

Existing modeling tools provide direct access to the most current version of a model but very limited support to inspect the model state in the past. This typically requires looking for a model version (usually stored in some kind of external versioning system like Git) roughly corresponding to the desired period and using it to manually retrieve the required data.This approximate answer is not enough in scenarios that require a more precise and immediate response to temporal queries like complex collaborative co-engineering processes or runtime models.
In this paper, we reuse well-known concepts from temporal languages to propose a temporal metamodeling framework, called TemporalEMF, that adds native temporal support for models. In our framework, models are automatically treated as temporal models and can be subjected to temporal queries to retrieve the model contents at different points in time. We have built our framework on top of the Eclipse Modeling Framework (EMF). Behind the scenes, the history of a model is transparently stored in a NoSQL database.
The paper has been co-authored by myself, Jordi Cabot and Manuel Wimmer and will be presented at the next ER Conference. Keep reading to know more about the approach or download the temporalEMF paper in pdf.
1 Introduction to temporal models
Modeling tools and frameworks have improved drastically during the last decade due to the maturation of metamodeling concepts and techniques [8]. A concern which did not yet receive enough attention is the temporal aspect of metamodels and their corresponding models. Thus, existing modeling tools provide direct access to the most current version of a model, but very limited support to inspect the model state at specific past time periods [5, 7]. This typically requires looking for a model version stored in some kind of model repository roughly corresponding to that time period and using it to manually retrieve the required data. This approximate answer is not enough in scenarios that require a more precise and immediate response to temporal queries like complex collaborative co-engineering processes (to track model changes) or runtime models (to store historical or simulation data) [19].
To deal with these new scenarios, temporal language support must be introduced as well as an infrastructure to efficiently manage the representation of both historical and current model information. Furthermore, query means are required to access historical model information in order to validate the evolution of a model, to find interesting modeling states as well as execution states. Using existing technology to tackle these requirements is not satisfactory as we discussed later in the paper.
In order to tackle these limitations, we reuse well-known concepts from temporal languages to propose a temporal metamodeling framework, called TemporalEMF, that adds native temporal support for models. In TemporalEMF, models are automatically treated as temporal models and temporal query support allows to retrieve model elements at different points in time. Our framework is realized on top of the Eclipse Modeling Framework (EMF) [23]. In order to support large evolving models, the history of a model is transparently stored in a NoSQL database. We evaluate the resulting TemporalEMF framework with an Industry 4.0 case study about a production system simulator [18]. The results show a good scalability of storing and accessing temporal models without requiring changes to the syntax and semantics of the simulator. Thus, our contribution is three-fold:
- We present a light-weight extension of current metamodeling standards to build a temporal metamodeling
- We introduce an infrastructure to manage temporal models by combining EMF and HBase [24], an implementation of Google’s BigTable NoSQL storage [11].
- We outline a temporal query language to retrieve historical information from
Please note that all contributions are not changing the general way how models are used: if only the current state is of interest, the model is accessed and manipulated in the standard way as offered by the EMF in a completely transparent way. Thus, all existing tools are still applicable and the temporal extension is considered to be an add-on.
This paper is structured as follows. Section 2 gives an overview on how we introduce temporal modeling concepts in existing metamodeling standards. Section 3 presents our infrastructure based on a mapping of temporal models to a NoSQL database, and Section 4 continues with presenting the resulting prototypical implementation for the combination of the EMF and HBase. Our approach is evaluated through a case study in Section 5. Section 6 presents related work, while we conclude the paper with an outlook on future work in Section 7.
2. Temporal (Meta-)Modeling
In this section, we discuss how existing work on temporal modeling can be applied for temporal metamodeling. In particular, we introduce a profile for adding temporal concepts in existing metamodeling standards such as MOF and Ecore. Furthermore, we present an Industry 4.0 case which demands for temporal metamodeling in order to realize simulation and runtime requirements such as evaluating KPIs of production systems.
2.1 A Profile for Temporal (Meta-)Modeling
We propose a profile for augmenting existing metamodels with information about temporal aspects. Metamodels can be regarded as just a special kind of models [6], and therefore, existing work on temporal modeling for ER [14] and UML [10] languages can be easily leveraged to specify arbitrary temporal (meta)models. Thus, we base our temporal (meta)modeling profile on these previous works for the static parts of the model and extend them to cover behavioral definitions which are of particular interested if executable metamodels are used.
