
There is a myriad of libraries, platforms and cloud-based services for Artificial Intelligence (AI). But directly programming your AI application on top of them makes your software too dependent upon the specific infrastructure you chose. This is dangerous in such a fast-paced environment where new (and better) AI solutions pop up every day.
How can you develop AI-enhanced software (also known as smart apps) or just pure AI components (neural networks, image recognition software, chatbots…) for a data science problem without learning each of the specific AI technologies and languages and preserving my ability to easily migrate my software over a new AI infrastructure? The solution won’t surprise my readers: modeling AI comes to the rescue.
By raising the abstraction level at what you define your AI needs, you can first focus on modeling the AI behaviour and later on refining it to integrate platform-specific details. Basically, model-driven engineering applied to AI. But don’t be mistaken, I’m not saying this just because I’m a “modeling maniac”. As you’ll see just now, this is the trend all AI providers are following now.
Let’s take a closer look at the best modeling AI tools I know (as we did for the opposite post: IA for modeling, this post is more of a way to structure my set of links and notes on this topic than a systematic and complete list of tools for AI and data science modeling). I try to cover several kinds of tools: from complete data science modeling to code-generation for AI.
Contents
AI visual modeling tools from the Big Tech players
The big players (Google, Amazon, Microsoft) are offering visual AI modeling environments as a way to bring more users to their Machine Learning solutions. They “sell” them as a kind of visual programming for machine learning or “machine learning without the code” to try to attract people interested in ML but scared of writing the code to create and train ML models. Of course, those models can then only be executed on the proprietary infrastructure of the respective vendor.
Azure Machine Learning Studio
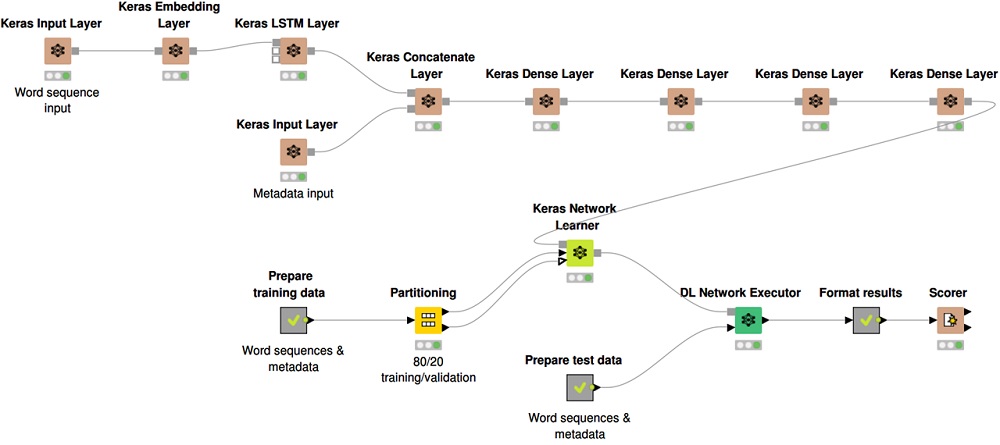
Azure Machine Learning includes the Azure Machine Learning Design Studio. You can use it to train and deploy machine learning models without writing any code. Drag and drop datasets and components to create ML pipelines.
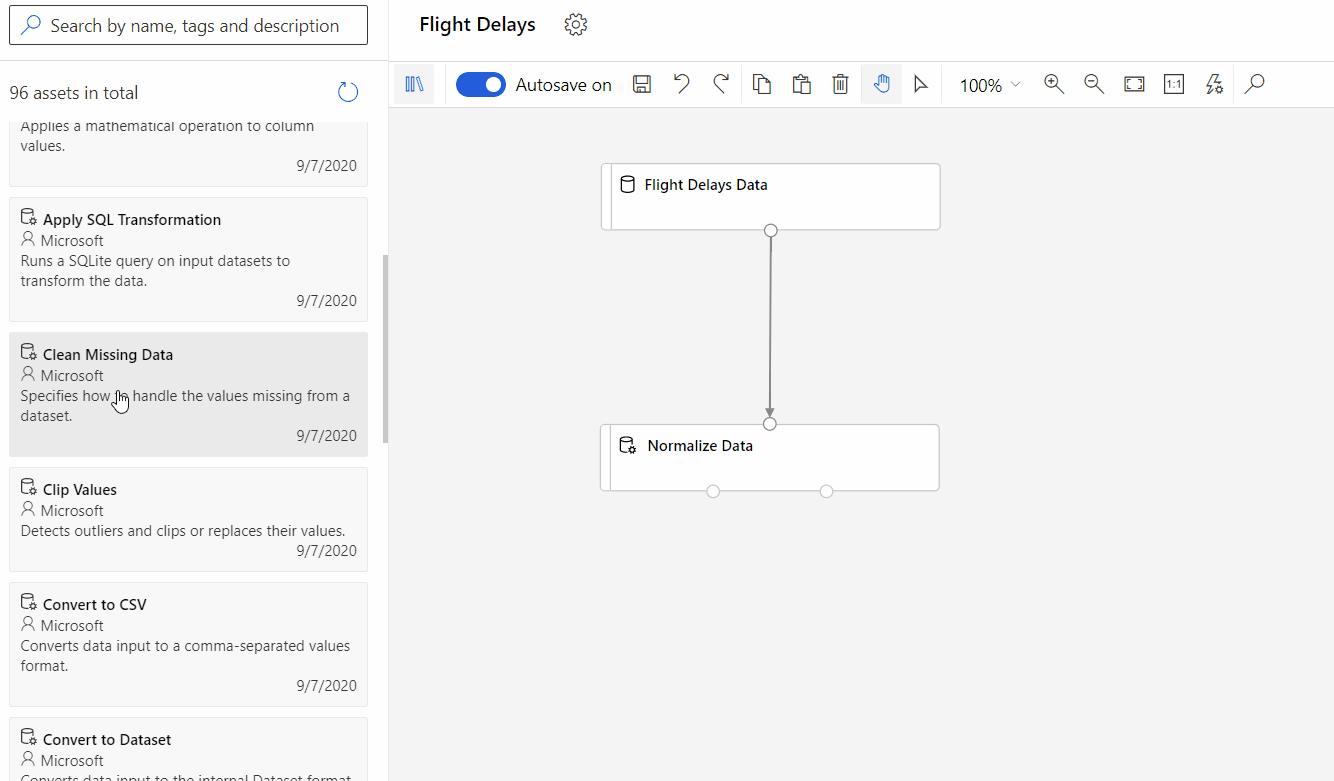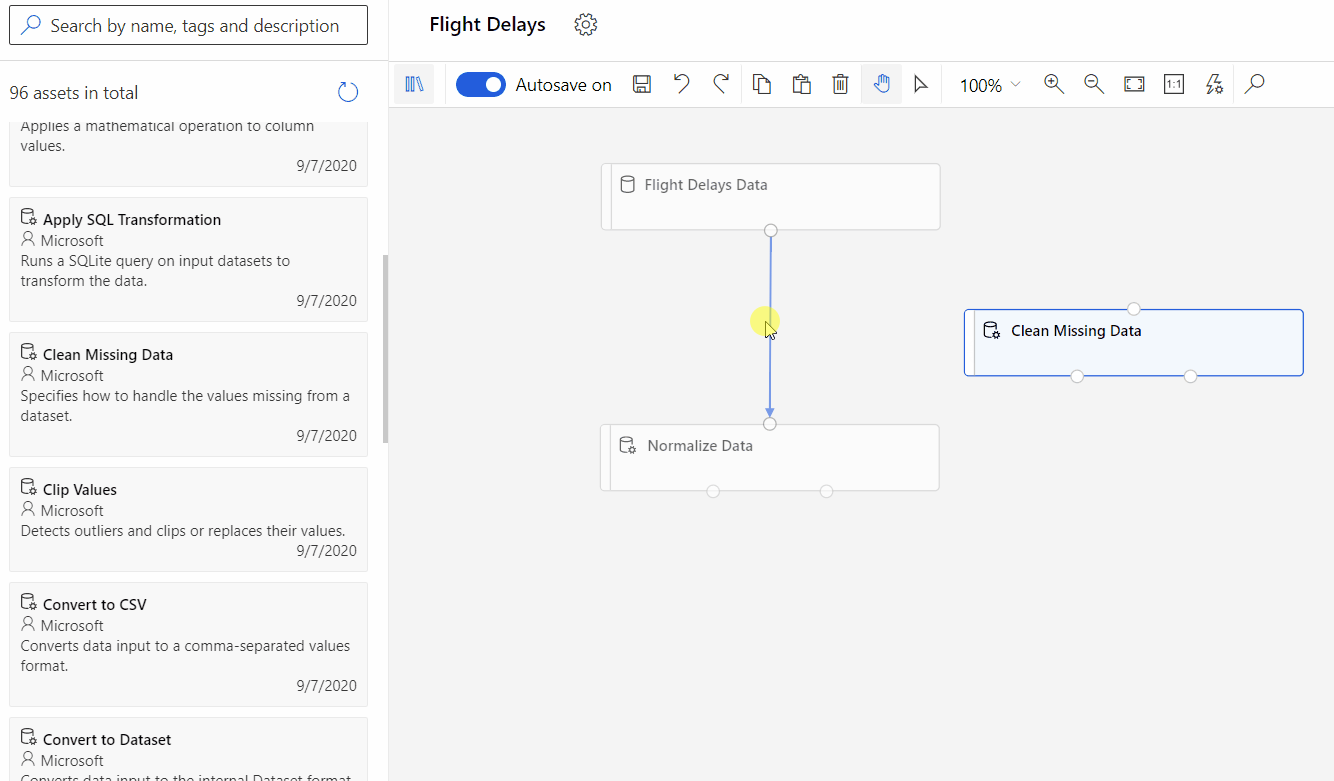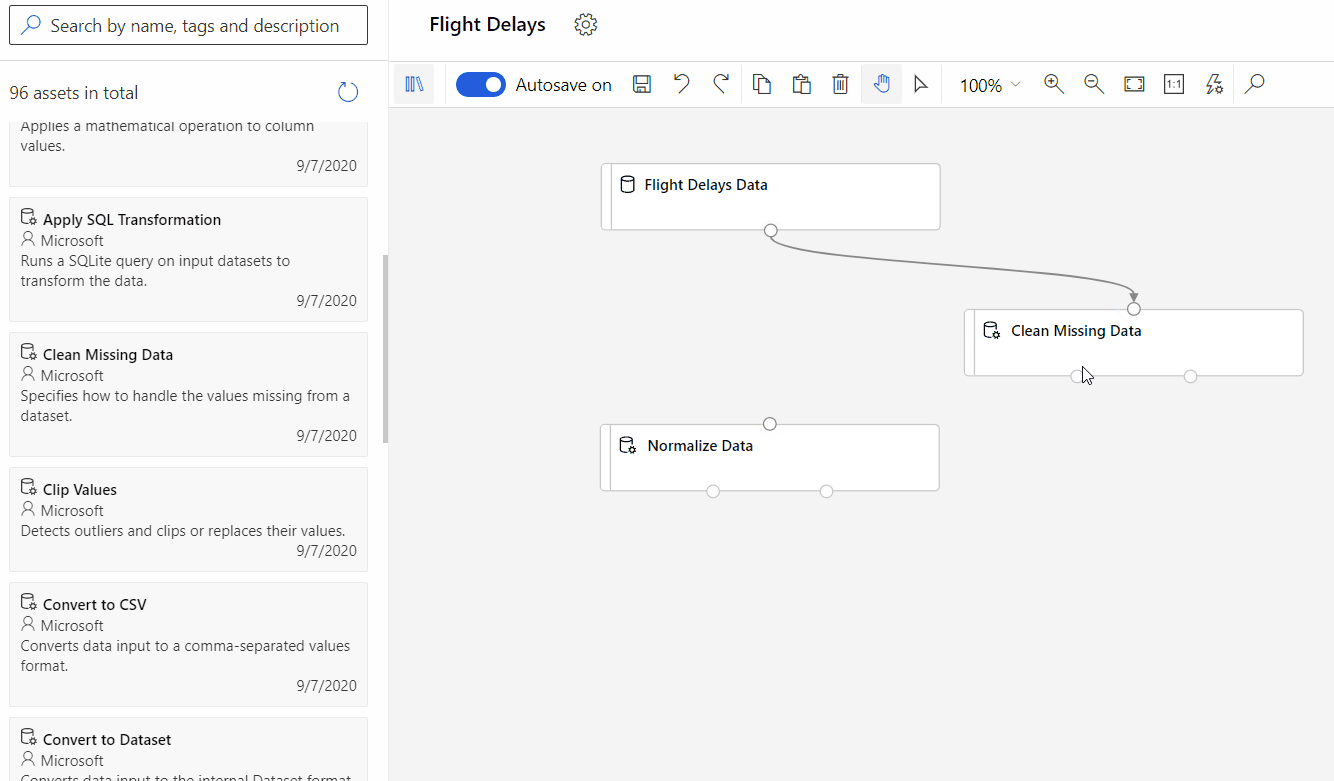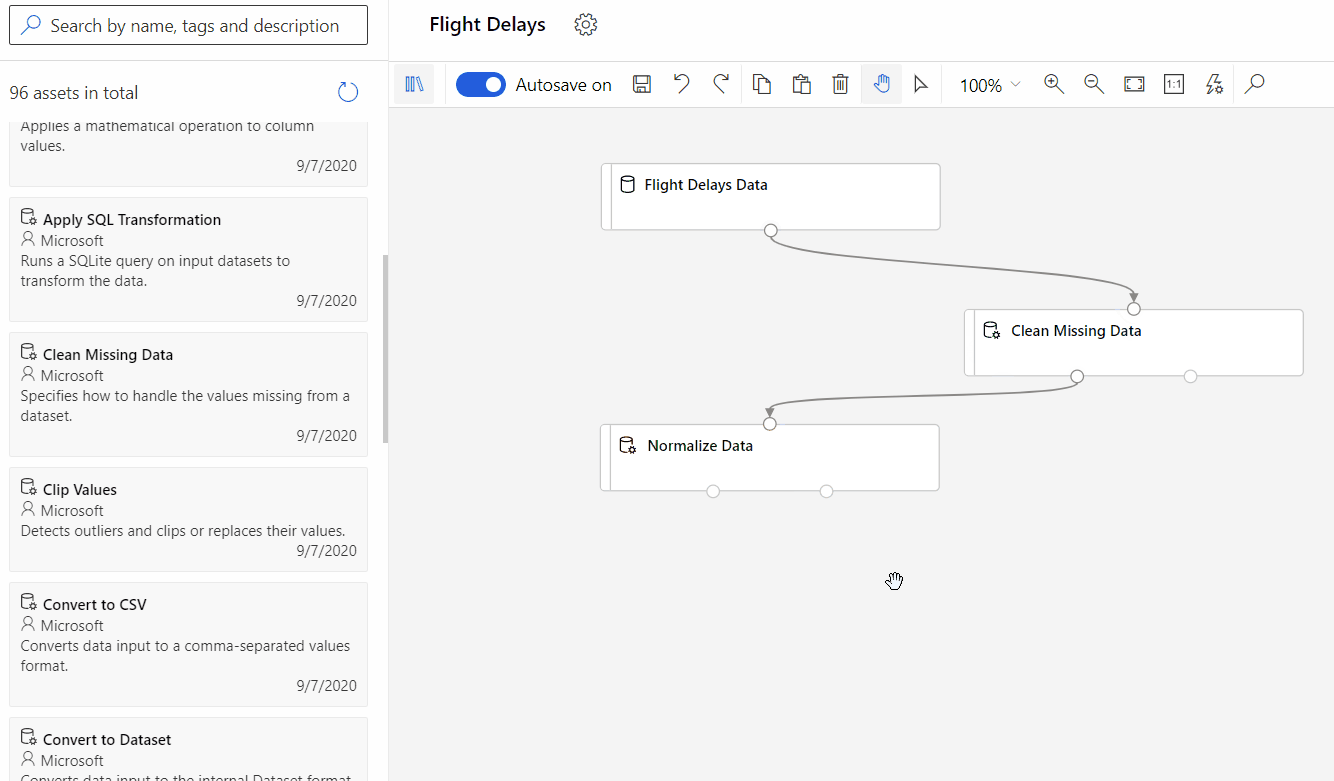
