

The Eclipse Modeling Framework (EMF) is well-known in the modeling community as the go-to option when creating (meta)models in a programmatic way using Java. EMF is a strong and stable framework, used by/in many tools but when it comes to quickly experiment/test in a programmatic way with new metamodels, EMF-Java (actually, especially Java) is quite heavy. Moreover, dynamically adding/removing behavior or evolving metamodels is also a known difficult task. One way of outer passing these limitations tends towards the need for scripting metamodels/models/EMF.
This idea of scripting EMF is not a new one, but it implies that Java must be avoided to the benefit of a scripting language. Among the “scripting oriented” languages, Python is a perfect candidate for this kind of work. It is quite light and follows a strong object-oriented paradigm. It also provides facilities for introspection as well as a simple syntax, which is, in a way, close to an OCLish syntax.
Our goal is to propose a way of handling metamodels/models with Python in a “compatible way” with EMF-Java, to take benefits from all the great Python features. Moreover, the Python implementation should try to keep the basic Python object syntax and give the illusion that simple Python objects are handled. In this context, PyEcore provides a Python implementation of EMF. The main idea of PyEcore is to be compliant with EMF and it’s XMI format to be able to easily move from an implementation to another and to choose the best paradigm that fits you for a dedicated work.
PyEcore provides a Python implementation of the Eclipse Modeling Framework Click To TweetHow does manipulating modeling objects in PyEcore look Like?
First, let’s take a quick look at the syntax provided by Python and PyEcore to handle models. We will use the following metamodel to illustrate our examples (you can find more details at this address).
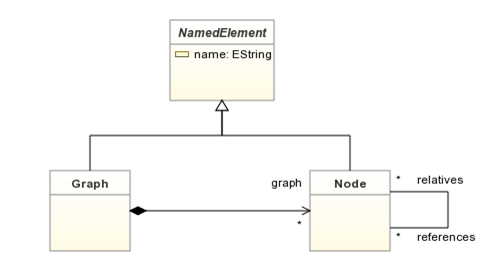
Example metamodel for pyecore
Here is a little example that will create a ‘Graph’, set its name and adds 2 ‘Nodes’ called ‘a’ and ‘b’ in the ‘Graph’. Moreover, the ‘a’ node will have a reference towards ‘b’.
# Simple instance creation g = Graph() g.name = 'my_graph' a = Node() a.name = 'a' b = Node() b.name = 'b' a.references.append(b) g.graph.extend([a, b]) |
This is as simple as that. At first sight, it only looks like a classic Python object creation and references. However, if we look a little further:
assert b is in a.references # Naturally assert a is in b.relatives # eOpposites are managed by PyEcore assert a.eContainer() is g # 'a' is contained by 'g' |
And if we look a little bit further, again:
>>> a.myattribute = 123 # We can add new instance attributes (not in the metamodel) >>> a.name = 123 .... (stack trace here) BadValueError: Expected type EString(str), but got type int with value 123 instead >>> a.references EOrderedSet([]) >>> a.eClass |
We can see that:
- eOpposite relations are managed,
- there is type checking on attributes/references defined in the metamodel,
- extra attributes can be added as instance attribute,
- PyEcore supports introspection,
- there is no factory object to create the instances,
- there is no getter or setter like functions
This section gave you a brief overview of how instances are handled in PyEcore. Now, the remaining question is simple: “How to create a metamodel in PyEcore?”.
Handling metamodels in PyEcore
First, let’s take a look to the features provided by the EMF Java API. There are two major way of handling metamodels and models, dynamic and static metamodels.