Figure 1 introduces the profile for augmenting metamodels with temporal concerns in EMF Profiles notation. EMF Profiles [17] is a generalization of UML Profiles. As with UML Profiles, stereotypes are defined for predefined metaclasses and represent a way to provide lightweight extensions for modeling languages without requiring any changes to the technological infrastructure. However, in contrast to UML Profiles, EMF Profiles allow defining profiles for any kind of modeling language.
The profile in Figure 1 includes the stereotype Temporal (inspired from previous work on temporal UML [10]) combined with its durability and frequency properties to classify (meta)classes as instantaneous, durable, permanent or constant. We also introduce novel stereotypes for annotating the operations as we consider executable metamodels. We want to define special operations for which their calls are logged or vacuumed. The former requires to keep a trace of all executions of the operation. The later forces to restart from scratch the lifespan of the modeling elements deleting their complete previous history. This should be obviously used with caution as it defeats the purpose of having the temporal annotations in the first place but it may be necessary in scenarios where runtime models are used for simulation purposes and we want to restart that simulation using a clean slate. Furthermore, it may help in managing the size of temporal models which may attach an extensive history where only the last periods are of interest.
Similarly, we have also adapted previous works on the specification of temporal expressions [10, 12, 16, 22, 25] to provide temporal OCL-based query support on top of our temporal infrastructure. Before we show an application of the profile and query support, we introduce the motivating and running example of this paper.

Fig. 1: Profile for Temporal (Meta-)Modeling.
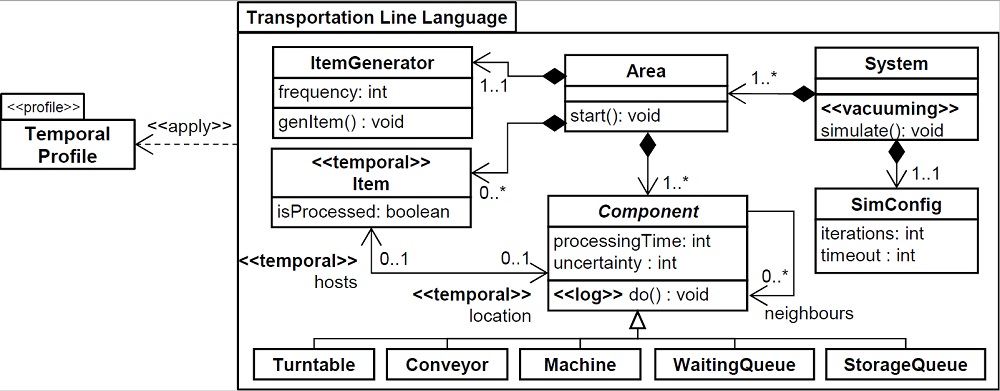
Fig. 2: Applying the Temporal Profile for a Transportation Line Modeling Language
2.2 Motivating and Running Example: Transportation Line Modeling Language
The motivating example, also used as running example for the paper, is taken from the research project CDL-MINTa carried out by TU Wien. The main goal is to investigate the application of modeling techniques in the domain of smart production systems. The example is about designing transportation lines made up of sets of turntables, conveyors, and multi-purpose machines. Such components are composed in so-called production areas. The production plant is supposed to continuously processes items by its multi- purpose machines located in one of the areas. Turntables and conveyors are in charge of moving such items to these machines. Given a particular design for a transportation line, simulations are needed for computing different KPIs such as utilization, throughput, cycle times, etc., in order to validate if certain requirements are actually met by a particular design.
The metamodel of the transportation line modeling language is shown on the top of Figure 2. Please note that there are also stereotype applications of our proposed temporal profile illustrated which will be explained in more detail in the subsequent subsection.
