

The first miotope article tried to motivate you to reconsider the matter of modeling more courageously, by pointing out the discrepancy between present unsolved challenges and the neglection of respective opportunities, and to layout a possible direction for modelling technology based on a comparison with more successful approaches.
The next posts will suggest specific approaches that address one or more of the 25 requirements of part one, not necessarily in a one to one correlation. To begin with, I’ll focus on discussing a language that is capable of being useful, usable, and used. This post here deals with basic issues: which syntax is nicest? How to tame presentational complexity?
Say It Clear – On good language syntaxes
The miller, his son and the donkey
(requirement 1, Syntax Basics – a language should be writable with ease)
There’s this nice old fable about the difficulties one encounters when trying to please everybody, and our decades-long provider journey to find an “ideal model presentation” to satisfy all customer wishes can be told as a similar story, here’s the short version:
XML is for Techies and old-school, Visio unloved by technical people, spreadsheets even more unloved and limited, dia unloved by business people, XMI too fragile and clumsy, UXF too unkown and non-standard, UML purportedly has failed, Eclipse loads too slowly and crashes too often, JSON is too limited, YAML too magic for business people, MarkDown not a modelling language, your proprietary solution too proprietary.
It is clear that there is no single best solution, but still there are approaches which do work to some degree, for some time, and for a respectively limited but relevant group of users. The following samples are taken out of real world projects, where they proved themselves and received some love:
 |
MDx Classics – The Diagram Rather familiar. |
 |
MDx in the Cloud – Browser Based Diagram This sample is taken from a selfmade model editor, based on SVG. Please note the beautiful 3D effect and the elegant shadow 😉 |
 |
Serious business – Spreadsheets Qualified for upper level presentations and emailable to everyone. The careful observer possibly notes a resemblance to MarkDown – but no need to tell, is it? |
 |
Polished XML Born out of some frustration with XMI in the stoneage of modelling, and inspired by good old UXF, here’s our class in XML. While still bearing some of that XML-ish clumsiness, it is fairly readable and maintainable by hand. |
 |
Oldschool, Middleschool… JSON When XML started to become old-fashioned and JSON obligatory, this one here was inevitable. It loads faster. Nice? Your mileage may vary (but that’s the point). |
 |
MarkDown. MarkDown? MarkDown! It’s definitely compact! We first introduced this language within our model wiki to be able to write models inside the wiki pages (press ‘view source’ on the pages there). Maybe one of the easiest way to write models. You can also ‘draw’ diagrams this way (‘view source’…). |
 |
Cutting Edge Typewriter – YAML When I see those dashes, I’m always reminded of an old teleprinter “…incoming transmission, tactactac, squeak, …”. |
 |
Poor Mans Model – Annotations That’s also a possibility. Similar annotations like for persistency (JPA) or REST APIs (swagger/openapi) could be reused for our purpose. |
 |
Late at night, hunting bugs The deadline is tomorrow, and you need to inject urgently some test instance via the debugging mode backdoor parameter in the URL of your frontend into the server… here’s how. |
|
???? |
The SVG, PWA, git and OCP based Most Awesome Modelling App… …which unfortunately does not exist yet but which would be a true gift to mankind (anybody interested in joining efforts?). |
Textual formats
Jordi composed a great list showing many more textual approaches, obviously of use for the one or the other audience.
One fine advantage of concise, noise-free textual models is that they can be easily put under version control. By keeping the various modelling artefacts in separated files, organised in a package hierarchy, this approach works conveniently well.
(requirement 19, Model History – put models under version control)
Of course, diagrams can benefit from such formats, too, by using them for storage and thereby become versionable. The remaining, rather few conflicts are of the same quality as with program code, where this is routinely solved either by the merge algorithm or by few human interventions.
Technically, this implies managing (reading, writing, monitoring) a file tree, as well as managing inter artefact (forward, cyclic) references.
Parallel Universes
So what to do about this multiplicity? Models affect a broad audience, and if we want to succeed we cannot just neglect some stakeholders. But we do not have to! In contrast to the poor miller and his son, as IT people we are in the convenient position to be able to serve all these variants at the same time, by, of course, separating the abstract syntax from the various presentations.
