

The enormous potential of modelling technology in IT and adjacent business domains is in curious contrast to the poor leveraging of that potential and the low dissemination of the technology. In this post and some possible followups, I’d like to reason about causes of this divergence in modeling potential vs modeling usage and share my thoughts about how to improve that.
The Blind Spot of modeling
While there are a few rather small communities of still-believers in modelling and MDx technology ([1], [2], [3], [4]), the mainstream opinion about these matters ranges from agnosticism up to strict rejection, whereas at the same time even the strictest opponents quite naturally maintain models or even apply code generation techniques on occasion. How is it, that this discrepancy is not questioned?
It’s the year 2018. AIs and Mars mission on the horizon. Besides improving our collaboration and to some degree our tools, software production is still quite similar to as it was in the last century, laborious work with languages on low, technical levels. How is it, that automated production based on business languages got forgotten to a very large extent?
To understand where we actually are and how we came there, here’s a brief modelling history, from my personal point of view:
Early approaches of MDx technology failed utterly and repeatedly
Based on the observation that application coding is a highly redundant activity, early approaches from the 90ies (CASE) tried to project naively simple models on low abstraction levels more or less isomorphically into code. The results are history: large, clumsy, complicated wallpapers and unusable half-done code monoliths.
A remarkably annoying Trough of Disillusionment
Several attempts to address this in the 2000es (MDA) failed comparably, resulting in about 15 successless years of MDx altogether (remember the famous sentence: modeling will be commonplace in three years time?), leaving much burned money, many unhappy customers and frustrated coders behind.
Agility declares war to excessive preplanning and megalomania
Around the beginning of the new millenium, coinciding with the unusual annoying trough of disillusion of MDx, the agile manifesto entered the world, bringing postmodernism to IT and overthrowing those all-too-strict gods of preplanning and megalomania.
Still, the authors of the manifesto understood their craft well enough to consider the necessity to continously and carefully reflect upon ones doing. Here, in the manifesto, the value of models is explicitly ’embraced’.
The iconoclasm of the agile mainstream
But as it goes with cultural changes, too many followers skipped the more boring and time consuming parts and stuck to page one of the manifesto, where the easy-to-grab phrases are printed prominently: people over processes, no boring documentation anymore, that’s what we always wanted, right?
In the following iconoclasm, Agility became Avoiding Unnecssary Documentation and Preplanning, which became DiscardingDocumentation and Planning, which became BanishingBigDesignUpFront, which became DemonisingDesign, which became ToHellWithUMLAndModelsAllTheSameAndEverysuchDiabolicStuff. Why bother with the difficulties of modelling technology if there’s an easier road to choose and a good excuse why it has to be just like it is?
Reasoning about MDx was abandoned and became tabooed
The obligatory hype cycle suggests that after disillusionment caused by exaggerated hopes the technology improves and finally reaches maturity.
Not so here. The disillusion was too painful, and the promises of the counter-revolution too tempting. Quieter, careful thoughts have been easily thrown away and reasoning about MDx was considered with much suspicion now.
Modelling Technology now grew in the backyard
Since software development still was (and is) a laborious task, creative minds invented approaches compatible with the new, already dogmatic, paradigm. Lightweight concepts surfaced (domain specific stuff), lightweight generators under fancy assumed names (avoiding the M-word), lightweight mini models here and there flowrished (the colorful world of annotations, or things like openapi).
The ban of models takes on strange forms
Most painful in daily agility became the lack of structured capture of specifications beyond code. This, e.g., ignited the somewhat funny idea that, if we’re forbidden to craft models, at least we can sit together and talk about them (“look, we do not have an architecture, we just communicate it”).
To be able to do that, it became necessary to stretch the concept of architecture so that under a broader roof it comprises what before was rather aptly named “system design”. This definition is unlucky since whether a decision is an early one depends strongly on the technology used, meaning that a systems architecture depends on its implementation and production technology – a truly unfortunate commingling.
Be that as it may. Years passed, and there might have been a chance to clear matters up. After all, it’s a long known insight that only the bad workman blames his tools: models are not to be confused with their naive misapplication in the twilight of the age of cathedral building.
Technology Eruption
Yet, in the midths of that already knotted situation, somewhere between the 00es and the 10s, several rising forces grew into a stage where their exponential nature became clearly evident, and by mutually fueling each other they spiraled into technological fireworks of unprecedented impact.
