

The previous post on refactoring modeling technology dealt with basic syntax issues of modelling languages. While this user experience side of the equation is not to be neglected, there are quite more challenging aspects. A crucial question is that of well-separated concerns, which constitute the architectural backbone of any modelling ecosystem. Our goal is to craft a firm fundament which does not just collapse into dust, like too many modelling architectures did before.
Before we can do that, we need to sharpen our terminology and some categorisations, with which this post is concerned.
(requirement 14, Model Discovery – find models, identify their role)
Inheritana Jones and the Golden Repository
Having fought the mechanical dragons of Cath’edrâl and sprinted with constant velocity over the monotonous plains of Agîlë, the hero reaches the Isolated Island and enters the Golden Repository. Inside, bright light shines on thousands of inscripted tablets, containing the purest wisdom of mankinds modellers… …but behold: the tablets are cursed! They all show just tiny variations of one and the same drawing, three rectangular boxes with a few strokes inbetween!
Maybe you’ve encountered the same irritation when accessing one of the model repositories that were designed to foster collaborative model exchange and reuse, but contained next to nothing of immediate use, except for illustration and inspiration. The author, too, designed such a great repository once.
Model repositories were designed to foster collaborative model exchange but most contain next to nothing of immediate use Click To TweetWhen talking about models and abstraction levels, people tend to understand very different things by the term ‘Model’ and usually it is all but clear what to do with a given one. Worse, not just their contents, but also their storage formats differ so much that it seems there is a 1:1:1 correlation between models, model formats and tools to read them.

Composition, Washing, Ironing – Model Conformance & Care Tag
As a simple attempt to bring more light into a quick human grasp of models, here’s a suggestion for a Model Conformance & Care Tag. The meaning of the various symbols is explained in the following.
We will use the introduced terminology in the next post concerning architectural abstractions and separation of concerns.
Feel free to provide more categories in the comments, I’m happy to integrate them here – at least the first 100 suggestions 😉
Washing symbols are a universal way to quickly explain key properties of a piece of cloth and how you should handle it. A similar approach for models would help designers to understand the context, goal, quality,... of a model they just ran into. Click To Tweet
Modelling ObjectWhat is modelled? Obviously, we should know what it is we’re talking about. This question might sound a little silly, but consider that even the most simple object-oriented class diagram already raises the question whether it’s a description of the business domain or of the inner fabrics of some technical solution, or both a business system and an IT component at the same time balancing the forces from both sides (OO in a nutshell). Here are three main categories that can serve as a start. Many more categories are imaginable. |
|
 |
Economical System or Component
In typical IT application scenarios usually used to illustrate the economical context of business or IT systems, more open and less (or not) controllable easily, the area of conventions, standards, laws or other regulations. |
 |
Business System or Component
Business here denotes a company or an organisation, but generally any kind of a system with a well defined boundary within which coordinated, goal oriented activities take place and which in tis entirety is controllable by some defined group of stakeholders. A Business System or Component then is an entity on that level ob abstraction. |
 |
IT System or Component
To represent IT parts as real-world entities which play a role in a business or maybe economical context. Note that the primary purpose and relation is not abstraction, but containment: an IT component can be used as a tangible part of a Business System. |
Modelling ViewFrom which perspective modelled, for whom? The category of an object and the perspective of the model can differ, it is e.g. possible to describe an IT system from a business perspective as well as from an IT perspective, or from multiple, aligned perspectives at the same time. |
|
 |
Economical Context
Relevant aspects might comprise financial or product properties, demands, various flows of goods, cash or data, large scale social interactions. |
 |
Business Context
Concerns like strategic and tactical management, organisation, operations, interactions, landscapes, and installations. |
 |
IT Context
From the perspective of application production and deployment, application systems, os & web services, computing, hardware and alike. |
Modelling AspectWhich properties of the Modelling Object are modelled? |
|
 |
Function
The function of the modelled object within its surrounding system, the reason why it exists or shall exist, goals that shall be accomplished with its operation. |
 |
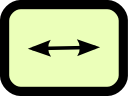
Interface
The interface between the modelled object and its surrounding system, comprising other components; i.e. the outside view of its boundary. |
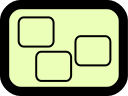 |
Architecture, Organisation
The inner structural breakdown of the modelled object; in case of a business system that might correspond to its organisation, in case of an IT component to its architecture. |
 |
Activities
What happens inside the modelled object, which processes exist, which activities take place, how they are coordinated. |