In the metamodel, System is the root class, which is composed of several Areas. The system can have associated a SimConfig, where parameters of the simulation can be specified, e.g., the simulation time or number of iterations. An area, in turn, can contain any number of Components. As we see, there are seven types of Components, namely Conveyor, Machine, Turntable, ItemGenerator, StorageQueue, and WaitingQueue. Items are created by ItemGenerators and are moved along the transportation line by starting their way in the area’s associated WaitingQueue. On their way, they may serve as input to Machines. Those items that complete the transportation line successfully, should end up in a StorageQueue.
2.1 Applying the Temporal Profile to the Transportation Line Modeling Language
In Figure 2, we also provide an application example of the introduced temporal profile. In particular, we mark the class Item as Temporal as instances of this class are created dur- ing runtime which should be tracked in the history of the model. Furthermore, not only the items, but also their assignment to particular locations should be tracked. For this, we also annotate the bi-directional reference between Item and Component. In order to understand which component is activated in a particular point in time, we annotate the do() operation with the Log stereotype. Finally, in order to create a fresh state when a simulation run is started, we annotate the simulation() operation with the Vacuuming stereotype.
Having the class Item marked as a temporal element as well as the involved references, we are now able to define several queries (Qs) to compute execution states of interest – such as those needed for provenance – as well as KPIs – such as utilization:
- Q1 — Find all items which have been processed by machine m.
- Q2 — Find the components which had an item assigned at a particular point in time.
- Q3 — Find the components which had an item assigned within a particular time frame.
- Q4 — Compute the utilization of machine e for the whole system execution lifecycle.
Query Q1 retrieves the complete evolution of a structural feature, namely the hosts reference. Q2 accesses the hosts reference for a particular point in time, while Q3 is evaluating this reference for any particular moment between two time instants. Finally, Q4 is performing a complex query which is also requiring the access of the time values for having items assigned and not having items assigned.
3 Approach
Enabling a temporal metamodeling language as the one discussed above requires a temporal modeling infrastructure. In this section, we introduce the core concepts of our solution, based on the use of a key-value NoSQL mechanism to store the model historical data. Next section gives additional technical details on how this solution has been implemented.
In a previous work [13], we discussed why NoSQL data stores and, more concretely, map-based (i.e. key-value) stores are especially well-suited to persist models managed by (meta-)modeling frameworks since map-based stores are very well aligned with the typical fine-grained APIs offered by modeling frameworks (that mostly force individual access to model elements, even when the user aims to query a large subset of the model). Alternative mechanisms like in-memory or XML-based failed to scale when dealing with large models as it typically happens when working on, for instance, building information models (BIMs), modernization projects involving the model-based reengineering of industrial legacy systems or on simulation scenarios. This is also true for relational databases (even temporal ones, a direction they are all following in compliance with the SQL:2011 standard) mainly due to the lack of alignment with modeling tools APIs.
A specially interesting map-based solution is BigTable [11], defined as a column- based, sparse, distributed, persistent multi-dimensional sorted map. This map is indexed by a row key, column key, and a timestamp. The native presence of timestamps together with the benefits of map-based solutions to store large models make a BigTable-like solution an ideal candidate for a temporal modeling infrastructure.
Next subsections describe BigTable main concepts and how we adapt them to transform BigTable (and, in general, similar column-based solutions) into a temporal modeling infrastructure able to automatically persist and manage (meta)models annotated with our profile.
3.1 BigTable Basics
BigTable [11] is the Google’s proposal for a distributed, scalable, versioned and non- relational big data store; where data is stored in tables, which are sparse, distributed, persistent, and multi-dimensional sorted maps. The top-level organization unit for data in BigTable are named tables; and within a table, data is stored in rows, which are identified by their row key. Data within a row is grouped by column families, which are defined at table creation. All rows in a table have the same column families, although a row does not need to store data in all of them. Data within a column family is addressed via its column qualifier; which, on the contrary, do not need to be specified in advance nor be consistent between rows. A combination of row key, column family, and column qualifier uniquely identifies a cell. Cells do not have a data type and store raw data which is always treated as a byte[]. Values within a cell are versioned. Versions are identified by their version number, which by default is the timestamp of when the cell was written. If the timestamp is not specified for a read, the latest one is returned. The number of cell value versions retained by BigTable is configurable for each column family.
2.1 Column-based data model
Based on our previous work [13], we have defined a data model that flattens the typical graph structure expressed by models into a set of key-value mappings that fit the map- based data model of BigTable. Such data model takes advantage of unique identifiers that are assigned to each model object.
