

UPDATE: After some feedback, this post has been extended with a few more clarifications and a comparison with Umple, a tool that adds modeling abstractions directly into programming languages.
This article started out as a newbie question to Mr. Jordi Cabot, about how to improve the collaboration between a software modeling notation (UML for example), and a general-purpose systems programming language (i.e. a “low-level” language immediately above assembler, akin to C++), by designing the programming language from scratch with such a collaboration in mind (i.e. round trip engineering).
In other words, this happened:
Contents
Part 1: The problem
What should we do as language designers to make life easier for tool builders, more specifically for software modeling tools that try to provide “round-trip engineering” with a notation like UML?
For all you readers who still have a social life, and who therefore might need a quick reminder on the context:
- General-purpose systems programming languages (GPLs like C++, but there are other ones) are good at expressing all the little implementation details of a software system (hence the jar filled with nuts and bolts in the picture above). You could say it’s a more analytical view.
- Software modeling notations (like UML) are good at expressing “the big picture”, the intentions behind all those implementation details, and transmitting this information in a “more parallel and less serial” way, using more intuition (i.e. “parallel” grasping of many ideas in a single drawing) and less reasoning (i.e. “serial” parsing of source code). You could say it’s a more synthetic view.
Both the analytical and the synthetic views are needed, and ideally it would be easy to navigate from one to the other and back again (hence the expression “round-trip”). We would like to whip up some UML diagrams, and then “pour out” all this information into source code:

Then we would like to fiddle with the source code and “pour out” all the changes back into various diagrams (thanks Marie-Claude for the lovely hand):

And of course, we would love to be able to repeat this process as often as needed, without “spilling” anything. As the Wikipedia entry for “Round-trip_engineering” says:
The need for round-trip engineering arises when the same information is present in multiple artifacts and therefore an inconsistency may occur if not all artifacts are consistently updated to reflect a given change
Part 2: “Code-centric” round-tripping
What is the solution to this problem? To be honest, I don’t know what the solution is, but there is a solution I would like to explore. You could call this approach by many names:
- the “carry-on only” approach (in reference to air travel round-trips with minimal luggage); or
- the “code centric” approach; or
- the “round-tripping for dummies” approach.
This approach can be explained based on the following principles and assumptions:
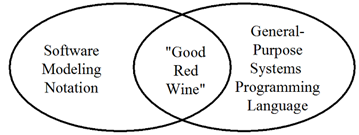
- GPLs are NOT software modeling notations, and conversely. Their respective objectives and means are too different (see “analytical vs. synthetic” above). In other words, the “holy grails” of “CASE” (Computer-Assisted Software Engineering), as well as “executable UML”, etc., are probably impossible to fully attain, but getting a little bit closer is still relevant for software development.
- Despite the fundamental incompatibilities, there is an intersection, (“the good red wine”) used by both the software modeling notation and the general-purpose systems programming language.
- In this approach, the “good red wine” (i.e. the common information used by both the diagramming software and the programming language compiler) is never duplicated.
- The unique copy of the “good red wine” is kept in the source code. (Why? Because source code is the only artifact that is guaranteed to get done, no matter how dysfunctional the development process. Also, if there is a disagreement between the diagrams and the source code, the source code will “win” anyway.)
- The source code cannot be the repository for the “good red wine”, unless it is designed for that purpose. (In other words, C++ cannot be used, unless its “user-interface” (syntax, keywords, all the visible stuff) is re-designed from the ground up.)
- The programming language must be aware of the existence of other tools, must provide them with “hooks and slots” to allow collaboration, and must actively maintain that collaboration during the whole development cycle.
- Collaboration is much easier when somebody is designated to be “in charge”. In this approach, the source code is “in charge”, i.e. if information is replicated in several locations (source code, diagrams, etc.), the version in the source code is deemed correct.
- The diagramming software presents a visual GUI allowing the user to draw shapes, move them around, connect them, etc. Then, if the changes are only esthetic (colors, sizes, positions, etc.), the diagramming software just saves them to whatever internal file format it uses. But if the changes would modify the common information shared with the programming language (i.e. the “good red wine”), then the diagramming software must use the source code as a kind of “API” to modify the diagrams.
To sum up, automatic and repetitive round-tripping would be much easier if we reduced the scope to the common parts of both ends and we extended the GPL part to be used for that purpose, i.e. if we made it more “modeling amenable”. Let’s see how this could work.