SPSS Modeler from IBM
The IBM alternative to the Azure ML Studio is the SPSS Modeler, part of the Watson Studio. Similar to the Microsoft competitor above, you can define your input data pipeline, the model you want to generate (classifier, predictive,…) and evaluate and visualize the quality of the results. It comes with complete algorithms and predefined models that are ready for immediate use to bootstrap your own data science application.
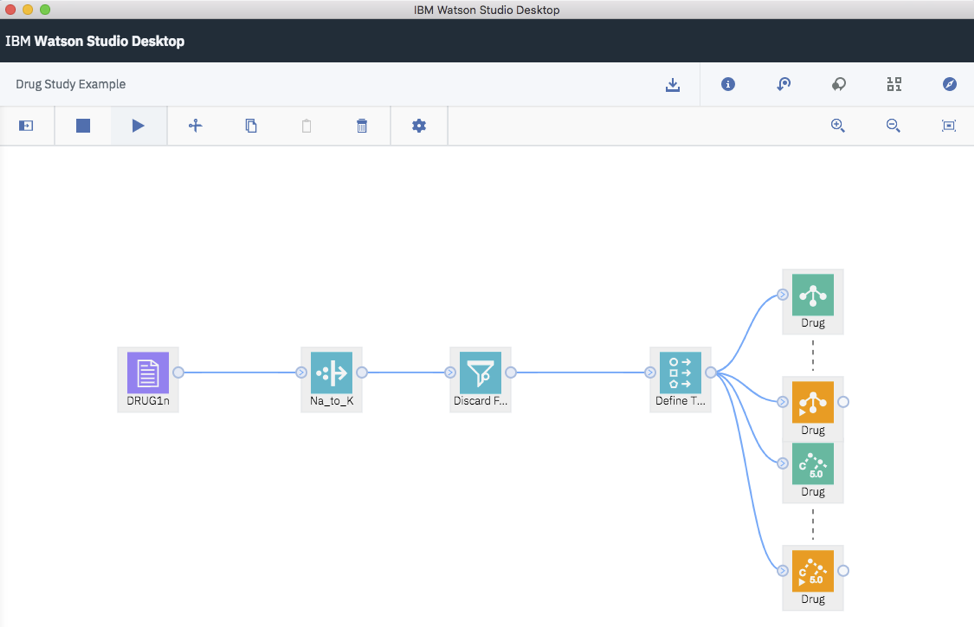
The closest solution from Amazon would be Amazon SageMaker, described as a “single, web-based visual interface where you can perform all ML development steps, improving data science team productivity by up to 10x”. The IDE itself may be visual but I’ve been unable to find a visual modeling AI editor for the ML part itself in it.