Fig. 3a shows a simplification of the production plant model for the case study presented in Section 2.2 that we will use as an example.
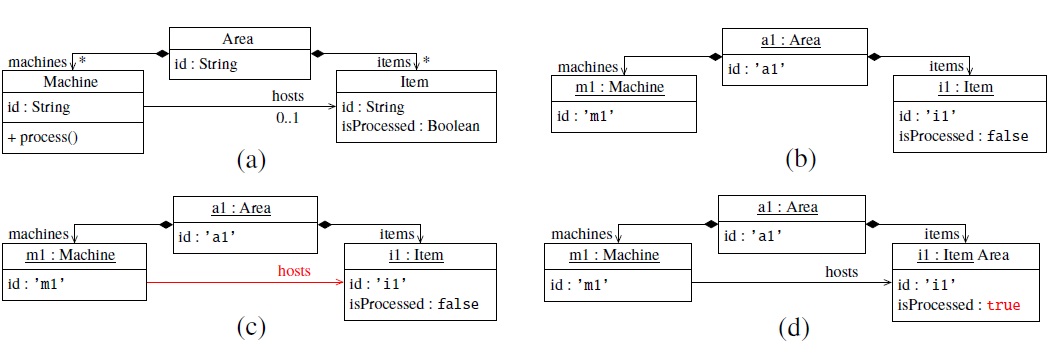
Fig. 3: Example model (3a) and sample instances at ti (3b), ti+1 (3b) and ti+2 (3b)
The figure describes a production system (omitted for the sake of simplicity) with a single Area with machines, which in turn, host and process – one by one – a set of items that are fed into the production system. Figs. 3b, 3c and 3d, present three instances of this model in three different consecutive instants. Fig. 3b represents an area a1, at a given moment in time ti, with one machine m1, and one unprocessed item i1. Fig. 3c represents the same area at time ti+1, when item i1 – which is ready to be processed – is fed into m1. Finally, Fig. 3d represents the area at time ti+2, once m1 has processed i1, thus changing the isProcessed status to true.
Our proposed data model uses a single table with three column families to store models’ information: (i) a property column family, that keeps all objects’ data stored together; (ii) a type column family, that tracks how objects interact with the meta-level (such as the instance of relationships); and (iii) a containment column family, that defines the models’ structure in terms of containment references. Table 1 shows how the sample instances in Figs. 3b, 3c and 3d are represented using this structure.
As Table 1 shows, row keys are the object unique identifier. The property column family stores the objects’ actual data. Observe that not all rows have a value for a given column (note that BigTable tables are sparse). How data is stored depends on the property type and cardinality (i.e., upper bound). For example, values for single-valued attributes (like the id, which is stored in the id column) are directly saved as a single literal value; while values for many-valued attributes are saved as an array of single literal values (Fig. 3 does not contain an example of this). Values for single-valued references, such as the hosts reference from Machine to Item, are stored as a single value (corresponding to the identifier of the referenced object). Finally, multi-valued references are stored as an array containing the literal identifiers of the referenced objects. Examples of this are the machines and items containment references, from Area to Machine and Item, respectively.