Part 3: Snippets of implementation details
I currently only have snippets of implementation details, i.e. how a new general-purpose systems programming language should be designed to facilitate “round-tripping” with a notation like UML:
3.1 Adding UML “syntactic sugar” in the programming language
Just like Pavlov had to work hard to train his dog to associate food with a ringing bell, programmers have to work hard to train themselves to associate software engineering concepts with their symbols (either UML symbols or source code symbols). The more we eliminate gratuitous differences between UML and the programming language, the easier it becomes for programmer’s brains to “flow” from diagramming to programming and back again. For example, given these UML relationships
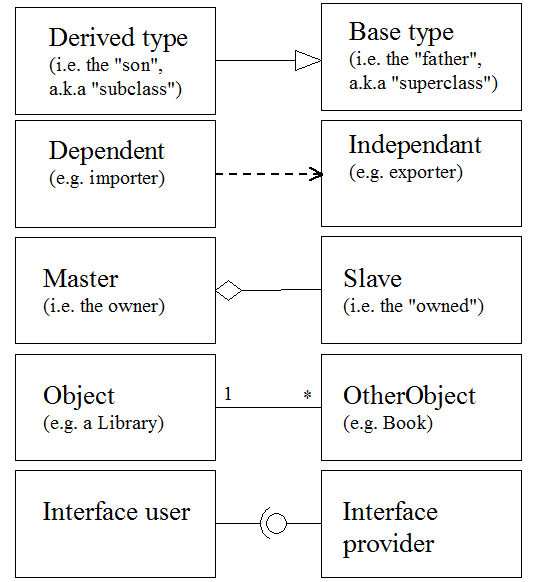
We could have the following “UML syntactic sugar” in the programming language:
# Relationship of inheritance: type Son |> Father # List Son's variables and member subprograms here... # Relationship of dependency («imports» stereotype): import Atom |-> Proton Neutron Electron # Relationship of ownership: type Person |<> name str, age int, isHungry bool # Relationship of multiplicity: # (Inspired by Dr. Timothy C. Lethbridge's Umple) type Library |1--* books arr Book # Relationship of interface: type Citizen |(o- Taxable # (A UML lollipop emoticon? Lord have mercy on us! ;-)
3.2 Reduce the physical design “semantic gap” between UML and systems programming languages.
Architects see walls and windows and rooms, not just bricks and bricks and more bricks. Likewise, software architects don’t just think in terms of lines of code, they also see large “packages of code” as well as their interdependencies (“levelization” as taught by Mr. John Lakos).
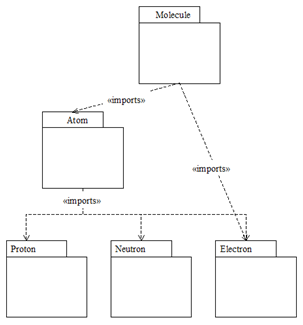
This could lead to source code such as:
import.level 1 Proton Neutron Electron import.level 2 Atom |-> Proton Neutron Electron import.level 3 Molecule |-> Atom
3.3 Resuscitate the “Environment Division” of COBOL
I’m almost serious here. There is something healthy about a programming language having a construct dealing with the outside world. A compiler does not survive alone on an uninhabited island in the Pacific. These days, there are source control management tools, build automation tools, diagramming tools, profilers, class browsers, software component repositories, etc.
The programming language should make an effort to be a “team player”, and this should be in the language itself, not in a private vendor-specific format. This is even more important for C++, which doesn’t even have a language construct for the “project”. (A C++ program is just a heap of disjointed translation units (hopefully) united by a linker.)
Ideally, this means the compiler could:
- Read the “environment” statement;
- Find out what other software development tools currently depend on this source code;
- Detect which “regions” of the source code are “hot”, i.e. must not be touched, otherwise other development tools would break;
- Tell the user how to modify those “hot” regions (for example, “The XYZ diagramming tool has locked this line of code, do you want to start that program to make your modifications to the inheritance hierarchy?”)
3.4 Design the programming language to be a “public highway” for all software development tools.
I say “Highway” because parsing must be very fast (the grammar must not be like a twisty and pot-holed dirt road… like C++), and “public” because there must be no “intellectual property” limitations (i.e. it’s not proprietary).
For parsing speed, I know little about compilers, but I’m guessing this means among others an “S-Grammar” (Hulub 1990, p. 173). Veteran programmers like to repeat that a key advantage of the C programming language is its ability to take one character of input, and throw it away quickly. It’s similar for a programming language that wants to be a “public highway for all software development tools”. It must allow other tools to parse it, and quickly “throw away” what is irrelevant to them. In other words, other tools must be able to easily read the source code to extract the “good red wine”.