Data Science modeling environments
In Data Science, the data collection and processing aspect is as important as the learning / predictive process to perform on that data. The complexity of the data science resides many times in deciding what data to collect and what features of the data are the most relvevant ones for the prediction problem we want to address. Some data science tools provide their own runtime environment, but many come with built-in integrations with deep learning frameworks and libraries like Keras or Tensorflow.
RapidMiner
RapidMiner comes with a visual workflow designer to accelerate the prototyping and validation of predictive models, with predefined connections (including many for data acquisition, RapidMiner includes over 60 file types and formats for structured and unstructured data), built-in templates and repeatable workflows.

Orange
Orange is an open source machine learning and data visualization toolkit. Data analysis is done by linking widgets in workflows. Each widget may embed some data retrieval, preprocessing, visualization, modeling or evaluation tasks. A considerable number of predefined widgets are available but you can also build your own.

Knime
My favorite option for small/medium companies. Knime is a generic data analytics platform that can be used for a multitude of tasks. Knime comes with over 2000 different types of nodes to cover all your needs. The Knime for data scientists and Knime for deep learning extensions are the most interesting ones for the topic of this post. For instance, the latter allows users to read, create, edit, train, and execute deep neural networks. Since all nodes can be combined, you can easily use the deep learning nodes as part of any other kind of data analytic project.
On top of this, Knime is open source and free (you can create and buy commercial add-ons).
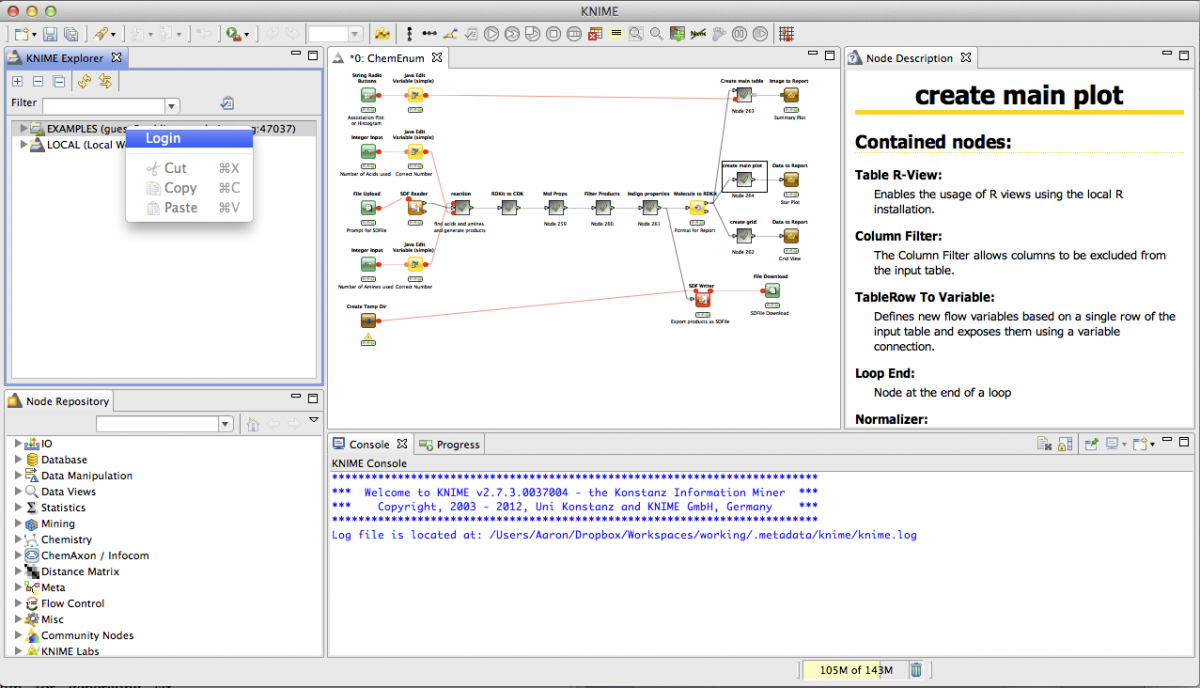
Note that besides these data science tools, other generics environments are getting data science extensions. An example would be Neuron , a data science extension for Visual Studio Code.
