter is quite easy to write. First of all we need a Symbol Table to collect the declarations we encounter. Below you can find an entire interpreter, with the exclusion of the SymbolTable class. The interpreter is for a language that support mathematical operations, variables, functions and also nested functions.
class MiniCalcInterpreter(val systemInterface: SystemInterface, val inputValues: Map = emptyMap()) {
private val globalSymbolTable = CombinedSymbolTable()
fun fileEvaluation(miniCalcFile: MiniCalcFile) {
miniCalcFile.statements.forEach { executeStatement(it, globalSymbolTable) }
}
fun singleStatementEvaluation(statement: Statement) {
executeStatement(statement, globalSymbolTable)
}
fun getGlobalValue(name: String) : Any = globalSymbolTable.getValue(name)
private fun executeStatement(statement: Statement, symbolTable: CombinedSymbolTable) : Any? =
when (statement) {
is ExpressionStatement -> evaluate(statement.expression!!, symbolTable)
is VarDeclaration -> symbolTable.setValue(statement.name!!, evaluate(statement.value!!, symbolTable))
is Print -> systemInterface.print(evaluate(statement.value!!, symbolTable).toString())
is Assignment -> symbolTable.setValue(statement.varDecl.name, evaluate(statement.value!!, symbolTable))
is FunctionDeclaration -> symbolTable.setFunction(statement.name!!, statement)
is InputDeclaration -> symbolTable.setValue(statement.name!!, inputValues[statement.name]!!)
else -> throw UnsupportedOperationException(statement.javaClass.canonicalName)
}
private fun StringLitPart.evaluate(symbolTable: CombinedSymbolTable) : String =
when (this) {
is ConstantStringLitPart -> this.content
is ExpressionStringLitPart -> evaluate(this.expression!!, symbolTable).toString()
else -> throw UnsupportedOperationException(this.javaClass.canonicalName)
}
private fun evaluate(expression: Expression, symbolTable: CombinedSymbolTable) : Any =
when (expression) {
is IntLit -> expression.value.toInt()
is DecLit -> expression.value.toDouble()
is StringLit -> expression.parts.map { it.evaluate(symbolTable) }.joinToString(separator = "")
is ValueReference -> symbolTable.getValue(expression.ref!!.name)
is SumExpression -> {
val l = evaluate(expression.left!!, symbolTable)
val r = evaluate(expression.right!!, symbolTable)
if (l is Int) {
l + r as Int
} else if (l is Double) {
l + r as Double
} else if (l is String) {
l + r.toString()
} else {
throw UnsupportedOperationException(l.toString()+ " from evaluating " + expression.left)
}
}
is SubtractionExpression -> {
val l = evaluate(expression.left!!, symbolTable)
val r = evaluate(expression.right!!, symbolTable)
if (l is Int) {
l - r as Int
} else if (l is Double) {
l - r as Double
} else {
throw UnsupportedOperationException(expression.toString())
}
}
is MultiplicationExpression -> {
val l = evaluate(expression.left!!, symbolTable)
val r = evaluate(expression.right!!, symbolTable)
if (l is Int) {
l * r as Int
} else if (l is Double) {
l * r as Double
} else {
throw UnsupportedOperationException("Left is " + l.javaClass)
}
}
is DivisionExpression -> {
val l = evaluate(expression.left!!, symbolTable)
val r = evaluate(expression.right!!, symbolTable)
if (l is Int) {
l / r as Int
} else if (l is Double) {
l / r as Double
} else {
throw UnsupportedOperationException(expression.toString())
}
}
is FunctionCall -> {
// SymbolTable: should leave the symbol table until we go at the same level at which the function
// was declared
val functionSymbolTable = CombinedSymbolTable(symbolTable.popUntil(expression.function!!.referred!!))
var i = 0
expression.function!!.referred!!.params.forEach {
functionSymbolTable.setValue(it.name!!, evaluate(expression.params[i++], symbolTable))
}
var result : Any? = null
expression.function!!.referred!!.statements.forEach { result = executeStatement(it, functionSymbolTable) }
if (result == null) {
throw IllegalStateException()
}
result as Any
}
else -> throw UnsupportedOperationException(expression.javaClass.canonicalName)
}
}
The core of an interpreter is the execution of statements and expressions.
When executing statements we typically manipulate expressions. We take their results and print them on the screen or assign them to variables (that means we insert them on the symbol table). We could also have statements that control the flow of execution. I.e., they would determine which statements we execute next.