Conclusion
As the inventor of C++ famously said: “Inside C++, there is a cleaner and smaller language struggling to get out”. I don’t know what this language will be, but its designers should be able to profit from research on language design rules to streamline round-tripping between it and UML. If you are aware of such research, please contact me, I’m very much interested!
UPDATE: is Umple a dead end?
Umple claims to merge the concepts of programming and modeling by adding modeling abstractions directly into programming languages (currently Java, Ruby and PHP), allowing the Umple pre-processor to both generate basic UML class and state diagrams, and generate reasonably equivalent source code. The diagrams can be seamlessly modified through the source code, and vice-versa, eliminating the necessity for “round trip engineering”.
This article confirms all these Umple claims, but adds a harsh disclaimer: the Umple approach works only if you oversimplify the initial problem by simultaneously abandoning both the speed and efficency of low-level systems programming, and the conceptual expressiveness of high-level UML diagramming. Hence, Umple is currently unfit for industrial-grade software development.
Introduction
Following my article “Round Trip Engineering for Dummies: A Proposal”, Doctor
Timothy C. Lethbridge commented:
“[…] round-trip engineering is not necessary, and is in fact harmful. […] Umple allows direct editing of model and code in either textual or graphical form. […] I think Umple achieves much of what you are looking for in this article.”
I will now attempt to examine that comment, in a constructive and courteous way. (Please be forwarned that, even though I claim to be a Christian, I often cause Jesus to facepalm when I open my mouth! 😉 )
2) My first mistake: changing the title of my article
Mr. Jordi Cabot, after receiving my draft, changed the title (and made a few other changes). He was trying to be helpful, and I was trying to be nice, so I approved the changes. That was my mistake. I’m sorry.
The initial title was:
Round-tripping between languages like C++ and UML
I specifically had chosen the expression “like C++”, because I did not want to limit myself to C++, but I also said “like C++”, to exclude non-systems general-purpose programming languages like Java and Ruby. (A general-purpose SYSTEMS programming language can “go down closer to the hardware”, or as Stroustrup says, there is no room for another language in between C++ and assembler.)
The point is not some “language war”. The point is C++ (and other systems programming languages), are much farther away from the high-level conceptual view of UML. The technical challenge of narrowing the semantic gap between languages like C++ and UML is much greater than with Java or Ruby.
My second mistake: political correctness
The second apparently minor change that I mistakingly approved was the removal of important pedagogical aids, in the name of political correctness. I understand Mr. Cabot’s desire to avoid controversy and accusations of sexism (which is why I approved the edits), but with hindsight, we should just have maintained that the intention was not to demean women. Here are the two original paragraphs, with what was removed in bold:
- General-purpose systems programming languages (like C++, but there are other ones) are good at expressing all the little implementation details of a software system (hence the jar filled with nuts and bolts in the picture above). You could say it’s a more analytical, more “masculine” view.
- Software modeling notations (like UML) are good at expressing “the big picture”, the intentions behind all those implementation details, and transmitting this information in a “more parallel and less serial” way, using more intuition (i.e. “parallel” grasping of many ideas in a single drawing) and less reasoning (i.e. “serial” parsing of source code). You could say it’s a more synthetic, more “feminine” view (hence the jar filled with lipstick and mascara, or whatever, I’m not sure, I borrowed all that from Marie-Claude).
My joke might not be as funny as I wanted it to be, but the metaphor was important: it is ridiculous and impractical to put lipstick and mascara in a jar of nuts and bolts.
A critique of Umple: was the initial problem solved, or oversimplified?
Now that Dr. Lethbridge has helped me improve my original article by manifesting my errors, I will henceforth prove my gratitude by trying to show why Umple is a dead end. (Is “No good deed goes unpunished” a Principle of Model-Driven Architecture? 😉 )
To continue my tradition of silly pictures that contain important pedagogical metaphors, I will use two more, one about the importance of nuts and bolts, and the other about the importance of mascara and lipstick.
Theoretical nuts and bolts are not practical nuts and bolts

An old joke says: “You can fix anything with only two tools: duck tape and WD-40; indeed, if it moves, and it shouldn’t, use duck tape; but if it doesn’t move, and it should, use WD-40.” (For non-Canadians, WD-40 is a light oil, and duck tape is the handyman’s secret weapon).
In theory, duck tape and WD-40 are sufficient. They really do cover all cases, in theory. But in practice, they don’t. If all you need to fix are toy programs written by undergrad students, you don’t need complicated tools. But if you are dealing with industrial-grade software, you need nuts, bolts, screws, nails, staples, nylon straps, epoxy glue, etc.