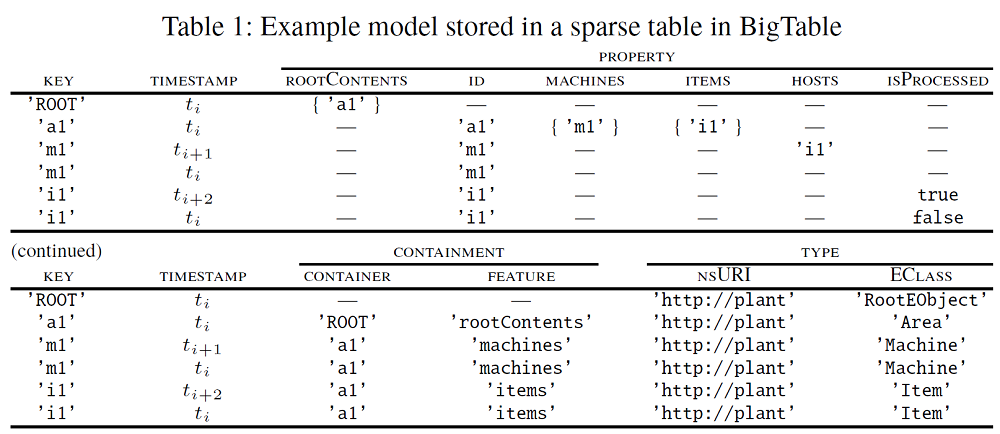
As it can be observed, the table keeps track of all current and past states of the model. At instant ti (cf. Fig. 3b), the model information is stored in rows (’ROOT’, ti), (’a1’, ti), (’m1’, ti) and (’i1’, ti). After setting the hosts reference at instant ti+1 (cf. Fig. 3c), the new (’m1’, ti+1) row – which supersedes (’m1’, ti) – is added. When the isProcessed property is changed (cf. Fig. 3d), the (’i1’, ti+2) row is added; and the last model state is stored in rows <’ROOT’, ti >, <’a1’, ti >, <’m1’, ti+1 > and <’i1’, ti+2 >. Note that our infrastructure is not bitemporal, we assume that valid-time and transaction- time are always equivalent.
The type column family groups the type information by means of the nsURI and EClass columns. For example, the table specifies the element a1 is an instance of the Area class of the Plant metamodel. Data stored in the type column family is immutable an never changes.
3.3 Query facilities
As mentioned in Section 2, several query temporal languages have been proposed before. Nevertheless, they all share the need to refer to the value of an attribute or an association at a certain (past) instant of time i in order to evaluate the temporal expressions [10](also known as temporal interpolation functions).
Based on this general requirement, we have built the “getAt(atDateTime)” method that returns the value of a feature (either an attribute or an association end) at a specific instant. For convenience, we also provide a getAllBetween(startDateTime, endDate- Time) method that returns a sorted map where the key of the map is the moment when the feature was updated, and the value is the value that was set at that specific moment within the given period.
TemporalEMF Architecture
We have built our temporal (meta-)modeling framework on top of Apache HBase [24], the most wide-spread open-source implementation of BigTable – based on our experience on building scalable, non-temporal model persistence solutions [4].
Figure 4 shows the high-level architecture of our proposal. It consists of a temporal model management interface – TemporalEMF – built on top of a regular model management interface – EMF [23]. These interfaces use a persistence manager in such a way that tools built over the temporal (meta)modeling framework would be unaware of it. The persistence manager communicates with the underlying database by a driver. In particular, we implement TemporalEMF as a persistence manager on top of HBase; but other persistence technologies as long as a proper driver is provided.
Thanks to our identifier-based data model, TemporalEMF offers lightweight on- demand loading and efficient garbage collection. Model changes are automatically reflected in the underlying storage, making changes visible to all the clients. To do so,
- (i) we decouple dependencies among objects taking advantage of the unique identifier assigned to all model objects. Afterwards,
- (ii) we implement lightweight on-demand loading and saving mechanisms for each live model object by creating a lightweight delegate object that is in charge of on-demand loading the element data and keeping track of the element’s state. Data is loaded/saved from/to the persistence backend by using the object’s unique identifier. Finally, and as explained in Section 3.2
- (iii) we implement a garbage collection-friendly data representation where we avoid to maintain hard references among model objects, so that the garbage collector can deallocate any model object that is not directly referenced by the application.
Our temporal modeling framework is designed as a simple persistence layer that adds temporal support maintaining the same semantics than the basic modeling framework it is based on (i.e., EMF). Modifications in models managed by our framework are directly propagated to the underlying storage. However, as in standard EMF, no thread-safety is guaranteed, and no transactional support is explicitly provided. Nevertheless, all ACID properties [15] are supported at the object level.
Our persistence layer has been implemented as an open-source prototype (available online at http://hdl.handle.net/20.500.12004/1/A/TEMF/001), and it can be plugged into any EMF-based tool to immediately provide enhanced temporal support.
