
Have you ever thought about applying watermarks to your models? Well, maybe you should!. Here we explain to you why and how to watermark your models (paper to be published in the IEEE Access journal, keep reading for a summary or get the full paper pdf).
Intellectual property management for modeling artefacts
Indeed, collaborative development scenarios often require models to be shared among the different stakeholders. These stakeholders are mostly remote with communication typically taking place over untrusted networks. This raises the need for effective intellectual property (IP) protection mechanisms for the shared models. Systems are more and more complex every day and often integrate IoT components, AI, Big data, and other heterogeneous subsystems. As a result, outsourcing parts of the system design process becomes a necessity. This is also becoming true for digital assets in what constitutes a paradigm shift towards the model-driven co-engineering of systems design (e.g. using Collaboro). In such scenarios, a given model, finished or under construction, may be shared among different stakeholders what could lead to the leak of IP, likely triggering reputation and/or economical losses.
Access-control mechanisms for MDE prevent unauthorized users to access the models but they alone do not suffice to deal with the problems derived from the intentional or unintentional leaks of IP from authorized parties. A mechanism for detection and tracking of IP, providing prosecution evidence for legal purposes, is needed as well. In order to tackle this problem, we propose here the integration of digital watermarking techniques in the model-driven engineering development cycle.
Digital watermarking is an information hiding technique used to verify the authenticity, integrity and ownership of digital assets by means of the introduction of imperceptible marks into them. This technique has been extensively exploited in the domains of digital images, video and audio for IP protection purposes. However, the approaches developed for those media domains, based on the existence of static and highly noise-tolerant information, can not be directly applied to other non-media domains, that are much less noise-tolerant and where data modifications stemming from normal usage are common. Thus, some specific techniques have been provided for non-media data domains such as relational databases, XML documents or graphs.
The strategies developed for non-media watermarking approaches usually rely on two key assumptions: 1) the existence of identifiers to uniquely label the parts of the data (i.e., tuples in database relations, nodes or edges in graphs, etc) that may be subject to watermarking; and 2) the possibility of modifying some of the identified data. In practice, in order to deal with the first assumption, they rely on the use of immutable identifiers (such as primary keys), external identifiers, or the availability of numerical data (to rely upon the persistence of their most significant bits to obtain robustness against data modifications). As for the second assumption, they rely on the existence of numerical data as well, so that the watermark can be introduced in their least significant bits.
A watermarking technique for models
Unfortunately, models do not adapt well to the previous assumptions. This is so for three main reasons: first, identifiers, when they exist, do not enforce referential integrity nor characterize the model element data and structure, making them easy to attack (by modification or re-generation) without impacting the usability of the model; second, numerical data is typically scarce or even absent; and three, although certain application domains do allow the introduction of slightly arbitrary modifications in the model data, this is not the most common scenario due to the precise required semantics that models must satisfy. Especially true for metamodels that are intended to provide precise meaning to their instance models.
To create a watermarking system for MDE we need first to consider the following three questions:
What is the unit of data protection?
To answer this question we need to determine which information is the most relevant in a model. It is clear that classes (instances of EClass in M2) and objects (instances of class elements in M1) include both own data (attributes, operations) and are part of the model structure (via its references and relationships) and that both things need to be considered for IP protection. Then, our partition unit will be the model class/object. Smaller units (e.g. operations, attributes or references) do not contain much information alone and thus are not ideal candidates as partition unit.
How do we obtain unique and robust identifiers?
We have already highlighted that, in order to use the procedures provided for other non-media domains, we need a labelling mechanism to uniquely identify model elements that is able to resist attacks (such as id removal or regeneration) and data modifications to a certain degree. Current id mechanisms in existing modeling frameworks do not fulfill these requirements. Thus, we need to provide a novel labelling mechanism for models.
How do we mark?
Although some domain specific models may tolerate modifications well, generally MDE artifacts have a very low bandwidth, this is, they tolerate a very low number of modifications. Therefore, to watermark in MDE we have that:
- for the case where models tolerate modifications, and assuming we have the required labelling mechanism as mentioned above, we can directly use the procedures state-of-the-art watermarking algorithms together with basic data watermarking techniques (e.g., numeric, text and categorical data watermarking).
- for the general case, a modification of those procedures, so that they do not introduce distortions in data but extracts it called zero-watermarking is preferable.
The requirements highlighted by the aforementioned three questions are met in our work in order to enable the use of watermarking for IP protection on models.
A zero watermarking algorithm for models
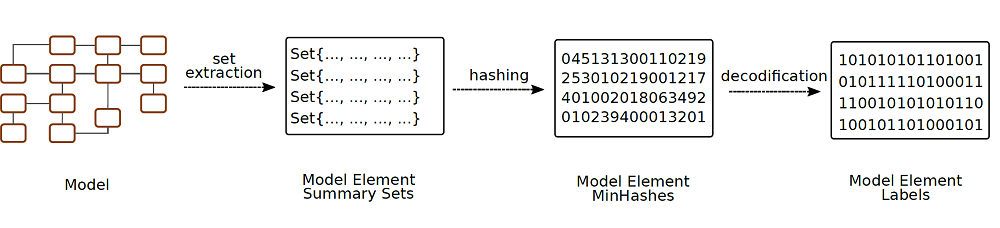
In particular, we contribute, first, a robust (i.e., resistant to data modification to a certain degree) labelling mechanism based in the use of locality sensitive hashing and error correction codes that uniquely identifies model elements with respect to (w.r.t.) their contents and position in the model structure (see Figure below). This labeling mechanism facilitates using in the model-driven field existing state-of-the-art watermarking algorithms for non-media data.

Secondly, our work contributes a zero-watermarking algorithm that benefits from the previous labelling mechanism in order to introduce a watermarking algorithm for models that does not introduce distortions to the data.
Our zero watermarking algorithm works by extracting a data pattern from the model that is then operated with the watermark data to obtain a key. In case of an IP conflict, this key, previously stored by a trusted authority, can be used to extract the watermark from a suspect model and allow stakeholders to determine its ownership without having to share the original model.
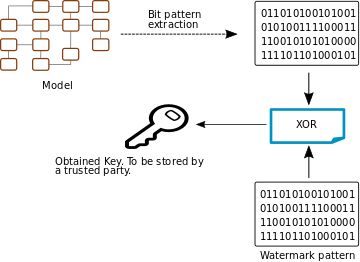
We have evaluated our labelling and zero watermarking algorithms and showed that in most cases we can recover the watermark even in the presence of a large number mutations with a high level of significance. By effectively integrating watermarking techniques in the MDE ecosystem, models can be safely contributed to collaborative projects as the intellectual property of the involved parties is protected.
Salvador Martínez Pérez currently works at CEA-List lab (Paris) in collaboration with the SOM Research lab (Barcelona). Salvador does research in Computer Security, Reliability, Software Engineering, Software Evolution and core Model-driven engineering. Their current project is ‘Model-based Reverse Engineering.’


Recent Comments