Let’s leave this “nuts and bolts” metaphor aside and examine one software example. First, a UML diagram, from Umple Online:
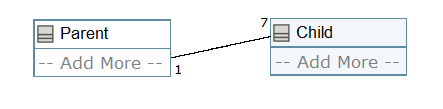
Then the equivalent Umple code:
class Parent
{
}
class Child
{
7 -- 1 Parent;
}
Nothing magical here, a basic “1 to Many” relationship. We’re talking about a couple of boxes, one line and two numbers. Now, what could this give in a general-purpose systems programming language? (Pardon my clumsy C++, I’m still learning)
const int NUM_CHILDREN {7};
class Parent {
// Old-fashioned way
Child myChildren[NUM_CHILDREN];
// More modern way
std::vector<Child> myChildren;
// But what if you discover new children and need to insert them
// otherwise than by appending them at the end?
std::list<Child> myChildren;
// And what if the children come from "surrogate parents",
// and you become the real parent only later in their lives?
std::vector<unique_ptr<Child>> myChildren;
// What if many people claim ownership to a huge number
// of children, and you need to access them quickly by name?
std::unordered_map<std::string, weak_ptr<Child>> lotsOfChildren;
// Etc., etc.
};
// And what if we're talking about an absent father who doesn't know
// who his children are, but the children know who their father is?
class Child {
Parent& myAbsentFather;
};
// Same as above, but the children only find out later in life
// who their father is, maybe.
class Child {
Parent* myAbsentFather {nullptr};
};
Those are just a few examples of ways to implement a “1 to Many” relationship. I’m sure a competent C++ programmer could name many more, as well as list the advantages and disadvantages for each option, and chose the appropriate one according to the circumstances. (The current Umple version has only one way to implement that relationship, a bizarre pointer to a vector of naked pointers, on top of generating over 400 lines of obscure C++ code just for those two empty classes of “Parent” and “Child”!)
The way Umple is designed, it prevents such necessary implementation flexibility (even if C++ was supported as a base language, because it’s not). Umple claims:
“There is never any need to edit generated code, since any desired effects can be achieved either directly in the model, in the passed-through methods or in the aspect-oriented code injections.”
Pass-through code doesn’t help: if you just “pass-through” a line of code containing a relationship without processing it, the relationship won’t appear in the UML diagram. Aspect code injection doesn’t help either, for the same reason. If you manually modified the generated code, a clever C++ parser might be able to pick up many of those relationships and display them in a UML diagram, but it would not catch all of them. Even then, that wouldn’t work, since Umple doesn’t allow you to modify generated code (round-tripping is forbidden in Umple, remember).
You could transmogrify Umple to make it as expressive and powerful as C++, while providing “UML syntactic sugar” so programmers could give cues to the diagramming software about where the UML relationships are, as well as allowing round tripping, but then, that would not be Umple anymore.
6) Would Marie-Claude agree to this method of applying makeup?

Umple does allow the programmer to specify a few things about the esthetic appearance of the generated UML diagram (what I call “lipstick and mascara”). For example, a class can be given a specific position in its diagram:
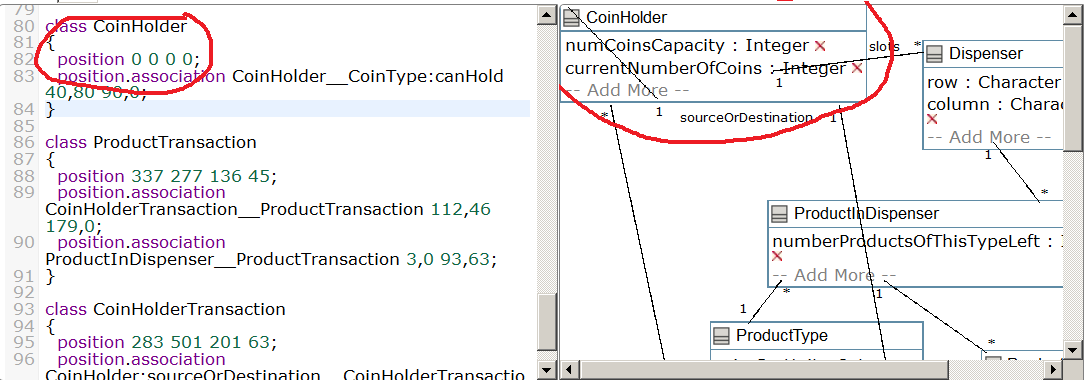
And that’s about it for “lipstick and mascara” in Umple…
But in order for UML to actually work, we need much more “lipstick and mascara”. Modeling is not a simplistic affair. A good model “lets us visualize the invisible, makes the fleeting stand still, and gathers the too large or too small right in the palm of our hand”. As Grady Booch says, “[…] even the most subtle visual cues can go a long way in communicating meaning”, (The UML User Guide, 2nd Ed., 2005, p. 88.).