Dynamic Metamodel
Dynamic metamodels are created in memory. They can be read from an .ecore file or built from scratch using Dynamic EMF. Their manipulation is quite heavy in Java as it deals with the EMF introspection mechanism. Using PyEcore, the creation of a metamodel looks like this:
from pyecore.ecore import * # We import everything from PyEcore Ecore # We create each metaclass instance and we add their features NamedElement = EClass('NamedElement', abstract=True) NamedElement.eStructuralFeatures.append(EAttribute('name', EString)) Graph = EClass('Graph', superclass=NamedElement) Node = EClass('Node', superclass=NamedElement) Node.eStructuralFeatures.append(EReference('references', Node, upper=-1)) Node.eStructuralFeatures.append(EReference('relatives', Node, upper=-1, eOpposite=Node.eStructuralFeatures[0])) # all on a single line Graph.eStructuralFeatures.append(EReference('graph', Node, upper=-1, containment=True)) # At this point, you can already handle mode instances, # but we will define the container of all these elements GraphMetamodel = EPackage('graph', nsURI='http://sample/1.0', nsPrefix='graph') GraphMetamodel.eClassifiers.extend([NamedElement, Graph, Node]) # That's it, you can create an instance of your Graph as seen on the previous section g = Graph() … |
This simple example shows how to build a dynamic metamodel using PyEcore. In addition, dynamic metamodels are very flexible, you can, at runtime, add new features, new metaclasses, add behaviors (see below)…
Static Metamodel
In EMF-Java, the static metamodel is generated in plain Java. The code generation provides a Java API allowing the user to implement some special behavior and/or refine some of the basic ones. PyEcore proposes also to generate the Python code from a metamodel. In EMF-Java, the generation is performed from a .genmodel using JET templates, whereas in PyEcore, the generation is done by an Acceleo script reading the .ecore. The generator is available as a single script: https://github.com/aranega/pyecore/blob/master/generator/ecore2pyecore.mtl that you can import and use directly in Eclipse or GenMyModel (it will also be proposed as a default generator in GenMyModel).
The generator tries to bind the information defined in the metamodel to a Python representation. To do so, it relies on some Python basic as well as the PyEcore library. The metamodel-to-python mapping is roughly the following:
- EPackage = Python package + Python module
- EClass = Python class + special metaclass
- EAttribute = Python class attribute
- EReference = Python class attribute
- derived EStructuralFeatures = Python @property
- abstract EClass = Python class + dedicated annotation
- inheritance and multiple inheritance = Python class multiple inheritance system
The following code presents the generated Python module for the Graph metamodel:
from pyecore.ecore import * import pyecore.ecore as Ecore name = 'graph' nsURI = 'http://testGraph/1.0' nsPrefix = 'graph' eClass = Ecore.EPackage(name=name, nsURI=nsURI, nsPrefix=nsPrefix) @abstract class NamedElement(EObject, metaclass=MetaEClass): name = EAttribute(eType=EString) def __init__(self): super().__init__() class Node(NamedElement): references = EReference(upper=-1) relatives = EReference(upper=-1) def __init__(self): super().__init__() class Graph(NamedElement): graph = EReference(upper=-1, containment=True) def __init__(self): super().__init__() |
We observe that each metaclass is translated as a Python class and that the top-level class inherits from EObject and uses a Python metaclass: MetaEClass. A special annotation indicates that NamedElement is abstract and all the EAttributes are defined as class attribute. You can also notice that EAttribute/EReference instances do not set their name, and EReference instances do not set their type. This module in itself is not fully usable, the Python metaclass does a lot, but this is the Python package which provides the glue so everything works together.
Next we show the Python package that sets EReference’s type and eOpposite relations. As Python does not allow forward references, the only way to deal with them is to simply put them outside the EReference creation. Doing this avoids a complex dependency computation that cannot be elegantly managed in some cases.
import pyecore.ecore as Ecore from .graph import getEClassifier, eClassifiers from .graph import name, nsURI, nsPrefix, eClass from .graph import Node, Graph, NamedElement from . import graph __all__ = ['Node', 'Graph', 'NamedElement'] eSubpackages = [] eSuperPackage = None # Non opposite EReferences Graph.graph.eType = Node # opposite EReferences Node.references.eType = Node Node.relatives.eType = Node Node.relatives.eOpposite = Node.references # Manage all other EClassifiers (EEnum, EDatatypes...) otherClassifiers = [] for classif in otherClassifiers: eClassifiers[classif.name] = classif classif._container = graph for classif in eClassifiers.values(): eClass.eClassifiers.append(classif.eClass) for subpack in eSubpackages: eClass.eSubpackages.append(subpack.eClass) |
Thanks to this implementation, a script that uses this generated metamodel will look like this:
from graph import Graph, Node g = Graph() ... |
You can see that besides the imports, the way of manipulating the model through the Python API is totally equivalent between the static and dynamic version of the Graph metamodel.