Dataiku
More oriented towards large enterprises, Dataiku aims to bring together everybody playing a role in a data science project (business analyst, data science, data engineer,…) in one single platform. Dataiku integrates with a large number of other tools, from notebooks to chart libraries for data visualization and of course all major ML libraries.
Once you’ve set up the pipeline, you can bundle it as a single deployable package for real-time predictions via a REST API.
No-code AI solutions
We also start to see no-code tools for AI where more than a fully expressive solution we have some predefined AI templates/scenarios we can then configure and adapt to our needs. For this same reason, most of these options are not generic but targeting a specific domain or technology. A few interesting exceptions try to provide a more domain-agnostic environment where you can drop the data you want to learn from and ask the tool to automatically train a custom machine learning model from those examples. This model can then be typically exported to a format compatible with Tensorflow, PyTorch,…
Within this general no-code for AI category I would include:
Both have the benefit that you can integrate them with other no-code tools in those same companies to build complete business applications with some “intelligence” in it.
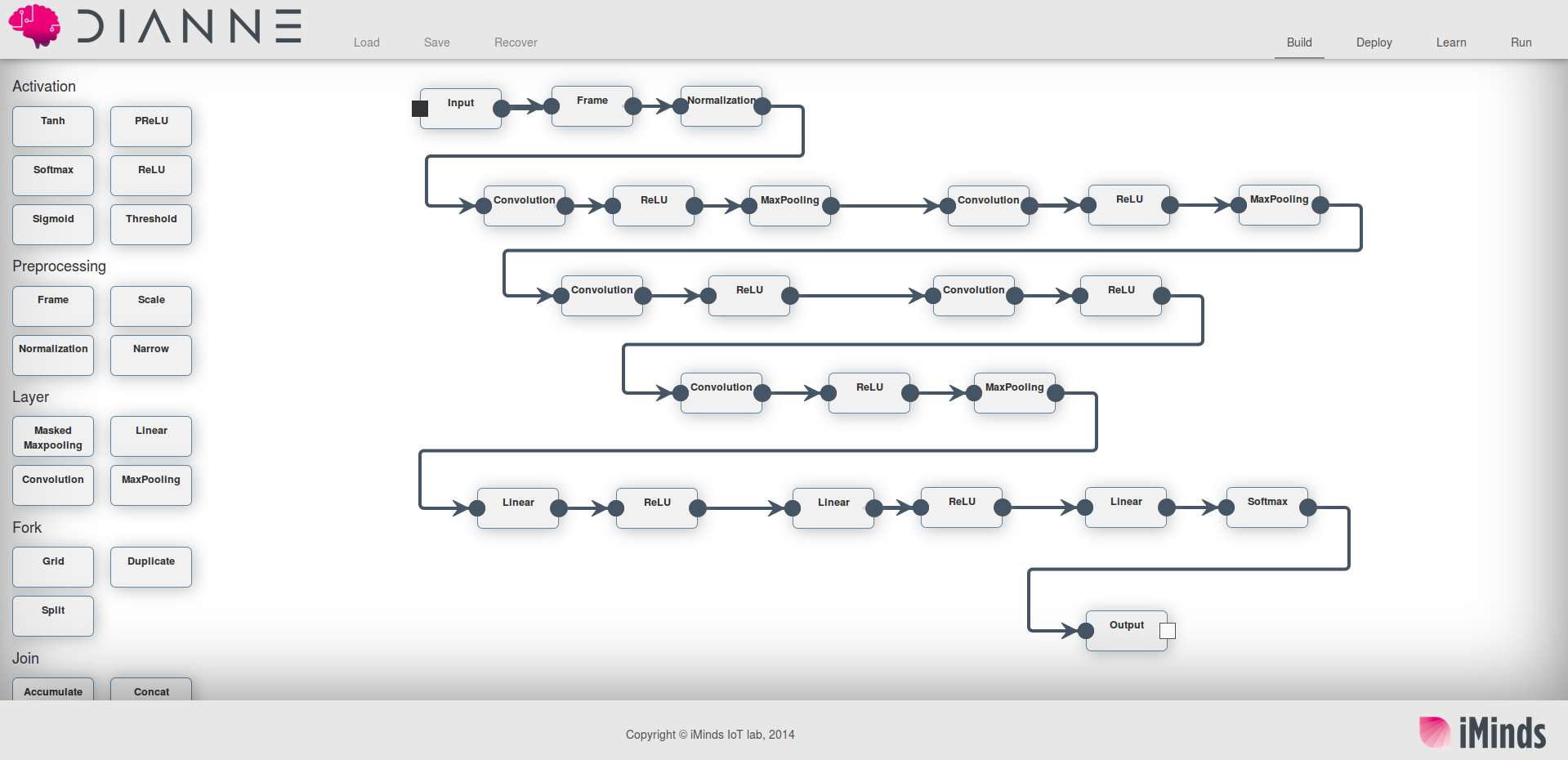
Modeling neural networks
If your main interest is the modeling of neural network itself, DIANNE is a good option. In Dianne, neural networks are built as a directed graph. DIANNE comes with a web-based UI builder to drag-and-drop neural network modules and link them together.