Models affect a broad audience. Create a different concrete syntax for each kind of stakeholder to serve them all in the best possible way Click To TweetThat leaves two problems: separating these both layers technically, and finding an abstract syntax that is universal enough that the effort is justifiable.
Enter: Object Construction Plans
To substantiate the feasibility of these requirements and as a solid reference implementation, let me introduce a piece of technology. It is a component in Java that came into existence by mere chance and evolved over the years more or less unsupervised into something increasingly useful.
Born in the last century as a simple XML test data loader, soon used for other things like configuration files or application master data, this component became a universal utility for reading descriptions of arbitrary objects, how they are to be instantiated and how they are to be connected. Correspondingly, these descriptions were named “Object Contruction Plans (OCPs)”, and the tool “ObjectAssembler (OA)”. Features were added ondemand over the years, like scripting, factory networks, precompilation, embedded metadata and documentation, object orientedness, modularisation and other magic.
The OA reads some description into an abstract syntax and from there looks up dynamically matching interfaces, classes, factories or retrievers. From these it constructs an appropriately interconnected factory network, which can then be used to create the described instances repeatedly, even parametrised.
In other words: if you have Java classes for storing your model, you’re done.
You get, mostly out of the box, a concise language for describing your models and a tool for parsing them. Actually, you get a XML, a JSON, a YAML, a MarkDown, a SpreadSheet, a Diagram, and an URI based language, since most samples from above are working, realistic samples of OCPs. “Mostly” out of the box, since some optional fine tuning might be required to make them look truely nice and noiseless.
Since OCPs can be parametrised, on top you get a fine model transformation langugage that can project foreign objects into your model schema.
Which, on top of that top, can be used to craft small or large DSLs on the fly, even your customer can.
More infos can be found on xocp.org and feel free to become addicted yourself.
The OCP approach separates the concept of syntax taste from specific abstractions. More than that, OCPs push the matter one step further by using a technically universal abstract syntax (a factory network) and passing the question of semantic universality to the specific model schemata used. Due to this approach there is a potentially high return of invest in developing a specific syntax frontend: it’s usable immediately in all scenarious where OCPs are used.
As stated in the first blog post, you always reach the point where your ingenious concept reaches it’s limits. The principle of “doing the simplest thing possible” should not be misused as a flimsy excuse for laziness: your users might be in a position where they cannot just file a bug report and take vacation until someone is in the mood to solve it.
OCPs offer a sound variety of tools to extend or modify the provided defaults conveniently: Samples are numerous: adding own properties to the model cleanly, modifying the syntax, beautifying the syntax, overlaying it with a mini DSL, dynamically calculating parts, replacing the syntax completely with your own, loading different things based on server configuration, last not least fixing bugs in foreign components, and more.
(requirement 24, System Override – soft landing with recursive pareto (80/20)*)
Fighting Hydra
(requirement 1, Syntax Basics – a language should be writable with ease,
requirement 13, Modelling Quality – DRYness and SoCness,
requirement 17, Customised Model Usability)
Removing syntactical noise is one thing, tackling overall complexity quite another. Simplifying our models – to make them more accessible – requires also to clear up the contained information – which is easier said than done, since it’s like fighting ancient monsters: remove complexity at one place, it shows up it’s heads at two others.
Typical models serve either just as documentation or illustration, or otherwise if used as precise specifications they need to be augmented with vast amounts of additional information around their core structure. We’re talking about properties, extensions, stereotypes, generation models and the like. Where to put this information?
Of course the answer depends on the type of information, which needs to be examined case by case. A frequent answer to the problem, then, is to use appropriate abstractions – which will be addressed later. But if the details are removed from the high level model, somewhere else must be a place to specify them. Moreover, according to our Recursive Pareto requirement, as a last resort, we should assume that there will be a certain amount of ugly stuff anyway. Where to put it?
UML provided stereotypes and tagged values. If used for fully model driven production the models became heavily overloaded, and due to the simple nature of tagged values (basically named strings) more or less unmaintainable. An alternative approach is to extract all these details into other places, like generation models. Thereby, at least the core model becomes readable, but the rest is still a mess.