EOperations
The ability to add an EOperation is highly interesting in EMF. It allows to provide dedicated behavior to metaclass instances. With PyEcore, EOperations are supported with static generated metamodel (obviously) and also with dynamic one.
With the static generated version of a metamodel, the generator introduces Python class methods that can be implemented directly in the generated code (the default implementation raises an exception). This is the more classical way of adding a behavior to a metaclass. However, as Python treats functions as first-class citizens, it is possible to dynamically add behaviors to a metaclass instance. Let’s see how it works on our Graph metamodel, we will add a new operation to the Graph EClass:
… # I have still 'g' as Graph instance g.name = 'Graph1' Graph.eOperations.append(EOperation('myoperation')) g.myoperation() # raises a NotImplementedError exception Graph.python_class.myoperation = lambda self: print('in graph', self.name) g.myoperation() # writes 'in graph Graph1' g2 = Graph() g2.name = 'Graph2' g2.myoperation() # writes 'in graph Graph2' |
This little example creates a new operation for the Graph element (in a dynamic way) and binds a behavior to it (coded by a lambda). If you look closely, the most strange thing here is the call “Graph.python_class.myoperation = …”. We will see in the next section called “PyEcore Backstage” why.
Notifications
Once again, PyEcore tries to mimic EMF-Java and provides a notification system. This system allows an observer to be notified about all the changes occurring on an element. Its usage is pretty simple.
from pyecore.notification import EObserver, Kind observer = EObserver(g, notifyChanged=lambda x: print(x)) g.name = 'new_name' # triggers the notifyChanged lambda and prints the notification |
More details can be found here: https://github.com/aranega/pyecore#notifications.
PyEcore Backstage
In order to implement the kind of flexibility provided by PyEcore, there is a lot of magic performed backstage. This section explains some of the implementation details behind PyEcore when it comes to instance creation, attribute navigation and operation management.
EClass and Python Class
Python classes and EClass instances live together and keep a strong relationship with each other. Each time an EClass instance is created, a Python class is created as well. The EClass keep a relationship “python_class” towards the created class and the created class keep a relationship “eClass” towards the EClass instance.
>>> A = EClass('A') >>> assert A.python_class is A.python_class.eClass >>> assert A.python_class.eClass is A |
This behavior is the behavior we typically have with PyEcore dynamic metamodels. When you have static ones, each time a Python class with “MetaEClass” as metaclass is created, an EClass instance is created with the same relationships.
To sum up:
- when you create an EClass instance, PyEcore builds and keeps updated a Python class that represents your EClass,
- when you create a Python class with the good Python metaclass, PyEcore creates the EClass instance that represents your Python class.
The following figure shows for part of the Graph metamodel how each EClass/Python class lives and the different conceptual level they refer to.
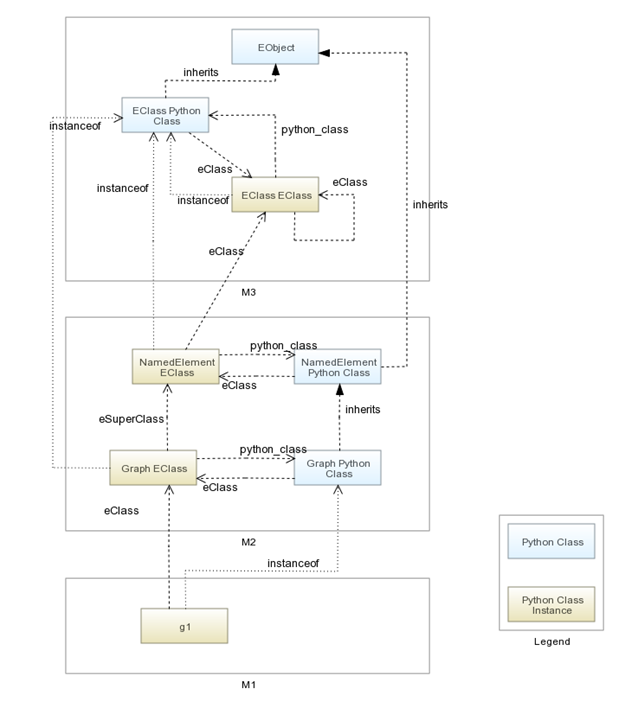
In the M3 level, the Python class ‘EClass’ has a reference towards one of its instance that represents the ‘EClass’ concept. This instance references itself using the ‘eClass’ relationship. When a new EClass is created (instance of the Python EClass class), a Python class is added and vice versa. This figure also clearly shows how you can navigate from an instance to its metaclass.