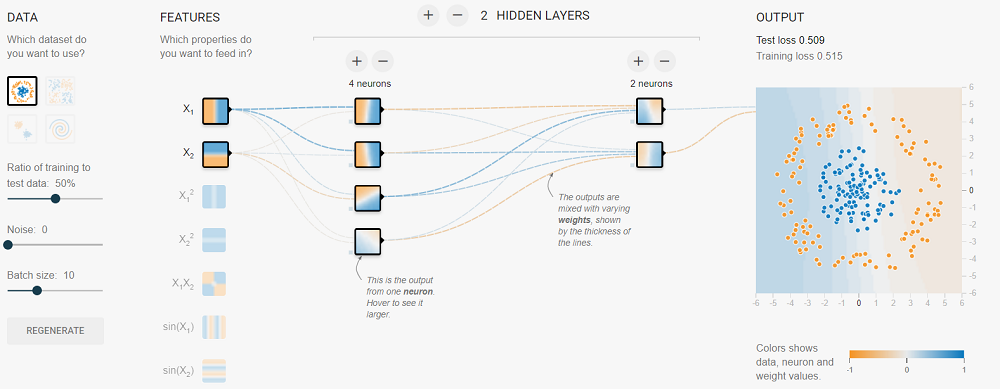
To learn how neural networks work, this Tensorflow playground is ideal to play with neural networks and learn its basic concepts
Visualizing the learned models
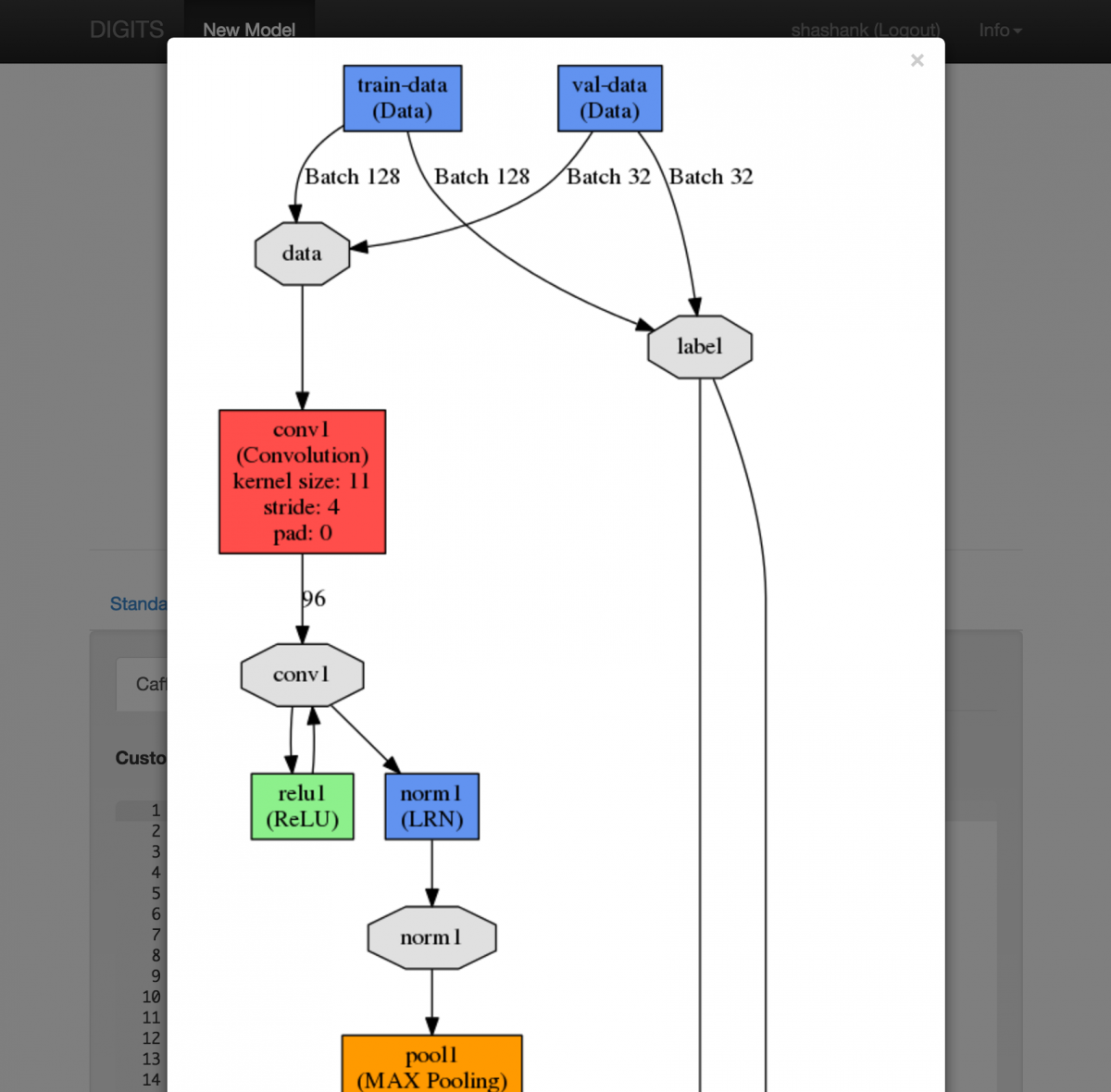
Some tools focus on the visualization of the results, as a way to help you understand the quality of the deep learning model you created. As an example, TensorBoard is a suite of web applications for inspecting TensorFlow runs. Nvidia builds on top of TensorBoard to visualize deep neural networks in its Nvidia Digits tool.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Hi Jordi,
thank you for that interesting overview. I was wondering, is there a modelling approach amongst these tools with the potential of becoming an open standard in the nearer future, or is it still too early to think of such things? (after all, such ideas have been around since the first wave of neural networks, long ago)
Probably the standard will come first as a response to the need to reuse the ML models and enable the interoperability of the tools (in fact there are already steps in this direction). I hope the modeling part will come as an evolution of that
Hi Jordi, thank you for mentioning GeneXus.
Since you in some part also mentioned chatbots, it may be worth to mention that GeneXus also has a chatbot generator: https://wiki.genexus.com/commwiki/servlet/wiki?37102,Chatbot+generator (Using GeneXus, the developer creates the conversational flow diagrams, and GeneXus creates a –customizable– UI for the chat, and the conversational AI model in IBM Watson or DialogFlow. Support for other providers is upcoming. The developer then also integrates this chatbot with the whole solution to create one with hybrid-ui, etc).
Regards, Armin
It seems that some initiatives exists for standardization of ML description aiming at interoperability between ML tools.