 |
Specification
Detailed description of it’s inner workings, comprising implementation, functioning, data structure/schema, aggregate boundaries; rules, logic; aggregation; states, transitions, events; conditions, constraints, privileges; computations, algorithms; data transformations, modifications, transfer and retrieval; transaction boundaries; design, layout, styling. Note: this describes only the intent, nature and possible amount of the modelled information, it does not imply that the information is described in e.g. a programming language, or that all these informations are necessary. Still, the long list might indicate that more thoughts need to be spend on this topic. |
 |
Integration
Bindings to commodity services, like user interface and database; a very abstract description of properties that enable such commodity services to provide the desired functionality; like ‘physical properties’. |
 |
Infrastructure
Represents the infrastructure of the modelled object; for an IT component this comprises e.g. it’s production, deployment or operations system (software development process, unit, artefacts etc.), the description of it as an artefact, it’s installation environment, analytics and alike. |
 |
Location
Deals with the location of system components within landscapes, like physical placement or network addresses. |
Modelling GenericityHow generalised is the model? As mentioned in the first post, this might seem like a matter of more scientific interest, but misinterpretations arise from not clarifying that. |
|
 |
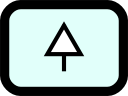
Instance
Describes an actual instance of something, e.g. a concrete and specific business system of the company one is dealing with, or a specific project, but not a workflow. |
 |
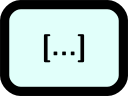
Class
Describes some group of instances with similarities, the relation to the class is kept after instantiation. The canonical example surely is the (domain or programming) Class, also a workflow is likely a class (of workflow instances) |
 |
Template
Describes some group of instances with similarities, no relation is kept after instantiation. A typical example is a modelling template that is to be filled out by the modeller. |
 |
Sample / Prototype
Is an example that serves as an illustration or prototypical exemplification. E.g., a Use Case often serves as a mere sample. |
Modelling Language
|
|
| Name
The name of the modelling language. |
|
 |
Language Specificity
The specificity of the modelling language (business, neutral, technical), i.e. the area to which the conceptions and terms of the language belong; a typically DSL might use business terms, UML is more or less neutral with a technical bias, and Java essentially technical. |
 |
Content Specificity
The specificity of the modelled content (business, neutral, technical); e.g. a workflow might be business oriented, while a data transfer protocol rather technical – both could be described with one and the same language. Usually, this will be a subset of the language specificity, and derivations from this rule deserve a second look. |
 |
Concept Specificity
The specificity of modelled concepts (business, neutral, technical), which is the concepts we have in mind when describing our content; admittedly, this category is a bit nitpicking, nevertheless let’s include it: concepts and content might differ, e.g. a model described with architectural concepts can still be a good object oriented model that reflects a domain system and a technical system simultaneously, so that the modelled content is domain oriented as well as architecture oriented; also, concepts and language can differ, e.g. we might want to use Java as our single source for modelling and consider the modelled classes as describing our domain model. |
Modelling Quality
How well is the aspect modelled? The second part of the blurb provides the quality of our modelling effort. Of course, since presently it might be hard to find quantitative measures, a specification of these properties requires a good deal of honesty, with regard to others but also with regard to oneself. Within a healthy team, the classification can help to gain valuable insights. |
|
 |
Coverage (completeness of this aspect)
How horizontally complete a certain aspect is, i.e. whether all parts of the modelled aspect are covered, leaving no open white spaces. E.g., a navigation model for a user interface can be considered complete if all pages are represented, since the aspect is just these pages and their relations. (requirement 8, Modelling Coverage – how horizontally complete a certain aspect is) |
 |
System Coverage (completeness of system)
To which degree all aspects of the described target are covered. E.g., a contemporary MDx model describing an IT system might comprise the business data and logic, but lack the user interface. A low system coverage is not necessarily a shortcoming, it might be intended and indeed be a sign of good separation of concerns, if the various aspects are covered in well separated models. (requirement 9, System Coverage – whether all aspects of the target are covered) |
 |
Precision (implementability)
How vertically complete the aspect is modelled, i.e. whether the details are described in the required precision. Even within full coverage the description can be vague, and sometimes this openness might be intended and justified, e.g. a workflow defining only a goal, but not the precise procedure of achieving it. In this case the indicator can be used to clarify if the openness is intended or whether not. (requirement 10, Modelling Precision – how vertically complete it is) A completeness of all aspects of 100%, of the system of 100%, and implementability of 100% imply that the corresponding component is fully specified and it should e.g. be possible to automatically create it. |