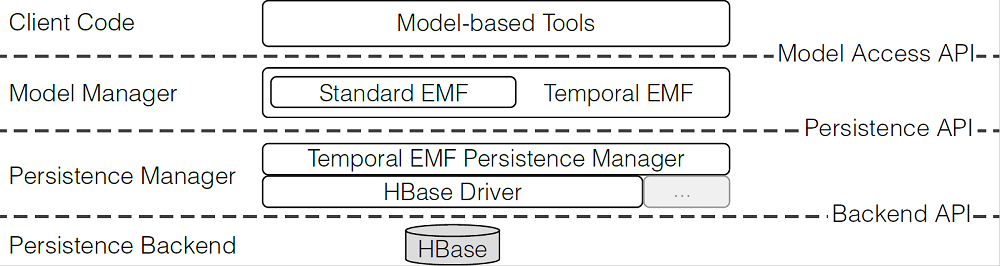
Fig. 4: Overview of the temporal model-persistence framework
5 Evaluation
We have performed experiments based on the guidelines for conducting empirical explanatory case studies [21]. The main goal is to evaluate the impact of the temporal extension for models on the performance as well as the capabilities of temporal queries in the context of model-based simulations. All the artifacts used in this evaluation and all the data we have gathered (either raw or processed) can be inspected at the temporal emf GitHub repo site. Read the full paper pdf version for a summary and interpretation of the results
6 Related Work
While there is abundant research works on temporal modeling languages in the literature to specify the temporal characteristics of the system data (e.g., consider [14] for a survey), ours is, as far as we know, the first fine-grained temporal metamodeling infrastructure, enabling the transparent and native tracking (and querying) of the system models themselves.
Closest approaches to ours are model versioning tools, focusing on storing models in model repositories such as SVN and Git using XMI serializations [1] as well as in database technologies such as relational databases, graph databases, or tuple stores [2]. Traditionally, each model version of an evolving model is stored as self-contained model instance together with a timestamp on when the instance as a whole was recorded in the versioning system. There is no temporal information at the model element level. Moreover, the versions are generated on demand depending on when the designer feels there are enough changes to justify a new version and not based on the temporal validity of the model. Therefore, reasoning on the history of specific elements with a sufficient degree of precision is barely impossible.
Trying to adapt versioning systems to mimic a temporal metamodeling infrastructure would trigger scalability issues as well. Storing full model states for each version is not efficient. Just consider changing one value between two model versions. This would result in mostly two identical models which have to be stored. This clearly shows that historical model information is currently not well supported by existing model repositories.
A second group of related work is the family of [email protected] approaches [3]. [email protected] refers to the runtime adaptation mechanisms that leverage software models to dynamically change the behaviour of the system based on a set of predefined conditions. While these approaches provide a modeling infrastructure to instantiate models, as we do, they do not store the history of those changes and only focus on the current state to steer the system. We find a similar situation with the group of works on model execution [9] that focus on representing complete model states but do not keep track of the evolution of those states unless the designer manually adds some temporal patterns [20] (e.g. the one in the previous section).
7 Conclusion
We have presented TemporalEMF, a temporal modeling infrastructure built on top of the Eclipse Modeling Framework. With TemporalEMF, conceptual schemas are automatically and transparently treated as temporal models and can be subjected to temporal queries to retrieve and compare the model contents at different points in time. An extension to the EMF query APIs allows modelers to easily express such temporal queries. TemporalEMF relies on HBase to provide an scalable persistence mechanism to store all past conceptual schema versions.
As further work, we would like to extend TemporalEMF in several directions. At the modeling level, we will predefine some useful temporal patterns to facilitate the defini- tion of temporal queries and operations. At the technical level, we will explore the integration of our temporal infrastructure in other types of NoSQL backends and web-based modeling environments to expand our potential user base. Finally, we aim to exploit the generated temporal information for a number of learning and predictive tasks to improve the user experience with modeling tools. For instance, we could classify users based on their typical modeling profile and dynamically adapt the tool based on that behaviour.