Python Callable to Avoid Factory
A great thing about Python is its magic methods. One of them enables class instances to be called like functions, this is the __call__ method . As depicted in the previous section, when an EClass instance is created, PyEcore creates a Python class, so it has all the information it needs to create a new instance of the Python class if asked.
To illustrate this, here is how the instance creation looks like without a callable in the context of the Graph metamodel:
>>> g = Graph.python_class() |
From the Graph EClass instance, the created Python class is reached and then an instance creation is asked. Basically, the implementation of the __call__ method does only this and checks that the EClass is not abstract. This way of creating an instance you can call like a function allows you to quickly create an instance of a new EClass while keeping the new instance syntax from Python:
>>> A = EClass('A') >>> a1 = A() |
Python Namespace and EStructuralFeature
When Python resolves an attribute for an object instance, it first look in the instance namespace, if the attribute cannot be resolved, it looks for it in the class namespace which search in its class hierarchy… As Python is dynamically typed, it means that the type of the class attribute can be different from the class instance attribute. This feature is used by PyEcore to handle EStructuralFeature (i.e: EAttribute/EReferences) while still giving a direct access to the EStructuralFeature in the related Python class. The following snippet illustrates this in the context of the static Graph metamodel shows in a previous section:
>>> import graph >>> graph.Graph.graph > >>> g = graph.Graph() >>> g.graph # name is set to default value EOrderedSet() |
What happened here is that we have access to the EStructuralReference through the class while having another value in the class instance for the attribute. When an instance of a PyEcore class is created, the instance is initialized with the default value of each EStructuralFeature in it so the attribute is resolved in the instance namespace and not in the class one.
Python Descriptor for Non-Many Structural Feature
When an Ecore metamodel is described, type constraints are set on EStructuralFeatures. These types must be verified during the model building and must not be violated. As Python is not statically typed, potentially any kind of element could be added inside an attribute. To constrain types on EStructuralFeatures, PyEcore uses an indirection to manage differently “many” attributes from “non-many” ones.
For “many” attributes, PyEcore implement new list types: EOrderedSet/ESet/EList and overrides their basic methods (append/extend/remove…). Each time elements are added to a collection, a type check is performed in order to ensure each added element has the right type.
For “non-many” attributes, PyEcore implements an EValue which performs the same kind of type checking. However, even if EOrderedSet… are directly handled by the end user, EValue are masked to give the impression to directly handled the basic element. This trickery uses Python data descriptor to do this. The following excerpt of code will illustrate this feature in the context of the Graph metamodel:
>>> g = graph.Graph() >>> g.name = 'test' >>> g.__dict__ {..., # other attribute from the instance 'name': } >>> type(g.name) str >>> g.name 'test' >>> g.__dict__['name']._value 'test' |
We can see that the access to the ‘name’ attribute give access to the instance attribute ‘_value’ directly instead of the EValue instance.
Code Generation for EOperation
When an EOperation is inserted in an EClass, an implementation is automatically added inside the associated Python class. This implementation is provided by code generation. A method is called on the EOperation that renders the string that will represent the EOperation body. This implementation is then evaluated and added inside the Python class:
>>> operation = EOperation('operation') >>> print(operation.to_code()) def operation(self, ): raise NotImplementedError('Method operation() is not yet implemented') |
The generated code also tries to keep the semantic defined in the EParameter (only ‘required’ at the moment):
>>> a = EParameter('a', EString, required=True) >>> b = EParameter('b', EInt, required=False) >>> operation.eParameters.extend([a, b]) >>> operation.to_code() def operation(self, a, b=0): raise NotImplementedError('Method operation(a, b=0) is not yet implemented') >>> A = EClass('A') >>> A.eOperations.append(operation) >>> a = A() >>> a.operation() # A required parameter is missing … TypeError: operation() missing 1 required positional argument: 'a' >>> a.operation('test') … NotImplementedError: Method operation(a, b=0) is not yet implemented |
Dealing with Resources: serialization of PyEcore models
Obviously, scripting models and handling everything in Python is great, but without serialization support, all the work done would be lost. Currently, PyEcore supports simple XMI serialization/deserialization using the same format as EMF-Java. By simple, I mean simple XMI files from EMF without fancy save/load options beyond the core functionalities.