Evaluating expressions is a significant portion of any interpreter. The goal is to produce a value. Most expressions contain other expressions and require recursive calls to the function to evaluate expressions. For example, think about all the binary operations like the addition or the multiplication. We then have to evaluate some simple elements such literals and references. Literals contain themselves their value, while for references we have to retrieve it from the symbol table. If we have implemented the validation correctly we should be sure to always find a value in the Symbol Table when we look for one.
3.B Building a JVM compiler
Lines in the examples: 362-467
Building a JVM compiler is not trivial because it requires familiarizing with how the JVM works. I would suggest to sit comfortably and read sections of the JVM specification as required. You would not need to learn about all the nitty-gritty details about the order in which you have to write bytes because you can reuse a library like ASM to do the actual bytecode generation. What you need is to understand how the JVM works externally. This is because you have to fit your problem into the JVM constraints. You have to represent all your code in terms of classes and functions. For example, I had to compile a state machine language to the JVM and it required some work to find the right mapping because I had concepts like states and events and I could not map 1-to-1 to classes or methods.
3.C Building a LLVM compiler
Lines in the examples: 553-609
The LLVM is a wonderful piece of technology because it permits to generate executables for multiple platforms and to obtains pretty good performances. The main issue we can face is due to the fact that the bindings for Java are not amazing. They are generated automatically from the C++ API but the result is not documented at all and it is quite cumbersome to work with. For this reason, I suggest to instead generate the textual form of the LLVM Intermediate Representation (IR) and then invoke an LLVM utility that compiles those IR files. I found that much easier than using the Java generated bindings. I also released a small library to work with the LLVM IR format from Kotlin: it is named kllvm.
Overall for step 3
Lines in the examples: 136-609
In this case, we need to select just one alternative, not to implement all of three so we calculate the total number of lines taking the minimum and the maximum across the three options. Obviously writing an interpreter is the option requiring less effort.
In general building an interpreter is relatively easier than building a compiler for two reasons:
- It simply requires less code
- It requires less specific knowledge: it is pretty intuitive compared to having to familiarize with the JVM or the LLVM
I am not saying that building a JVM or a LLVM compiler is terribly hard, but it requires some knowledge specific to the two platforms. There are portions of code that will look similar, i.e., how we deal with statements and expressions. The differences will be in the general architecture of the application generated and due to the fact that the JVM is a stack-based machine, while the LLVM simulates a register-based machine. Details, boring details but a compiler is about getting details right.
Summary
At this point you should have an idea of the effort required to build a language using Kotlin. We are talking about a maybe small but completely functional language: a language that you can edit comfortably in your own editor, for which you can get feedback in the form of precise errors and a language that you can execute through an interpreter or a compiler, taking advantage of the best platforms available: the JVM or LLVM.
This is quite an achievement we think.
Sure, this is an introduction to the topic and not a complete tutorial, however now you have a map, you know what steps are involved and which approaches you can use. If you are interested in learning more on this topic you can read more resources on the topic of creating a programming language. There you will find a list of detailed tutorials and even a book describing the whole approach. If instead you want to learn more about Kotlin and its community you can visit SuperKotlin.
Have fun!
I am an independent Software Architect specialized in Language Engineering. I build languages for a living and helps company building new languages, processing code and transforming it.


Follow the very hot discussion about using #Kotlin to build a #DSL on reddit https://www.reddit.com/r/programming/comments/6mm9qg/building_languages_on_a_budget_using_kotlin/ (>25 comments already)
Has the author looked at the parsing frameworks available in Scala? My guess is no.
If you are going to use ANTLR, that’s what’s saving you ‘money’ not Kotlin. ANTLR works from Java too.
Scala, on the other hand, has several parsers that use the language and not an external generator.
I have used Scala parsing frameworks in the past, in particular I have used papa-carlo. Honestly I am not a Scala fan for different reasons, so I tend not to use it whenever I have an alternative. As you said ANTLR is an important component that I like to use and in my opinion makes for a nicer and more maintenable solution compared to parsing frameworks, independently to the language they are written into.
Whatever thing you use for parsing, this is just one piece of the tooling you need for any language: you still need to validate, resolve references, implement typestem checks, writing an interpreter or a compiler. All of this is done in Kotlin and I think this made me much more productive than I would have been using Java. Maybe a similar productivity would be possible also with Scala, and some could prefer to use it instead of Kotlin. Others could prefer Groovy or Ceylon.
Anyway most of the effort is not spent on the parser but on everything else.
