

Checking the correctness of a UML/OCL model is a complex problem and, in general, undecidable. This has forced existing tools for UML/OCL analysis (like our own EMFtoCSP tool) to accept a series of trade-offs: reducing the expressiveness of the modeling language; performing an incomplete search; requiring user guidance to conduct the verification; or, finally, limiting the search space. See a more detailed comparison of all these approaches in this survey.
Bounded verification detects faults efficiently but, on the other hand, the absence of faults does not guarantee a correct behavior outside the bounded domain. Hence, choosing suitable bounds is a non-trivial process as there is a trade-off between the verification time (faster for smaller domains) and the confidence in the result (better for larger domains).
Unfortunately, existing tools provide little support for this choice. In this paper (free pdf version), we present a technique that can be used to:
- automatically infer verification bounds whenever possible,
- tighten a set of bounds proposed by the user and
- guide the user in the bound selection process.
This approach may increase the usability of UML/OCL bounded verification tools and improve the efficiency of the verification process.
So, basically, we move from this verification process:

to this one:

where our technique suggests potentially good bounds on behalf of the user by means of a series of size abstractions and bound propagations developed for OCL. These bounds can then be passed on the solver for a more efficient process. The following figure tries to describe the whole process in more detail (click on the figure to enlarge)
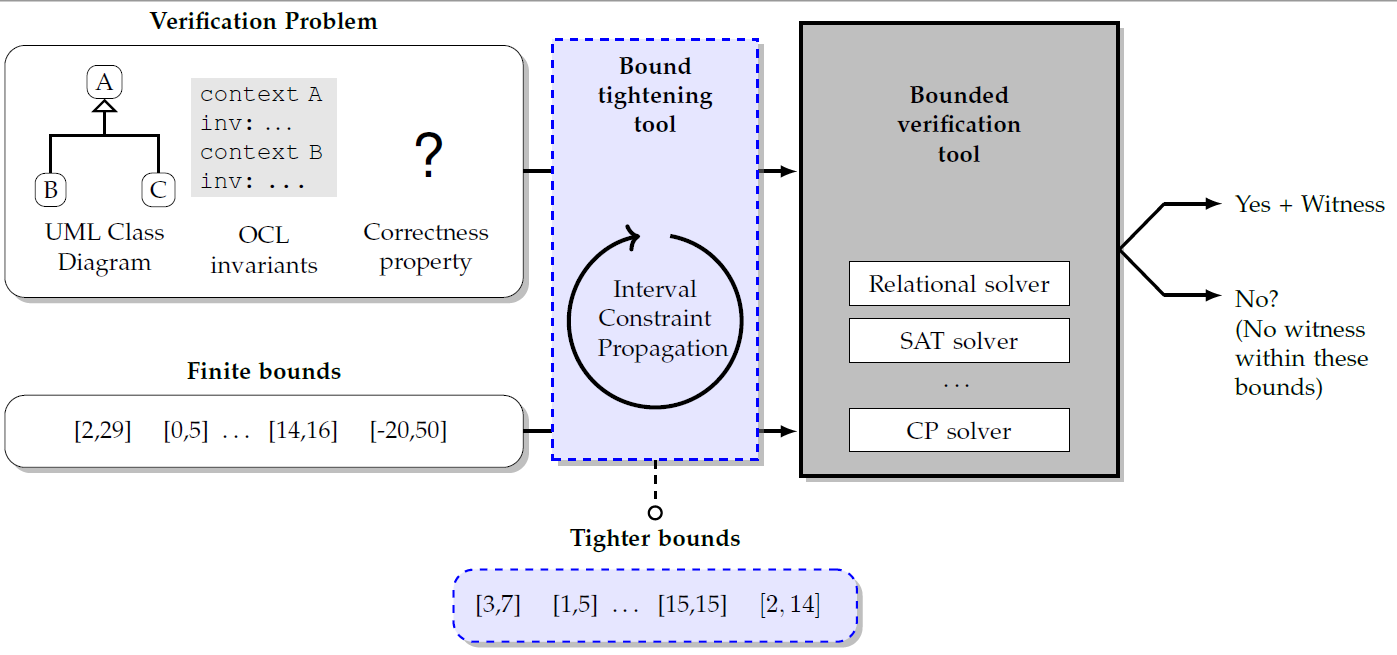
Typical flow with a bounded verification tool and the role of bound tightening
The computation of the bounds relies on interval constraint propagation techniques. As we explain in the following Section, our approach collects all implicit and explicit constraints from the UML/OCL model and formalizes them as a CSP over a set of variables representing the search space boundaries. As we show in the paper experimental results, tightening bounds does not add a lot of overhead to the whole verification process and has the potential to drastically reduce the time needed to verify the model. This process is not optimal but it is safe, i.e., it may fail to compute the tightest bounds, but it will preserve any witnesses within the original bounds.
As future work, we plan to investigate heuristics regarding the best order for selecting bounds, i.e., one that reduces the number of choices and maximizes the amount of information that can be inferred automatically by bound propagation. We also intend to investigate how to reverse this approach, e.g., by broadening (instead of tightening) user-provided bounds which are too strict to find a counterexample.
Robert Clarisó is an associate professor at the Open University of Catalonia (UOC). His research interests consist in the use of formal methods in software engineering and the development of tools and environments for e-learning.


Recent Comments