High-Profile Profiles – The ideal UML profile mechanism
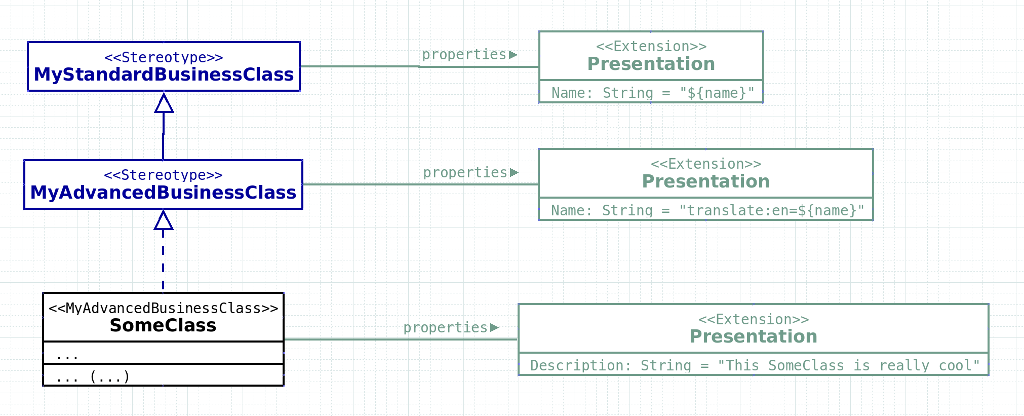
While UML Profiles with stereotypes and tagged values are too limited, the mechanism can be built upon. Consider the following advancements (the diagram above illustrates the idea; of course this is a first hand example for motivating the removal of syntactical noise):
- Organise “tagged values” into classes – just for the purpose of better organisation group your properties logically, like, e.g., a “Presentation” class, which might provide a multilingual name and a human readable help text. These are not stereotypes, let’s call them Extension Classes.
- Use “Extension Classes” as attributes of your stereotypes – say, you’ve got a “MyStandardBusinessClass” stereotype, then it makes sense to give it an attribute of our extension type “Presentation”.
- Rename “tagged values” to “extension properties” – to get rid of the connotations of “looseness” and “arbitrariness”
- Introduce a scoped syntax for “extension properties” – to group them by extension class
- Allow extension properties without stereotypes – this was eliminated with UML 1.4, but makes much sense with our modifications
- Use stereotype inheritance – to introduce e.g. a “MyAdvancedBusinessClass”, which is derived from the standard one
- Allow a Stereotypes’ Extension Classes to be type sensitive – then, if a Stereotype is applied to an Attribute or an Operation, the corresponding Extension Class is only applied if the type matches; e.g., a general ‘Optional’ Stereotype might provide certain conditions for a variety of types
- Allow a Stereotypes’ Extension Classes to be context sensitive – then, if a model or part of it is interpreted within a certain context, only matching Extension Classes will be applied; e.g. a model might be used for implementing a ‘Server’ or a ‘Client’, here of course very different properties might be required
- Introduce calculable default property values – and now for the fun part: allow the specification of property values at stereotype level with expressions, which are evaluated in the model context (or a variety of others). E.g., provide a default value for our Presentation name property as “${name}”, which implies to use the stereotyped class’ name as the default presentation name, but allow it to be overridden by either derived stereotypes or by extension properties at class level.
- Use patterns – a pattern is a generalisation of the stereotype concept, which is not attached to a single class, but to a group of classes, where each class plays a defined role. The whole magic explained above is applied here to all participating classes, the pattern specifies extensions properties according to their role, and the expression evaluation contexts spans the whole construct.
I’m not sure whether these suggestions are within the current formal scope of UML, some time ago we’ve experimented with some UML modelling tools and failed. But either way, they are at least not far away from the standard.
This mechanism is no theory. With it’s help we’ve been able to swap out piles of model properties in real world customer projects into well organised stereotypes. The information in these stereotypes controls and contributes to transformations and code generation, which do not require to be maintained within each specific project then.