Globalisation got also to the heart of the fabrics of software itself and of it’s production: distributed sharing of and cooperation on open source code, distributed components ready-made in global repositories, distributed platforms in cloudy servers and containers, distributed computing of masses of data, masses of distributed devices with a touchscreen or invisibly doing stuff, and distributed pieces of applications interacting restlessly or rather restful.
Business Disruption
Driven by such technological and a variety of other forces of the early 21st century, business disruption became commonplace and reshaped the IT world from two sides.
At the software consumer side, customers spotting opportunities or being plainly forced by competition developed a wild hot need for information technology, no big player to be found anymore without a strategic digitalisation force, most ambitious projects and scrum teams sprang up like mushrooms, and a painfully unsatisfied demand for specialists of all kinds became the main obstacle for even faster progress.
The Customer Is King – what about the Imperator?
At the same time, at the software provider side, IT players faced a problem themselves: with inhouse scrum teams, open source and what else the old strategies for market leadership vaporized into nothingness, except for maybe expert renting.
While this pressure generated much valuable new services, at the same time a new war around platform ownership arose, less visible, more fierce, astute, subtle, nonetheless likely more effective in the long run than the cruder attempts of the last century. And here, the crispness and clearness of models might not be considered top priority for those whose goal is to bind customers to their platform.
The Cathedral, The Bazaar, and Conway’s Revenge
Cathedral-style software development – predesigned in the ivory tower, second sighting five years into the future, guaranteed too fail – has been largely replaced by its bazaar-style counterpart – lifely and respectful negotiations, responding to change: the seed of the manifest is bearing rich fruits. According to the manifesto, we should expect to see admirable architectures now, emerged out of self-organising teams (though open source development models have their own “community-oriented” problems)
But beware: if postmodernism told us one truth, it is that there is no final truth. While at the macro scale todays restructured corporations are declaredly better prepared to meet the unknown, on the micro scale the agile dream of emerging quality suffers from the same old drawback as many of it’s preceeding approaches: still the most significiant ingredient is the healthy team of bright, motivated people in a healthy environment. Ubiquitous derivations from this ideal setup cause communication drawbacks, amplified by network effects, and covered up by group dynamics – welcome to Conway’s Revenge.
Software Development Today
Technology eruption, business disruption and organisational redesign produced an amazingly fragmented landscape of microcosms, inbetween which most valuable business knowledge is traded by word-of-mouth and within which this knowledge is by means of laborious handiwork knitted into code.
Companies are panically stacking up scrum team over scrum team, and while there is continuous integration, continuous testing, continuous deployment, continuous operations – there is next to no preservation of fundamental knowledge and only a very, very cumbersome core production step – which, alltogether, in turn, causes some serious creeping decay in quality: not really numbered amounts of wasted resources and new ‘interesting’ kinds of lock-in effects are at stake – or, to the many smaller companies who cannot afford themselves much waste it simply translates to impediment of opportunities.
We would be well advised to get back to the roots of this costly blind spot.
Modelling Rethought
Our quest should begin with the honest question whether the whole undertaking is it worth anymore: is there an actual benefit to be expected from modelling? And if so, the more serious challenge: why got the technology stuck so annoyingly deep in the Trough of Disillusionment?
To answer the first, let’s take a step back. What is the actual goal behind modelling? Certainly, modeling was never intended to produce additional, redundant, and wasted work and paper. If we put aside those negative connotations, it becomes clear that there have been and still are some rather reasonable and simple ideas:
- Give domain experts a means to express their needs and knowledge in an efficient and comprehensible way, ranging from early sketching up to formal precision
- Give architects and technology experts a means to continue the work of the domain experts (whatever that work may be, then) as apt to their needs as it has been to the domain experts
- Reduce wasted work by all means (the importance of this is huge, since there is so dramatically much wasted work, and here – surprise, surprise – modellers and agilists should be able to find out that they’re fighting on the same side)
Obviously, these goals have never been reached, but they are still more desirable than ever, given all the crazy and fast evolving technology around us and its value for enterprises of all kind. Much more than ever, given that IT systems are presently fundamentally metamorphing from isolated monoliths into largely distributed organisms of interacting stuff of all kinds (whose more biological nature might possibly indicate some characteristics of future languages).
In the light of these goals, modelling could be considered a natural continuation of language evolvement. From early machine code to 3rd, maybe 4th or 5th generation languages there has been a more or less steady improvement. Figure 1 illustrates that evolution (representing the author’s condensed impression of a few decades of software development, it would be hard to find reliable numbers for that, since seldom the gory project details find their way into the light of the public).