To do so, PyEcore mimics the EMF system and proposes ResourceSet and Resource. A Resource is used to keep the content of a model while a ResourceSet is a container for many Resources that can have references from one to each other. These two objects also provide:
- Resource creation,
- Resource load,
- Resource save,
- metamodel registration for Resources loading.
In this section, we will see briefly how to read .ecore/.xmi files, how to write modified resources and how to deal with external resources for model loading and an example.
Reading Models from Files
Each model that need to be read from a file need to be loaded into a Resource. Also, the metamodel used by the XMI model must be registered in a global registry or in a ResourceSet. The first code sample shows how to open a .ecore file using a ResourceSet and the global metamodel registry:
from pyecore.resources import ResourceSet, URI, global_registry import pyecore.ecore as Ecore # We get a reference to the Ecore metamodle implem. global_registry[Ecore.nsURI] = Ecore # We load the Ecore metamodel first rset = ResourceSet() resource = rset.get_resources(URI('./graph.ecore')) graphMMRoot = resource.contents[0] # We get the root (an EPackage here) |
The metamodel contained in ‘graph.ecore’ is now loaded and it can be manipulated.
Graph = graphMMRoot.getEClassifier('Graph') g1 = Graph() # And a little trick if you want to have a kind of 'lib' # you can use reflection to builld one # We build an empty class class GraphMM(object): pass # we add attributes [setattr(GraphMM, ec.name, ec) for ec in graphMMRoot.eClassifiers] # Now you can do this g2 = GraphMM.Graph() |
The exact same process occurs when you need to read an XMI. Let’s say that we have a file ‘g1.xmi’ which conforms to the Graph metamodel. Here is how we could read it:
# First we register the Graph metamodel as a known one rset.metamodel_registry[graphMMRoot.nsURI] = graphMMRoot # Then we load the resource g1_resource = rset.get_resource('./g1.xmi') g1 = g1_resource.contents[0] print(g1.graph) |
Writing models
Reading resources is one part of the job, the other part is the ability serialize your modification or a new model into a Resource. This time, there is no need to register the metamodel first as every important information is directly read from the model by introspection. The following code shows how to serialize the new ‘g1’ model in its original resource ‘g1_resource’:
g1_resource.save() |
That’s it. As the model is already in the resource, if it hasn’t been removed from it, you can just save the resource and that’s all. You can also save the resource in a different file. To do so, you only need to add a parameter to save():
g1_resource.save(output=URI('./new_g1.xmi')) |
Now, if you want to serialize a brand new model you have created in a file, the process is in three steps. First, you create a new Resource, then you add your model root to the Resource and finally, you save it. If we assume that we have a brand new Graph ‘g2’, then its serialization takes place like this:
g2_resource = rset.create_resource(URI('./g2.xmi')) g2_resource.append(g2) g2_resource.save() |
Note that the model root is added using the ‘append()’ method on the Resource.
Remote Ecore and XMI Resources
As you have seen, it is fairly easy to read and write into a Resource. There is also a small, but nice addition in PyEcore which enables you to read a .xmi/.ecore from a remote location. During the reading process, instead of using a URI, which is used for files and ‘virtual’ URI, you can also use an HttpURI. For example, the following piece of code shows you how to get the Graph metamodel directly from GenMyModel, how to read it, create some elements and serialize the result:
import pyecore.ecore as Ecore from pyecore.resources import ResourceSet, URI from pyecore.resources.resource import HttpURI rset = ResourceSet() rset.metamodel_registry[Ecore.nsURI] = Ecore url = 'https://api.genmymodel.com/projects/_L0eC8P1oEeW9zv77lynsJg/xmi' resource = rset.get_resource(HttpURI(url)) mm_root = resource.contents[0] Graph = mm_root.getEClassifier('Graph') Node = mm_root.getEClassifier('Node') g = Graph() g.name = 'my_graph' n1 = Node() n1.name = 'n1' n2 = Node() n2.name = 'n2' g.graph.extend([n1, n2]) resource = rset.create_resource(URI('./mygraph.xmi')) resource.append(g) resource.save() |
Besides the usage of the HttpURI, this little demo shows a full picture on how to read/modify/write Resources using PyEcore.