The Data Mining Group (DMG) is proposing a “schema” for exchanging trained (predictive) models and allows them to eventually be transferred on different tools and architecture: PMML (http://dmg.org/pmml/v4-3/GeneralStructure.html). PMML supports description of neural networks, naive Bayesian classifiers, regression tree, etc.
The DMG proposes a sequel to PMML, using JSON instead of XML, called Portable Format Analytics, PFA (http://dmg.org/pfa/index.html) which aims at being a standard for exchanging analytics workflows and statistical models. In my institutions, my colleagues (in data analytics) only “played” with PMML.
If you consider only Neutral Networks, ONNX (https://github.com/onnx/onnx) is also a potential candidate..
Hello Jordi,
thank you for mentioning these tools. These tools will be addressed in Machine Learning classes.
Libraries arent aplications or install able software, they have to be implemented somehow, compiled and that isnt easy, heavy coding capabilities install requerements and resources on performance based hardware, as requred packages. And the one have to build all dependencies arround in order to get it to work mostly in CLI. There is no open source complete ANN-AI solutions to install and use with workflow input/test/train/evaluate/forecast in order to learn se what and how and how not to use it. U re stopped at wery begining. As for visual programming, there is some veird logic behind it and beyond posted tuts workflows there is questionable use of as u dont exactly what is happening behind. And one get “dont know excatly what” results. Orange fetures scikit-learn as full NN feature, but with it u cant forecast at least doesnt work for me with posted workflows that i have found, also not binary data friendly, no where tuts in detail how and what, very poor support. The logic behind differs a lot when u compare orange, weka, knime and data miner, SAS, IBM (comercial expensive license), actual visual logic programming differs a lot. If u want efficient ANN to work for u have to do almost all by your self. Good luck with it.