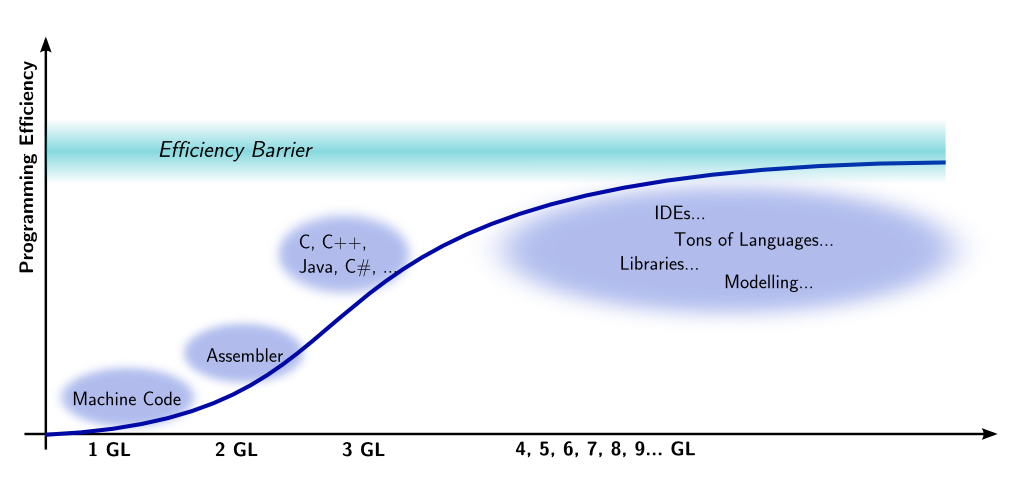
Figure 1 – Decreasing efficiency gain for modern languages
The more recent language innovations, including models, feel different. There seems to be a solid technical barrier or more fundamental one which cannot be removed so easily. Language improvement has slowed down, and new features are sometimes simply ridiculous, seeming more like cosmetic measures to cover the lack of real progress in the area (sure, exceptions prove the rule).
Again, don’t let you get fooled by easy-at-hand excuses, like, this barrier indicates that we shouldn’t aim for larger goals, that software development is inherently a hard job and that agility is the only cure, or that some day a brighter future will emerge itself out of the muddy mass of code we hack together – it won’t. After one and a half decade we can take that for granted now. And by ‘brighter’ we are not addressing things like linting, beautifully balanced curly braces or the hundredth very rapid and responsive todo app creation tool – think about how utterly far we are from those goals above, which are, by the way, very compatible to the idea of Avoiding Muda (無駄).
Instead, based on long years working with a variety of different modelling technologies, I am strongly convinced that the barrier points to a phase transition in language evolution, and that a critical mass of circumstances has to coincide to be able to grow beyond it. Therefore, I’d like to find an answer to the second question, which is to examine the nature of the barrier and from that understanding derive practical measures of how to cope with it.
As stated, this language evolution looks not like being a matter of some single invention, but rather of growing into an ecological environment which provides the critical mass required for that next evolutionary step. The nature of such an environment gave rise to the name of ‘Modelling Biotope’, or just ‘miotope’.
Outline of a Modelling Biotope
In which way does modelling differ from more successful approaches, say from writing Java code?
Why is Java used? Because it can be used, and because it is used. It can be used since you can lookup how it works, write something compliant which then does something useful in easily available environments. It is clear what you want to express with some piece of Java. Since many people use it, you find someone to share and discuss code with, so many people use it.
Not so for modelling. There is no language you can easily lookup how it works, there is not even one which actually works convincingly, if at all. There is not even one you can write without pain, and if, it might be far from clear what your model expresses, even the level of abstraction or domain you had in mind will be typically vague. Sure, there are exceptions, but in general that holds. Since no one uses these languages, you can neither share nor talk about them, so no one uses these languages.
Motivated by such comparisons and similar ones, let’s try to derive a list of properties that seem reasonable for a useful modelling language to exhibit:
1. Syntax Basics
A language should be writable with ease. While tool support for editing is unquestionable desirable, a simple text editor also has to do. This implies clumsiless and noiseless syntax, and some reasonable (80/20)* effort ratio (Recursive Pareto, see below), so that the 80% easy things can be remembered and expressed easily.