Performance
We report on some performance measures regarding the loading of XMI resources in the context of dynamic/static metamodels. Times were observed on a strong configuration (intel i7, 16Go ram).
With pure dynamic metamodels:
- Loading of PyEcore + Ecore.ecore + lib definition + UML.ecore loading: 1.8s
- Loading of PyEcore + metamodel from remote URL + XMI > 56.000 objects: 5.7s
- Loading of PyEcore + metamodel from remote URL + XMI > 64.000 objects: 6.7s
- Loading of PyEcore + metamodel from remote URL + XMI > 3300 objects: 0.9s
With a static metamodel:
- Loading of PyEcore + generated metamodel + XMI > 56.000 objects: 5.4s
- Loading of PyEcore + generated metamodel + XMI > 64.000 objects: 6.3s
- Loading of PyEcore + generated metamodel + XMI > 3300 objects: 0.5s
There is no big difference between the static and dynamic version of the metamodels. The time for loading the PyEcore library, the generated/remote metamodel and the XMI is almost the same. This explained by the fact that PyEcore deals with static and dynamic metamodels almost in the same way. The dynamicity and flexibility aimed by PyEcore have its cost.
Let’s be honest, at the moment, performances are not perfect, the EMF Java version is probably way faster. Python is not the issue here, I’m convinced that, with the proper improvements in PyEcore code, performances can be enhanced.
Model Transformations in PyEcore
The fact to be able to handle metamodels and models in Python calls for some experimentation on model to model and model to text transformations using PyEcore and pure Python.
Write model transformations in Python thanks to PyEcore Click To TweetModel to model transformations
A quick experiment on model to model transformation can be found here: https://github.com/aranega/pyecore/blob/master/experimental/m2m/m2mlib.py and an application example here: https://github.com/aranega/pyecore/blob/master/experimental/m2m/transfo.py. Please note that this is still a POC. The idea is to be as close as possible to a small subset of the QVT semantic by keeping this binding:
- QVTo mapping + when clauses -> Python function,
- QVTo disjunct -> Python function (also).
To change slightly the way the Python method will execute, we will use Python function decorators:
- a function decorated with “@mapping” will represent a method mapping,
- a function decorated with “@when” will take a lambda that returns a boolean and will represent a when clause on a mapping,
- a function decorated with “@disjunct” will take mapping functions and will try to execute each mapping in the declared order until one return a non-None result.
We also will use a quite new Python feature, type hints. From Python >= 3.5, it is possible to express the type of function parameter and the return type. These types hints are not evaluated at runtime, but using reflection, we can access them. We will use this to express the input element type and the output element type. From the expressed output element type, we also will automatically create a “result” variable with this type and “inject” it in the function.
As a result, here is how a simple mapping from a Graph to a new Graph instance will be expressed:
@mapping def graph_mapping(self : graph.Graph) -> graph.Graph: result.name = self.name for n in self.graph: result.graph.append(node_mapping(n)) |
And here is how two mapping from Node to new Node instance could be expressed (using also a disjunct):
@when(lambda self: self.name.startswith('start_')) @mapping def startnode_mapping(self : graph.Node) -> graph.Node: result.name = self.name[6:] + '_oldstart' @mapping def basicnode_mapping(self : graph.Node) -> graph.Node: result.name = self.name @disjunct(startnode_mapping, basicnode_mapping) def node_mapping(self: graph.Node) -> graph.Node: pass |
Obviously, this is only a way of experiment with Python and see what could be possible if we mix basic Python features with modeling. On this small example, we can see that the expressiveness of Python allows us to do a lot. Using the same idea and with minor modifications, it could be possible to implement the equivalent of QVTo helpers, refine the @when decorator, add a fine-grained traceability system…
Model to Text Transformation
Plenty of template engine exists for Python and could be used to deal with model to text transformation. However, in order to use full Python without any templating library, an idea could be to use literal string interpolation (f-string), one of the new Python 3.6 feature. A small and ineffective implementation of a model to text transformation could look like this using f-string (still on the Graph metamodel) to produce Graphviz dot format:
def iterate(generator, separator='\n'): return separator.join(generator) def generate_graph(g: Graph): value = f"""digraph {g.name} {{ {iterate(generate_node(x) for x in g.graph if not x.relatives)} }} """ return value def node_entry(node: Node): return lambda n2: f'{node.name} -> {n2.name}' def generate_node(node: Node): value = (f' {iterate(map(node_entry(node), node.references))}') return value print(generate_graph(g)) |
Beside “iterate” each function defines how the model will be rendered and elements. This little example illustrates how new features of Python could be part of a more complex engine which would render text from a model. This script applied to the graph instance given at the start of this article would print the following code:
digraph my_graph { a -> b } |
Obviously, many improvements could be added to this basic script.