No idea what papa-carlo is. The Scala stdlib had a parser, the parser combinator library. Then two other ones appeared. FastParse is the apparent survivor. My comment is not simply a personal preference (as you seem to dismiss it at the end). It addresses the fact that if people have not seen those tools, they would benefit from looking at them. Also to say that the article cannot possible convince me of its claim (that K reduces language development costs) if it does not even address those tools.
Papa-Carlo is a library to build incremental parsers in Scala. I have used it to build an incremental parser of the Java language in Scala.
I did not want to dismiss your comment as a personal preference. If I gave you this impression I am sorry about that.
It is true that there are many alternatives to ANTLR, I did not want to say that ANTLR is the only way to parse code or it is necessarily the best. For me is a good tool to use because I like the declarative approach and I also like the fact it can generate grammars for other target languages like Python, C#, JavaScript, ecc. In addition to that is declarative nature is useful to do things like generating an autocompletion provider from the grammar definition.
Maybe I should have written a more detailed introduction explaining better the context of my comparison. That said I think that in my experience this combination in certain contexts for me saved time and headaches compared to other alternatives I tried like using language workbenches (Xtext, Jetbrains MPS) or working with Java. This article is an overview of a process and I could not go in more details without the article becoming way too long, however I report the number of lines that were necessarily to implement different steps. It is a flawed and limited metric but in my experience the number of lines in Java will be way higher, maybe using other languages like Scala it could have been comparable or even lower. My goal is not trying to convince anyone that Kotlin is superior to any other language. What I wanted to say is that by using Kotlin or a language as productive as Kotlin it is possible to build complete languages without a Language Workbenches with a limited effort. Now, by building complete languages I mean much more of building a parser, so focusing too much on the parser in my opinion risk to be obfuscate the message
Also, an article comparing just different parsing techniques would be alone quite long. Consider this one: https://tomassetti.me/parsing-in-java . This one is about Java, but I think the same would be true for other languages.
Hey I am a huge language fan. I think all sufficiently complex problems either lend themselves to, and eventually adopt some form of DSL, or become inscrutable balls of mud. And the tide is for sure coming in on that way of thinking, even though the DSL hype balloon came years ago. I like Kotlin, but the reality is that there is nothing I know of that’s comparable to FastParse on Kotlin, and I agree with the author of that tool that ANTLR is often not a sufficient time-saver to go to it immediately.
One of the most interesting things about the FastParse presentation that is linked to their page, btw, is that he claims the original parser that the Scala guys built was a. broken, and b. that because it was completely FP, it was very slow. That’s kind of sad: what is the point of FP If like so many other technologies, it ends up just being unwound and discarded once performance demands prove it too costly? It is also kind of awesome that a single guy can float a dinghy into one of the most esoteric language communities and flip a boat that the elders had built.
My frustration with most parsing/language stuff is it’s all about language compilation and thus as is the case with build tools, the need for speed dumbs everything down. Meanwhile, there are a ton of language problems that no one is even working on, that have seen little to no progress. For instance, if you look at Apache Tikka, they wanted to make it so that you could find entities in the text you were processing. Even proper names, they pretty much offer nothing for. They are kind of the Hadoop of the language world: focus on just all the rigging and sails and keep departing for the same destination. There are people trying to work on identifying types, from the machine learning side, but it is a fascinating language problem: can we interpret documents knowing something about the concepts they contain, rather than just resorting to either a strict grammar (compilers) or structural extraction (scrapers).. ?
I agree that performance is just one of many factors you should take into account but since it’s one of the easiest ones to measure, many people rely on this single one. And this, as you say, it’s a mistake
I am a loud complainer when compilation or builds take too long, so I understand it, but the problem is the other language problems do not have this same constraint. If I am going to find things in web pages for instance, doing one or more IRs (intermediate representations) to be able to reason about it is not a bad thing.
Hi Federico,
I really like the “let’s keep it minimal”-angle of this blog and DSL implementation. From what I see here, I think e.g. a JavaScript/TypeScript implementation would not need to be significantly larger or worse, so it would be interesting to do the same thing in that ecology.
Thanks for the pingback to my blog. By the way: that didn’t intend to commit LWBs to the trash, just to discuss how they could be the right tool more often.
Also, I think it would be interesting to implement the same language using projectional editing. That would also conveniently excise the need to choose for any particular parsing library 😉
Well, Kotlin can also compile to JavaScript, so it could be something nice to explore, also considering that ANTLR can target both Java and JavaScript.
Regarding projectional editing, I would love to see a lightweight solution. Also, if it could run in the browser it would be a big plus.
Indeed, an “MPS in the browser” would be awesome, and would probably need to be sufficiently light-weight by nature of running in the browser.