Since models are authored by a broader variety of stakeholders, their editing tastes should be met. Spreadsheets for business people, diagrams for architects, MarkDown for sprint planning and JSON, YAML and XML for the more solid technical folk – 1:1-painlessly convertible into each other.
2. Modelling Object – what is modeled & Modelling Aspect – which part of it is modeled
In Java, it is immediately clear that the code describes the interface, structure and functioning of a software component. Models could be able to describe these also, but much more things like some inner or outer architecture, organisation, activities, integration, infrastructure, deployment targets, configuration, entireley different things than software systems, organisations, coordination efforts, you name it.
Thus, our language should provide means to nail these intentions clearly down in a common, formal way. We won’t go as far as to generalise modelling such that it comprises everything in the world, but our scope should not stop at information technology but capture organisational and factual business stuff nonetheless, the exact limit debatable.
3. Modelling Specificity – on which abstraction level it is modeled
Java code describes a technical system in technical concepts and technical terms, partly aligned with domain concepts due to its object oriented nature. With modelling, this does not always hold – to the contrary, in some cases it is exactly what we want to avoid. Therefore, we want our language to be able to provide the respective appropriate choice for respective purposes, i.e. whether the modelled content, the modelling language, and the modelled concepts are more business oriented, neutral or more technical oriented.
4. Modelling View – from which perspective it is modelled
Java code describes the functioning of the resulting component more or less from the point of view of the virtual machine, at least from an IT perspective. Depending on the aspect or audience of a model different perspectives are possible, like a Business or Economical Context.
5. Appropriate Abstractions and Reasonable Meta Models
This issue goes to the heart of the question of modelling, if, how, and whether at all. Inppropriate abstractions are painful with Java as with models: user interfaces, UI logic, algorithms, data structures. A good modelling language shall provide very appropriate abstractions for each purpose. Is that possible at all? Is it hard to find them?
Moreover, one of the other major learnings of postmodern thinking is that there is not the one and only true answer to that, but evolution should do its work in a lively and competitive environment. In Java we have things like the maven- and docker-biotope, in modelling we need such things, too. This touches, by the way, the good old ‘modelling repository’ question.
Besides all best intented postmodernism, we want not neglect that for a good majority of cases there still are ‘usually good’ solutions. This comprises abstraction areas like systems, domain knowledge, processes, architecture and common system properties. Therefore, we want in a well handable way to be able to provide and express these.
6. Modelling Impact – automated interpretation, execution, processing
Java can be executed, most Models cannot. This seems to be the most crucial question, since if models do not have some immediate and direct impact, they will never become relevant to anyone, will stay some redundant decoration and decay in dusty office corners. Therefore: as counterparts to good abstractions respective bindings to the real stuff have to be provided. Is that possible at all, hard to find them? Given the speed of evolvement of target technologies today?
7. Modelling Genericity – How general is the model?
In Java there are Classes, Generic Classes and Instances; with models there might be more types of genericity, like templates on different levels, samples, prototypes and alike.
This might seem like a matter of more scientific interest, but make no mistake, such misinterpretations are not unusual to cause confusion, say e.g. with processes.
8. Modelling Coverage – how horizontally complete a certain aspect is
Certainly, this is an important property, but it is already to be found in Java, too: a system might just not be complete, usually pointing to a lack of captured requirements or to incomplete implementation. Requirements coverage can be expressed with test cases (TDD), whereby test failures indicate a lack of implementation coverage. With modelling we want to be able to express all this nicely. In addition, we note that completeness is not always a desired property: models might be kept intentionally raw or open, to reflect the openness of the modelled system, or to support different stages of model maturity, or for human communication.
9. System Coverage – whether all aspects of the target are captured
Even if certain aspects are covered perfectly, there might be other aspects of the system which are covered most insufficiently. This is also already the case with Java, too. Think e.g. about configurations, deployment, packaging, distribution, overviews, rules, data structures, initial data, master data and alike. These are often handled as secondary things, which becomes painful in DevOps and Ops.
Therefore, we want to be able to express all relevant aspects of a system, including domain knowledge, constraints, logic, and more.
An intesting part of this is an outline of how the system is constructed, which we might call its architecture. A term, whose meaning became, as mentioned above, a bit vague over the last years, but which might be redefined here more promising again.
10. Modelling Precision – how vertically complete it is
Coverage can be complete, but vague. A useful description requires precision, too. With Java, this is to a certain degree guaranteed, since Java code needs to compile. Yet there may be gaps, too, like methods whose body is just empty.