Limitations and Futures Additions
Currently, there are some limitations in the implementation that you need to be aware of:
- models can only have a single root,
- cross-document references cannot be circular (no proxies),
- “del element” statement will not work as intended,
- EClass needs a name during creation,
- derived property management in dynamic metamodels need more work,
- there is currently no check on EOperations signatures during an EOperation behavior assignment.
Some of these limitations will be tackled by the future addition in PyEcore and, obviously, each of these limitations will be addressed in a future version. Here is what’s in the roadmap so far:
- EMF proxy
- object deletion
- EMF command system
- method body in .ecore
As PoC I also started playing with an OCL to Python transpiler here: aranega/pyecoreocl: OCL to Python compiler
It tackles only OCL expressions right now (and can also manipulate Python’s libraries). The point was to reduce the distance between OCL constraints in your UML model and their implementations. The transpiler can also execute the generated Python expression at run time.
Summary
This article presents PyEcore, a Python implementation of EMF. PyEcore focuses mainly on flexibility in order to provide a way of scripting models/metamodels and tries to be as much as possible compatible with EMF-Java/Ecore through the XMI import/export and basic objects naming.
PyEcore also shows how Python proposes many mechanisms that can be very interesting for model/metamodel manipulation and gives the ability to use libraries from the rich Python ecosystem.
It also opens new opportunities to build new tools and uses EMF on various platforms. PyEcore is still actively maintained and contributions are welcomed: https://github.com/aranega/pyecore.
Music, cards and beer lover…
Also PhD in Computer Science specialized in software modeling, code generation and model driven development. R&D Project Manager at GenMyModel, interest/work in code generation, reverse engineering techniques, interpretation and compilation.


Hi,
Is PyEcore able to generate the python code when the metamodel is split in a hierarchy of several ecore files?
Regards
Laurent
Hi Laurent,
At the moment, PyEcore can only generates python code for a metamodel defined in a single file. PyEcore uses the ‘.ecore’ to generate the python code while EMF uses the ‘.genmodel’ file that references all the ‘.ecore’ involved in the metamodel definition, so PyEcore gain way less information than the EMF version.
I’m working on a better handling of inter-file references (I’ve got promising results) that will give a better flexibility and enable PyEcore to easily navigate through ‘.ecore’ hierarchie. I don’t know yet if I will use ‘.genmodel’ or another way.
In the meantime, PyEcore supports inner EPackages. I know that this is strongly recommended to not use them, but this could be a solution (you can check PyGeppetto which uses PyEcore with inner EPackages: https://github.com/openworm/pygeppetto).
Hi Laurent,
Almost 5 months and many new features later, PyEcore is now able to generate the Python code for a metamodel split in a hierarchy of serveral ecore files, using “pyecoregen” and the “–with-dependencies” option. When the option is used, the generator takes the “master” ecore file as input and automatically find/generate all the required metamodel code recursively.
Hi,
Is this possible with PyEcore to express State Machines or Activity diagrams ?
I would like to generate or import XMI for such diagrams and I am looking for a tool that allows to specify those diagrams and export and import them. For the moment, for specification I use plantUML however it lacks the support to produce XMI for State Machines or Activity diagrams.
Hi Manuel,
Actually, it really depends what you have in mind. With PyEcore, you can load the UML metamodel and programmatically create Activity and State Machine models in Python that conforms to the UML metamodel. Currently, there is no dedicated syntax to create them, meaning that you need to know the UML metamodel and Python to create the models. So, there is no already out-of-the-box solution, but you can create yours.