Let’s take the very simple example of just one class:
- A class must be able to appear in more than one class diagram. (Already, since the position is encoded in the actual source code for that class, this is impossible in Umple. Whip out the paint roller…)
- Each class must also be able to appear in other types of diagrams. (There are many “views” in UML: the use case view, the design view, the interaction view, the implementation view, and the deployment view).
- Each class must also be able to appear in non-predefined diagrams. (“Of course, you are not limited to the predefined diagram types. In the UML, diagram types are defined because they represent the most common packaging of viewed elements. To fit the needs of your project or organization, you can create your own kinds of diagrams to view UML elements in different ways”. op. cit., p. 91).
- In each of these potentially numerous instances of a “class appearance”, that class must be able to selectively hide from zero to all of its fields and methods (“Show only those properties of the classifier that are important to understand the abstraction it its context”, op. cit., p. 132).
- Since any class can have extra named compartments containing pretty much anything you want (op. cit., p. 79), whatever is in those compartments must also be able to be selectively hidden or displayed. (I personally love to have a named compartment called “Responsibilities” in the important classes; it really helps to understand what is going on.)
- Each class (well, actually each visual element in any diagram) must have a user-definable position and size (and other graphical attributes). One of the important talents of a “UML artist” is organizing things in the diagram so the sizes and positions convey a sense of what is important, what is going on, who depends on who, etc.
- UML gives much freedom for “adornment” flexibility: colors, icons, notes, etc.
- UML also has semi-structured “extensibility mechanisms” (stereotypes, constraints, tagged values), which pretty much mean that the bottleneck is the diagramming software (or the stamina of your wrist muscles if you’re using a whiteboard).
I thought of drawing a UML diagram of all this “lipstick and mascara”, but it’s very complicated! The design of a good UML diagramming program is one tough challenge in itself, because of this complexity. But I hope you now understand why my initial picture at the top is misleading: Marie-Claude doesn’t have one little jar with three tubes of lipstick and mascara. She has MANY MORE! Lipstick, mascara, eyeliner, fingernail paint stuff, powder stuff, and all kinds of incomprehensible stuff filling all the cabinets in her bathroom, and in her bedroom, and in the entrance near the mirror, and in her multiple handbags, etc.
This metaphor is important: good UML diagrams are complicated beasts which require esthetic talent, creativity and powerful tools! If you try to put all that complexity in the source code, you’ll overwhelm the programmer with clutter. If, like the current iteration of Umple, you pretend such complexity isn’t necessary, you’ll basically end up putting on makup with a paint roller. And of course, if you let the diagramming software manage the UML on one hand, and the compiler manage the source code on the other, you’ll end up with the original problem of “synchronizing the jar of nuts and bolts, with the jar of lipstick and mascara”.
Conclusion: Is Umple a Dead Endle?
Is Umple a Dead End? Of course not. This is software. Anybody can change anything anytime, especially a super-smart Ph.D. like Dr. Lethbridge and his army of super-smart graduate students!
Can I recommend the current version of Umple to my Boss today for real projects? No, because Umple simultaneously manages to take away BOTH my nuts and bolts, AND my lipstick and mascara. I need both, and both synchronized, to build non-academic software.
Currently exploring ideas for a General-Purpose Systems Programming Language with the underlying Object Model of C++, but with an updated “interface” (i.e. the syntax, keywords, etc.), so it can become a “public highway” for all software development tools.
See www.gepsypl.org


For almost 20 years I have believed that round-trip engineering is not necessary, and is in fact harmful. For the last 10 years we have developed Umple that makes that perspective concrete. Umple allows direct editing of model and code in either textual or graphical form. See http://www.umple.org
I think Umple achieves much of what you are looking for in this article.
Good day Mr. Tim Lethbridge,
Yes, I examined Umple before writing my article,
because of Mr. Jordi Cabot! When I sent him my question,
he sent me several hyperlinks of resources, among
them a brief description of your work and your web
site http://www.umple.org. So you have a vigorous advocate!
I have the memory of a Goldfish, so I will need to go
re-read about Umple to answer your comment fully.
I don’t have all your degrees and years of experience,
so please give me a few days.
Cheers,
SJJ
I agree that Umple has many of the qualities required here. For the readers, remember that we talked about (and discuss) Umple in this older post: https://modeling-languages.com/umple-language-model-oriented-programming/