There are certain kinds of openness which are intended. Say, some details are only provided at runtime, or depend on contextual properties or preferences. It is desirable to express such openness explicitly and to augment missing details in a clean fashion, so that no conflicts or redundancies are introduced.
11. Model Zooming
The means that allow openness and stepwise augmented precision might also help with zooming, i.e. viewing a model on a deliberately choosen level of coarseness and being able to zoom into a more detailed level, thereby either just adding details or possibly also crossing abstraction boundaries.
Zooming as a tool function, but as well as a mere mental operation: by e.g. just opening a different file with the details.
12. Model Evolution
Coverage, as well as Precision, play a role in evolving a model, since both grow over time into more completeness. From early scratches to formally complete descriptions, traditionally separated types of documents may prove themselves as being simply different maturity stages of one and the same model: requirements, specification, architecture, design, implementation and documentation become one and the same model in different points of time (see also next issue).
13. Modelling Quality – DRYness and SoCness
An obvious point, and still most important: Java is the one true source, there’s usually no redundancy except when artifically introduced by e.g. not formally related documents.
Consequently, for our language, we wish the same: every piece of information needs to be expressable at an appropriate place, and only there.
E.g., to enable domain experts to express domain matters, a usable language must allow refraining from technical specifics or other non-essential concerns, which must not be repeated elsewhere, then. E.g., technical experts need to be able to express core algorithms in a language appropriate for that task – which might be Java – without interfering with models.
In short, the old “Code is Design”, which was used to motivate to use Code as Design instead of handling both, should be extended to “Code is Design is Requirements is Specification is Documentation”, to motivate the use of an appropriate modelling language which keeps all those aspects in sync, without overlap, or even better: unify these aspects to become nothing else but different maturity and zooming degress of one and the same artefact.
14. Model Discovery
With Java it is straightforward to find code by extension .java and everything else, with models we want to be able to do the same. Next to pure matters of finding model data by defining and identifying file types at defined or guessable locations or identifying and extracting this data embedded in other data, like with annotations, it will be necessary to identify the role that such a model plays in a given project context (see also next issue). The issues here are defining types, locations, metadata and alike.
15. Model Role – what is the model used for in a certain context?
As stated, the role of Java code is straightforward, since it’s to be compiled with a Java compiler and then executed afterward. Roles of models comprise much more. E.g. even a class model might be used for storage or service provision or service consumption or whatever.
For models to be immediately useful, it will be necessary to state their role in a well defined manner. An approach to this might be found in formal descriptions of projects as production systems, where roles of models can be described in a natural way. Obviously, for such descriptions all requirements stated here with regard to usability, quality etc. need to be applied as well.
16. Cross Domain Models and Cross Abstraction Models
Due to the sheer size of certain modelled areas, or e.g. interacting objects and aspects from different domains, support is needed for aggregate realms on instance level and genericity realms on inheritance level, to be able to organise such big models.
Due to polymorphism, e.g. in cases where the interpretation context might not be completely determined, models must be augmentable by specialised properties which are then specific to such given contexts. These properties shall be treated with the same care as other properties, i.e. easily addable, not restricted, formally checkable if desired, and transported with care if no formal definition is available, coexistig with other such properties.
17. Customised Model Usability
For certain use cases, it is desirable to provide customised editing enviroments, which provide guidance, appealing visualisation and integrated help. It is understandable, that these environments might require some preparation, based on meta models or configuration.
In other use cases, for the experienced modeller it can be an annoying burden to be forced to perform such preparation each time the configuration changes. Thus we wish to be able to use our freshly configured modelling language in an instant. Switching the metamodel behind should require nothing else but e.g. editing a config entry.
18. Conflict Free Editing
Possibly, and rightfully, the most annoying issue with modelling and generation approaches of the past has been the haunting conflicts between generated and manual code, plus, in consequence, the ugliness, if not the impossibility, to put the affected files reasonably under revision control. Many developers abandoned MDx for just that reason.
With Java, this problem obviously does not exist. Therefore, we ask for the same hassle-free-ness with modelling, which in consequence means: strictly distinguish generated artefacts from manually edited source, never ever mix these up, not even if the most sophisticated tools are at hand to try to manage that for you based on the same artefacts.
19. Model History
Models shall be able to be put under version control, thats undisputable. One obvious difference between Java and Models is often, that the latter comprise more logical subcomponents than the first, where some randomness of ordering is introduced.