References
- Altmanninger, , Seidl, M., Wimmer, M.: A survey on model versioning approaches. IJWIS 5(3), 271–304 (2009)
- Barmpis, , Kolovos, D.S.: Comparative analysis of data persistence technologies for large- scale models. In: Proc. of Extreme Modeling Workshop. pp. 33–38 (2012)
- Bencomo, N., France, R.B., Cheng, B.H.C., Aßmann, (eds.): [email protected] – Foun- dations, Applications, and Roadmaps, LNCS, vol. 8378. Springer (2014)
- Benelallam, , Gómez, A., Tisi, M., Cabot, J.: Distributing relational model transformation on MapReduce. J. Syst. Softw. 142, 1 – 20 (2018), doi: 10.1016/j.jss.2018.04.014
- Benelallam, A., Hartmann, , Mouline, L., Fouquet, F., Bourcier, J., Barais, O., Traon, Y.L.: Raising time awareness in model-driven engineering: Vision paper. In: 20th ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, MODELS 2017, Austin, TX, USA, September 17-22, 2017. pp. 181–188 (2017)
- Bézivin, : On the unification power of models. Software and System Modeling 4(2), 171–188 (2005), doi: 10.1007/s10270-005-0079-0
- Bill, , Mazak, A., Wimmer, M., Vogel-Heuser, B.: On the need for temporal model reposito- ries. In: Seidl, M., Zschaler, S. (eds.) Software Technologies: Applications and Foundations. pp. 136–145. Springer International Publishing, Cham (2018)
- Brambilla, M., Cabot, J., Wimmer, M.: Model-Driven Software Engineering in Practice, 2nd Synthesis Lectures on Software Engineering, Morgan & Claypool Publishers (2017)
- Bryant, B.R., Gray, , Mernik, M., Clarke, P.J., France, R.B., Karsai, G.: Challenges and directions in formalizing the semantics of modeling languages. Comput. Sci. Inf. Syst. 8(2), 225–253 (2011)
- Cabot, J., Olivé, A., Teniente, E.: Representing temporal information in uml. In: Stevens, , Whittle, J., Booch, G. (eds.) «UML» 2003 – The Unified Modeling Language. Modeling Languages and Applications. pp. 44–59. Springer Berlin Heidelberg (2003)
- Chang, , Dean, J., Ghemawat, S., Hsieh, W.C., Wallach, D.A., Burrows, M., Chandra, T., Fikes, A., Gruber, R.E.: Bigtable: A distributed storage system for structured data. In: Pro- ceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation- Volume 7. pp. 15–15. OSDI ’06, USENIX Association, Berkeley, CA, USA (2006)
- Dou, W., Bianculli, D., Briand, L.: OCLR: A More Expressive, Pattern-Based Temporal extension of OCL. In: Cabot, J., Rubin, J. (eds.) Modelling Foundations and Applications. pp. 51–66. Springer International Publishing, Cham (2014)
- Gómez, A., Tisi, M., Sunyé, G., Cabot, J.: Map-based transparent persistence for very large models. In: Egyed, , Schaefer, I. (eds.) Fundamental Approaches to Software Engineering, LNCS, vol. 9033, pp. 19–34. Springer Berlin Heidelberg (2015)
- Gregersen, , Jensen, C.S.: Temporal entity-relationship models – A survey. IEEE Trans. Knowl. Data Eng. 11(3), 464–497 (1999), doi: 10.1109/69.774104
- Haerder, , Reuter, A.: Principles of transaction-oriented database recovery. ACM Comput. Surv. 15(4), 287–317 (Dec 1983), doi: 10.1145/289.291
- Kanso, B., Taha, : Temporal Constraint Support for OCL. In: Proc. of SLE. pp. 83–103 (2012)
- Langer, , Wieland, K., Wimmer, M., Cabot, J.: EMF profiles: A lightweight extension approach for EMF models. Journal of Object Technology 11(1), 1–29 (2012)
- Mazak, A., Wimmer, M., Patsuk-Boesch, : Reverse engineering of production processes based on markov chains. In: 2017 13th IEEE Conference on Automation Science and Engi- neering (CASE). pp. 680–686 (Aug 2017)
- Mazak, A., Wimmer, M.: Towards liquid models: An evolutionary modeling approach. In: of CBI. pp. 104–112 (2016)
- Meyers, B., Deshayes, R., Lucio, L., Syriani, E., Vangheluwe, , Wimmer, M.: ProMoBox: A Framework for Generating Domain-Specific Property Languages. In: Proc. of SLE. pp. 1–20 (2014)
- Runeson, , Höst, M.: Guidelines for Conducting and Reporting Case Study Research in Software Engineering. Empirical Software Engineering 14(2), 131–164 (2009)
- Soden, M., Eichler, H.: Temporal extensions of ocl revisited. In: Paige, F., Hartman, A., Rensink, A. (eds.) Model Driven Architecture – Foundations and Applications. pp. 190–205. Springer Berlin Heidelberg, Berlin, Heidelberg (2009)
- Steinberg, , Budinsky, F., Paternostro, M., Merks, E.: EMF: Eclipse Modeling Framework 2.0. Addison-Wesley Professional, 2nd edn. (2009), isbn: 0321331885
- The Apache Software Foundation: Apache HBase (2018), http://hbase.apache.org/ Ziemann, P., Gogolla, M.: OCL Extended with Temporal Logic. In: Broy, M., Zamulin, A.V. (eds.) Perspectives of System Informatics. pp. 351–357. Springer Berlin Heidelberg (2003)
I’m a Postdoctoral Researcher at SOM Research Team, in Barcelona. Currently, I’m involved in the development of scalable tools for MDE, especially in the persistence of Very Large Models.