Over time, these Stereotypes evolved from mere containers for the ugly properties into an emerging hierarchy, which became more and more fit to be used as high level abstractions in domain oriented models.
Patterns are specifically powerful. Used in the beginning mostly for behavioural constructs in the user interface domain, they started to become an irreplaceable means to model distributed components and their interrelations, most notably in a microservice context.
In a nutshell, the OCP concept together with a more flexible extension mechanism allow us to keep the basic levels of our models tidy and more appealing to various stakeholder groups. At the same time, there is plenty of space for adopting them to new environments.
Previous post concerning miotope: Harvesting and Reimagining Modelling Technology – 25 requirements for a modeling biotope
Next post concerning miotope: Adventurous Archaeologists and Omnilingual Droids – Orientation for Discovering Models
I’m working in IT since the late ’80ies of the last century. Half of my time I spent crafting software of various kinds for customers, increasingly based on model related technology. The other half I invested in research and development of a fully model driven software production system and respective suitable concepts, most of which is available as open source or creative commons. Since the beginning of the millenium I’m doing this in my own Hamburg-based company and offering software production as a (model based) service — Andreas


Hi Andreas,
in the paragraph about the UML profile mechanism you have the old UML 1.x spec of profiles and tagged values in mind.
I would like to bring to your attention that with the UML 2.x (first version published in 2005) the complete super structure of UML was revised and tagged values became regular attributes.
We have already used the UML 2.x standard mechanism to implement hierarchies of extension classes, which implement generators and validators. These classes are fully fledged classes with algorithmic functionality which can modify the context of the applied stereotype by MOF mechanisms.
Therefore the proposed (calculated) extension porperties/classes are covered by the spec.
Regards,
Jürgen
Hi Juergen,
thank you for pointing that out. I removed the “tagged value” requirement above, this is certainly an outdated item in the list.
It would be interesting to use the algorithmic functionality to reproduce also the behaviour of type and context sensitivity, maybe even patterns. Do you think (or know) this is possible?
Regards,
Andreas
Hi Andreas,
a good summary of the current state of standardization, experiments, and research can be found here:
“Execution of UML models: a systematic review of research and practice” by Federico Ciccozzi1 · Ivano Malavolta · Bran Selic (free download at
https://rd.springer.com/content/pdf/10.1007%2Fs10270-018-0675-4.pdf)
IMHO for “Saying it Clear” we need a common set of definitions of THE basic elements of modeling (maybe a ontoloy of modeling?). I have still the impression, that there are many contradicting “opinions” about things like ‘model’, ‘concept’, ‘logic’, ‘language’, ‘behaviour’, ‘pattern’, ….
The standardization process of UML has come a long way (20 years) and even if somebody does not like the results, there were put enormous effort into the definition of the abstraction of modeling and the accompanying concepts and terms, which can be (re)used.
It is frustrating to struggle again and again about definitions like,
What is a ‘metamodel’?
What is the difference between a ‘model’ and a ‘language’?
or even to explain the differences between a ‘behaviour’, ‘activity’ and ‘action’.
Regards,
Jürgen
True enough.
Matters are further complicated since even the core semantics are still on “shifting grounds”. See e.g. https://www.wi-inf.uni-duisburg-essen.de/MULTI2018/, an approach which questions fundamental concepts of OO style inheritance, or my own contribution of http://www.ubpml.org/, which questions just named semantics of activity/action. Maybe worse: I’d like to challenge the assumptions behind “executable” Models.
I think the problem up to now is that modelling languages lack grounding. I do not say there are no samples for grounded projects (indeed, there are), but that grounding is not widespread. I think it cannot be achieved by defining terms, but by additionally providing tools that tightly bind the concepts to implementation reality. Some say that definitions are secondary or even superfluous and only usage counts – an opinion I do not share, good definitions are necessary to achieve good results, but they are not sufficient.
That grounding is necessary to enable maturing of the concepts. There is of course a grand pool of good concepts available, but not a unified and working one across the whole application area of modelling. In the 2nd next post on miotope I’d like to share my view on 4 important abstraction areas: the model transformation axis, the application architecture, the fundamental domain concepts, and the artefact production axis.