A simple approach could be to divide models similarly into smaller parts, say one class in one file. But this would be just one possible approach. If feasible, others may do as well. Howsoever: we want easily handable version control.
20. Modelling Technology Evolution
Among all those more lightweight approaches that grew in the last one or two decades, there is much valuable stuff to be found. This might fit somehow into the picture, and certainly the benefits found their should not be neglected. After all, the core idea of a ‘miotope’ is more like growing into something, and less like burning everything down and starting from scratch.
That translates to compatibility to the better parts of existing languages, concepts and tools, and ideally building upon or interacting with existing OSS approaches.
21. Modelling Transition, Compatibility & Benefits
The typical zero modelling and the fully model driven software production setup – organisation, roles, tasks, skills, tools – differ to such an extent that it makes not even sense to start listing them. It is equally clear, that such a transition does not silently take place over night – if it is desirable in it’s entirety at all.
Instead, a smooth transition back and forth to any desired degree of model usage should be possible, which in turn requires coexistence capabilities between approaches as well as resonable incremental benefits, so that each transitional step makes sense in itself.
22. Modelling (as such) – who’s modelling, why, and how?
Even with the most awesome modelling tool, business people cannot be expected to do it themselves, at least not all and always. This is just because it’s mostly not their job, business people tend to have other issues in mind. Nevertheless, involvement is crucial, one of the major learnings of successful agile practises.
Which means, that modelling will likely be a collaborative effort between all sorts of experts, which want to work with the model as easy as with maybe a text document, or their favorite chat app. Which means, you cannot assume that everyone is able and willing to handle code versioning tools, IDEs, or any such tool at all.
23. Model Branding
If you say “Java” to a friend, a nice conversation might follow. If you say “Model”, that person might instantly petrify. MDE is not cool, which is unfortunate.
The term has become too full of negative connotations. Maybe it’s mainly a matter of rephrasing or reframing, but maybe something more apt can be found, which reflects new insights and supports communicating such ideas. That might be not the most pressing issue, but it cannot hurt to give the matter a fresh start.
24. System Override – Soft Landing with Recursive Pareto (80/20)*
Even the most ingenious concept has its limits – a rule that gets forgotten more and more in modern software development, but that’d be a blog series on its own – so we want to be able to escape the system without being completely lost. That, by the way, was also one of the ugliest problems with early MDx technology: use it as it is, or die (‘Friss, Vogel, oder stirb’).
Recursive Pareto is to mean: 80% of the simple things should be doable with ease, from the remaining 20% which are slightly non-straight-forward again 80% (which is 16% altogether, then), should be doable with a little more effort, then, from the remaining 20% of 20% (4% altogether) again 80% of the somewhat out of the line requirements (3.2% from total) might require some more special care, and so on, recursively.
25. Logic
A question that is immediately raised if someone claims to be able to generate code from models is: “How do you deal with logic?”
On the one hand side, that question is extremely important, since it might decide upon success or failure of your project: the choice of language determines whether code is sustainable, whether coders love the tool or hate it, whether the tension between model and code destroys the setup or supports it.
On the other hand side, there is a huge misconception on the purpose of modelling behind, which should be to a large extent: to find appropriate abstractions!
This requirement therefore can be split up into two parts: first, find modelling abstractions so that the need for program code is reduced to 1%, seriously. And second, express these 1% in languages that are respectively appropriate (whatever that means).
The Gorge of Complexity
This is quite a bold list, and it might well be that some readers got lost between issues 5 and 24 and are back to coding, shaking their head and enjoying a good cup of coffee. My apologies. Admittedly, a first glance at the majestic gorge we are facing seems daunting, and what else might await us there?
But we can gain a first, much important insight here, which is: the list throws a lot of light on the true nature of the barrier. From here, it becomes evident why early MDx approaches necessarily had to fail, since their naive lack of an understanding of what they are up to resulted in mere coding attempts disguised as modelling, whose very poor and under-complex capabilities did by far not meet the complexity of the task at hand.
Really, modelling isn’t exactly comparable to Java coding. It is rather an umbrella term covering a wider field of accomplishing a profound variety of different and in their comprised complexity clearly larger tasks. Indeed, program coding might be considered one fine instance of them: modelling is not a comparable continuation, but a substantial extension and generalisation of coding.
The Fellowship of…
The usual cliff hanger: in the next episode, our quest of the brave modellers will bring us to the matter of Language Basics. This relates to Syntax Basics, Model Discovery, Model Usability, Model History and System Override) from the list above.