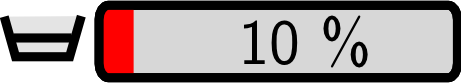 |
DRY-ness (freedom of redundancy)
(requirement 13, Modelling Quality – DRYness and SoCness) Whily everybody would agree that DRY-ness is a natural goal, it is not just that most systems are far from truely DRY, but rather that the impact of DRY-ness is not questioned consequently enough. For starters, here’s a suggestion for a finer classification beyond just “DRY/not so DRY”. For a given information artefact and with respect to a certain given concern (one of many), we can distinguish degrees of DRY-ness:
For a given set of models covering some system and a given concern we would like to have exactly one model DRY-1 and all the others DRY-0. The overall “DRY-ness” here on our tag then is some sensible average over all relevant concerns – good judgement provided. |
 |
SoC-ness (degree of separation)
(requirement 13, Modelling Quality – DRYness and SoCness) The same observation as for DRY-ness holds for SoC-ness. Similarly, here’s a finer classification beyond “separated/not so separated”. For two given information artefacts and with respect to a certain given concern (one of many), we can distinguish degrees of DRY-ness:
For a given set of models covering some system and a given concern we would like to have only SoC-1 or SoC-0 relations to the one and only model that covers this concern in a DRY-1 fashion, as described above. Again, the overall “SoC-ness” here on our tag then is some sensible average over all relevant concerns. |
Man and Machine
The listed categories can help to understand what the purpose of a given model is. But what should a machine do with them? First, the classification depends on human judgment, specifically the quality rating, and is thereby a bit arbitrary. Second, it is still far from precisely defined what to do with the model.
Lately, on the Death Star
I’ve always been deeply impressed by the sequence in Star Wars where R2D2 injects his universal plug into the Death Stars universal socket, and it just works – compare that to today’s compatibility issues on good old earth, even between devices from the light side.
Attaching and finding metadata is straightforward, there is no lack of approaches. Every tool does it, some with gruesome ad-hoc semantics, which limits their applicability and causes a good deal of fragmentation. While it seems a challenging task to define ‘the’ metadata format in general, we cannot close our eyes and avoid the problem for the modelling domain, since already within its limited scope there are plenty of players who need to be united.
In the spirit of what was said on basic syntax properties of a good modelling language, a good metadata format should:
- be united among single artefacts and packages (folders, archives), since both are often tightly intermingled
- match different tastes – sure, presently many people might agree on JSON format as the only thinkable choice, but let some 5 to 10 years pass, it wouldn’t be the first time (wait… isn’t YAML the better choice…)
- restrict the capabilities of such syntax styles – since these files need to be parsed from everywhere, even sometimes with a bash-script
- agree on a basic property named “type”, whose value is an array of rDNS names – this is a classification of what’s within the respective artefacts; it’s an array since one and the same artefact may contain material for different processors (think of a folder containing a maven, eclipse and .net project at the same time); it’s a rDNS name to enable extensibility out of the box
- put everything else in rDNS scoped containers
- dependingly, agree on a variety of non-overloaded least-common-denominator properties, depending on respective needs, and put them into respective rDNS containers, like e.g. title, author etc.
That again, as with models, leaves us with the tricky question of which conceptions to use. How can we unambigously describe the role of a model within a project setup?
IDEs and other tools do that with good guessing based on file names and locations. Such mining strategies are helpful, and could be employed to e.g. annotation scanning in source code in github to extract modelling artefacts in the first place. But it is unlikely that these approaches scale well enough if we broaden the range of modelling artefacts, as is our plan. Moreover, it should be the goal to provide a clean interface for tools to build upon.
Divide et impera
Separation of Concerns is a widely undisputed goal in IT architecture, and many attempts have been made to apply it to a broad variety of problem areas.
Both with our design of a good modelling language and with corresponding metadata we reached a point where we need to take a closer look on the matter we’re dealing with. There are many valuable approaches to build upon. This will be the topic of the next post.
Previous post concerning miotope: Refactoring Modelling Technology – Say It Clear
Next post concerning miotope: Refactoring Modelling Technology – Concerning Concerns
I’m working in IT since the late ’80ies of the last century. Half of my time I spent crafting software of various kinds for customers, increasingly based on model related technology. The other half I invested in research and development of a fully model driven software production system and respective suitable concepts, most of which is available as open source or creative commons. Since the beginning of the millenium I’m doing this in my own Hamburg-based company and offering software production as a (model based) service — Andreas


Recent Comments