A solution could be to define an internal DSL in Python which creates the PyEcore UML instances, then wite the created model in an XMI (still using PyEcore). Another one could be to create your own grammar to express these kind of elements that creates the underlying elements using PyEcore, and dump the result in an XMI. There is plenty of solution to generate a parser in Python for your own grammar, I’m working on an integration of PyEcore with textX (https://github.com/aranega/textX) which is still experimental, but which could help you in this task. Otherwise, you could directly use textX (https://github.com/igordejanovic/textX) which is already awesome in itself, creates your grammar and each time a file is parsed, go accross the structure created by the parser in memory, creates the corresponding PyEcore UML instances and serialize the model in an XMI file. However, all these solutions require some coding.
Thanks for the great article, Vincent!
The link you listed for magic methods (from the dive into python book) doesn’t work anymore. I suggest updating the text to use this new location of the book: https://www.diveinto.org/python3/special-method-names.html
Also, for visual learners, it might be easier to learn Python through an online course. Here are some courses, both free and paid, from several providers: https://classpert.com/python-programming.
Hi Vincent – what is the best way to visualize models generated in PyEcore currently?
The audiences I have in mind are semi-technical/non-technical and won’t read python, yet would benefit from an overview of relationships in the data.
Thank you
Hi Bob, have you taken a look at these set of UML tools for Python? https://modeling-languages.com/uml-tools/#UML_tools_for_Python
Hi Jordi,
Thank you. I played with pynsource a little. It seems to do a nice job for taking classes statically defined in a .py file and generating a UML diagram for the classes.
My use case is slightly different. By contrast, I have tables of data representing node attributes and edges between the nodes. I’d like to be able to generate a UML representation of the node-edge-node relationships, showing all the node attributes (and ideally edge attributes) – basically a nice representation of a DAG.
I tried creating python classes dynamically from the data – but pynsource doesn’t recognise the dynamic classes (it can only inspect a static script).
A potential solution would be to write a .py script generator in python, run it on the data, write the .py script programmatically, and then read that into pynsource.
Hoping that there is something out there already.
The swampy application in the tools link above looks like it can interpret runtime class relationships, but the UI output isn’t great to look at, so I haven’t tried it.
Hmm – perhaps (node, edge) data -> PyEcore to generate .ecore file, then pyecoregen to generate the static python file with classes from the ecore model, then pynsource to visualise it. Let’s see…
Hi,
I try to run these examples on my machine but I get this error:
AttributeError: ‘Graph’ object has no attribute ‘graph’
Hi,
please how can i solve this problem:
from .graph import getEClassifier, eClassifiers
from .graph import name, nsURI, nsPrefix, eClass
from .graph import Node, Graph, NamedElement
from . import graph
ImportError: attempted relative import with no known parent package
Hi, thanks for the examples.
I have developed a metamodel and, after performing the transformation using ATL, I want to proceed with converting the obtained XMI to RDF using Python. I have the metamodel definition and the XMI instance. However, when I try to generate the code or read the XMI in any way, I encounter this error, and I cannot find any reference to understand what might be happening.
File “/…/.local/lib/python3.10/site-packages/pyecore/ecore.py”, line 1089, in __getattribute__
self._wrapped = decoded.eClass
AttributeError: ‘NoneType’ object has no attribute ‘eClass’
The code for loading metamodel and instance:
# Load the source metamodel
rset = ResourceSet()
rset.metamodel_registry[xmltype.nsURI] = xmltype
resource = rset.get_resource(URI(‘/metamodel.ecore’))
mm_root = resource.contents[0]
#Load xmi instance
rset.metamodel_registry[mm_root.nsURI] = mm_root
resource = rset.get_resource(URI(‘/xmi.xmi’))
model_root = resource.contents[0]
Hi Reynaldo,
Sorry for the late answer. The error you’re experiencing can come from various sources depending on the shape of your metamodel and your data. Here, it looks like the error you are experiencing comes from a proxy having issues decoding one of the relationship. Are you sure all the models you need to load are actually well loaded? If you still are experiencing the issue, feel free to contact me with my email address and to send me your model and metamodel so I can assist you in finding the issue 🙂