To be continued…
PS: If you’ve made it reading up to here, you are possibly interested in a deeper exchange about these matters, in which case you are invited to join a slack, created for just that purpose. Drop me a note so I can send you an invitation.
Update (June 28, 2018)
25th requirement: hinted by some very valuable feedback, I recognised that I just forgot to mention an utterly important aspect of the whole game, which is: logic. The reason is, over the years I so much fought for eliminating (pseudo-) domain logic by better abstractions, that it slipped my mind that logic still rightfully exists (ok, that’s been a cheap try to find an excuse, but a tiny grain of truth is in it). The article was updated correspondingly, the initial version contained only 24 requirements.
Silver bullet language: I received feedback that the article gave the impression ‘miotope’ is (nothing else but) a new silver bullet language. Quite not – it’s envisioned as an open ecosystem consisting of a community, tools, tool providers, services, abstractions, and indeed a useful, used and living language. That said, I do consider such a language a decisive ingredient, seeding and catalysing the growth of a ‘miotope’, presently non-existing.
Next post concerning miotope: Refactoring Modelling Technology – Say It Clear
I’m working in IT since the late ’80ies of the last century. Half of my time I spent crafting software of various kinds for customers, increasingly based on model related technology. The other half I invested in research and development of a fully model driven software production system and respective suitable concepts, most of which is available as open source or creative commons. Since the beginning of the millenium I’m doing this in my own Hamburg-based company and offering software production as a (model based) service — Andreas


I will need to read it again and again, but let me say that your description of current status and prevalent opinions is the most interesting and revulsive I heard these days.
I will need another week to be more precise.
Dear Jorge, thank you very much for your encouraging comment! I’m curiously looking forward to any more thoughts about this.
Reading another post from Jordi (https://modeling-languages.com/mde-is-not-cool/), I found there several diagnostics to be taken in account. Glenn points to one of them I see repeatedly <>. But as I can see, the greatest breakdown came with the expansion of mobile and cloud: while modeling tried to make a step, new architectures made two, three. It is better? today there are countless frameworks, paradigms, and it is another problem per se. Software seems to go to a status of continuous change, and I´m almost sure that continuous integration not will be the solution. Legacy will be measured in very short terms.
Different modeling tools would have different diagnostics, according to its weaknesses and strengths. I’m not sure would be a simple or unique solution. But probably, as more complex, as more harder to get adoption.
Excuse me…Glen reference was lost…He said:
MDE is not cool with programmers precisely because they want to spend their time coding. With MDE, you spend most of your time modeling and not coding.
As a programmer, I think MDE is cool because you do spend time meta-programming which I find to be very geeky and intellectually challenging in a oddly relaxing way. Most programmers aren’t into that at all.
@Coolness
Let me assume a programmer who wants to do a good job and who is skilled at least fairly ok within a certain scope; even then there are good reasons against most legacy and many contemporary MDx offerings: the lack of impact, and the lack of freedom. Most programmers I learned to know (and I feel the same) want to actually create something, and want to meet certain quality standards by intrisic motivation.
Impact is an obvious precondition, but freedom all the same, because lack of freedom means risks (the tool provider might pull the rug out from under your code), potential obstruction (something does not work and your hands are tied to fix it); plus, allmost allways all platform providers, as soon as they got enough control over some piece of the market, started to reglect and squeeze out their customers. All that is feared by programmers, and quite rightfully.
@Speed and complexity of change
Early MDx abstractions addressed the single instance 3-tiered application (monolith…) on a fairly low technical layer, and from there MDx evolution frayed out into facets of a hologram, each piece more of an experiment (though valuable) but a solution – our job would be to reintegrate these learnings into a holistic picture. Is that goal moving more and more rapidly beyond reach? Or, to the contrary, do these increased forces provide healthy pressure to force the MDx pieces to snap into place (diamonds…)?
The pressure here is the increased necessity to manage the following problems: large or complex build- and deployment scenarios; the management of inter-component interface and data dependencies over their life cycle; the DRY and SoC production and maintenance of these components themselves; and the increasing necessity to adopt business solutions to fast evolving technology over and over again. All these problems *are* already addressed by models, but only as such facets.
The solution? Years ago, MDx technology stopped to face that challenge as a whole since it seemd far too large. It therefore could not develop corresponding abstractions, capturing all that in a satisfying way: persistency, logic, user interface, services, processes, systems, components, architectures, landscapes, actors, and purposes.