Nice to see some work going beyond the level offered by EMF! Although EMF-based modeling tends to have little or no versioning, and only a very coarse level of granularity of time and model elements, that’s not necessarily the case in other modeling tools. (There seems to always be a danger in the academic world to think that modeling == EMF 🙂 ) Systemite’s SystemWeaver probably has the finest granularity, but for a more graphical tool our MetaEdit+ offers a fair amount: individual transactions (like each Save in a file-based tool) and down to individual property values for models, and individual symbol definitions and sub-generator definitions for metamodels. More details available on this very blog, https://modeling-languages.com/smart-model-versioning/, with a link to the final published paper in a comment.
Hi Steven, thanks for commenting! You’re right, normally we forget to mention other well-known tools that live out there of the EMF ecosystem. However, we refer to some approaches for model versioning (please forgive us for forgetting MetaEdit+, we had to shorten a lot the text to make it ft in the page limit), and indeed I’d like to say that what we’re doing in this work is not exactly model versioning (at least, not in the “classical” sense). In fact, model versioning is not even the goal of the work.
Normally, model versioning (or any other regular VCS) are based on snapshots (with any granularity) that need to be managed explicitly; but in our case we are just interested in keeping track of the whole model history as a “stream” of values, which is managed transparently. We do not intend to modify the semantics of EMF, we avoid to modify the EMF API as far as possible, and in fact, we do not support transactions natively. The point is just provide the minimum functionality (with a set of query facilities) on top of which you can just build whatever time-aware solution (such as model versioning, model comparison, etc.). Of course that can come at the cost of other disadvantages, but we are just exploring the field 🙂
In any case, I’m happy to know we are not alone in this research line 😉
Oh, absolutely – what you’re doing goes to far finer granularity than in MetaEdit+, and I’m interested to follow your progress! And I’m not worried if individual tools aren’t mentioned, just if there are blanket statements like “Existing modeling tools provide direct access to the most current version of a model but very limited support to inspect the model state in the past”. If you search you’ll find that a good percentage of the major tools offer more than “very limited support” – although it does take quite some time to do that search and verify the tool vendors’ claims.
I guess the levels of versioning granularity / temporal model information could be categorized as:
0) no tool support
1) tool support for manually-triggered coarse-granularity external VCS integration
2) internal tool support for automatic fine-granularity versions and history
3) automatic individual change histories per model element, determined by the metamodel (or meta-metamodel)
I guess base EMF is 0) and with suitable Eclipse plug-ins 1). MetaEdit+ is 1) and more importantly also 2), and that seems enough to support “complex collaborative co-engineering processes (to track model changes)”. To support “runtime models (to store historical or simulation data)” you need 3), i.e. your work.
For a bit of ancient history: there was a Master’s thesis by Ari Pyykkö in 1994 (sadly in Finnish) which produced a design for individual version histories of objects in MetaEdit+. It was never implemented, partly because there were still some design-level issues, and partly because there’s only so much you can do in one research project, particularly back then on 386s with 12MB of memory :D.