There is much material and experience available now, that are dare to say it is possibly to go fo that integration.
I received two comments via email, which I would like to share, including my reply:
Q: Doesn’t this proposal heavily violate the principle of “Do the simplest thing possible”?
A: I do not advocate at all to let this happen within customer projects. The appeal is addressed to the tool provider community in a broader sense.
Q: Isn’t Enterprise Modelling exactly what I’m looking for?
A: Maybe from a point of view of scope, and for sure there are valuable assets to be found – yet I would argue that some “refactoring” is necessary to meet all 24 criteria.
Hi Andreas,
In projects where we do not use modelling we are document-based. Problems with using documents on large (not small) projects is the number of documents and information scatter among them. Dependencies are not explicitly known, therefore, an update to one document may (or may not) require an update to one or more others.
Often, I find the same concept defined in at least 2 documents and dependencies to it scattered in several other documents. This reminds me of copy-paste programming. It is very hard to get it right if you do not make some order in your activities.
Can the Modelling Biotope help me solve this recurring problem?
Thanks and regards
Milan
Hi Milan,
thank you for your question.
I think the main part here in keeping things tidy is still mostly a matter of “information gardening”, someone has to care and do the work, and it must be appreciated by the team.
Nevertheless, there are obstacles that can and should be cleared out of the path so that the invests are not wasted:
– a clear concept of where to put the information, which is in my opinion a major reason why information gets scattered, since often people simply do not know how to do it better
– direct rewards for doing things properly, like nicely presented automatically generated documentation (…automatically generated solutions…)
– a fun factor
In these regards an improved modelling environment could contribute, I think.
Kind regards
Andreas
Hi Andreas,
True.
I remember using Rational SODA to generate documents from my Rational RT models. When I changed the models I would generate the source code, compile it and run the tests. After all went well I would check in my changes. The documentation was updated by the continuous build servers.
Of, course, I had to make sure that the changes did not affect any non-generated documents and update them manually – such an uninspiring task.
Do you know, have experience, with any contemporary tools to generate documents from formal artefacts?
Thanks and regards
Milan
We’ve worked with some reporting/EA tools in environments provided by our customers, but I’m not much of an expert here. After various attempts with document generation libraries the way that worked best for us is using a good template based generator and create Open Documents from there as well as LaTeX documents (yes, still). The former works pretty well, since Open Documents are internally xml based and easily templatable based on document prototypes. The latter is preferred if more sophisticated rendering is required. The creation from modeling artefacts is done in a two-step process: first, from all artefacts socalled ‘Doclets’ are extracted, which are basically docbook- or markdown-based snippets with additional metadata, and the second step is to render this together into whatever target format is desired. The Doclets are associated to items of a conceptual overall structure, consisting of the overall system, it’s components etc.. Using this approach also the non-extracted pieces are associated with well-defined locations, and are edited manually as Doclets. They are never overwritten, and the redundancy is fairly low. Today, we mostly generate HTML documentation from this. But depending on your modelling environment that may work or may not, probably some integrated document generator should be the first choice if such is available.
Hi Andreas,
during the last 3 decades I experienced simimlar misconceptions by developers and MDx users. For many years I tried to address the problem of “Making MDSD mainstream” by developing MDx tools (see e,g, https://modeling-languages.com/alf-standard-programming-language-uml-slideshare/, https://www.infoq.com/presentations/mdsd-mainstream?utm_source=infoq&utm_campaign=user_page&utm_medium=link
or http://blog.metamodules.com/).
I am discouraged by the “migration” of many researchers and practioners in MDx to the programmer’s DSL community. Even one of the most important conferences about MDx (CodeGeneraton in Cambridge) was shut down some years ago. So I stopped/paused my efforts waiting for the next level of technological improvements to start over again .
Currently IHMO the hype of agility is destroying quality-oriented development (generation) of software based on well-planned and modelled specs. I think the “gorge” that has to be crossed to reach the customers and developers becomes deeper. 🙁
If you like to discuss potential approaches, feel free to send me a personal email.
Regards,
Juergen
“Currently IHMO the hype of agility is destroying quality-oriented development (generation) of software based on well-planned and modelled specs” – Agreed!
“I am discouraged by the “migration” of many researchers and practioners in MDx to the programmer’s DSL community” – I could see DSLs only as a flexible way to integrate not covered aspects of development to models.