
A reader sent me the following Eclipse model that was clearly as not well-formed: a class was the subtype of an interface!
This left me wondering how he had managed to draw such an incorrect model. Weren’t the Eclipse UML tools unable TO prevent this obvious mistake? The short answer IS NO (long answer below). I’ve tried three different modeling tools based on the Eclipse UML2 implementation and all allowed me to draw the following class diagram:
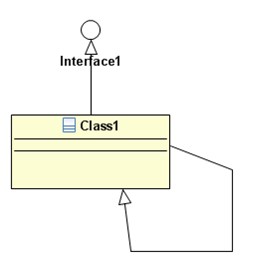
At that point I decided to contact Javier Muñoz from the MOSkitt Eclipse-based modeling platform to know what was going on. He told me that the UML2 metamodel implementation in Eclipse offers on demand validation of some well-formedness rules . Even if we ignore for a moment that not all validation rules defined in the UML standard are implemented, this means that an Eclipse-based UML modeling tool could:
- Never call the available validations operations (no guarantee that the model is ever correct)
- Call them only when the user explicitly asks for it (correctness is only evaluated at a certain points of time; it is up to the user to interpret the validation feedback and modify the model accordingly)
- Implement some kind of notification service to call them after every model change made by the user (correctness is instantly evaluated but it is up to the user to correct the mistakes of his/her last actions)
- Prevent the errors by calling the validation operations before recording the user action in the model (i.e. “rolling back” the user action if this action evolves the model to an incorrect state).
Unfortunately, I’ve FOUND several “instances” OF the FIRST GROUP AND AT least one OF the SECOND one but I’m not sure if we can find tools belonging to the third or fourth groups (do you know any?), the only ones that seem acceptable to me (specially the fourth). The other options are too risky.
Maybe I’m a little BIT too picky here but I don’t see the point on building fancy tools for all kinds of advanced modeling languages and techniques if we cannot even provide the functionality required to prevent users from doing basic mistakes.
Note that these basic mistakes I’m referring TO correspond TO the well-formedness rules defined IN the standard. There IS a distinction BETWEEN these basic rules AND other quality problems we can find IN models AND that may be acceptable depending ON the purpose OF the model OR the phase IN the development process IN which the model IS used (e.g. IN the early stages OF the process, models ARE usually incomplete AND can have inconsistencies BETWEEN the different “diagrams”, AS operations IN a sequence diagram that ARE NOT yet defined IN the CORRESPONDING classes OF the class diagram; this IS part OF the model refinement process). TO me, a class that subtypes itself IS always wrong, under NO circumstances this should be allowed.
I don’t believe a continuous validation can cause efficiency problems either. Checking these basic rules is not exactly rocket science and can be efficiently implemented (and many techniques, like the ones I developed in my thesis , could be used to determine the minimal model subset that needs to be reevaluated after every user update to improve efficiency when dealing with very large models).
Maybe, for once, Eclipse tools should learn from ArgoUML that has already been offering this functionality (group 4 from the list above!!) for many years
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


The majority OF users OF UML do NOT use it AS a modeling LANGUAGE FOR MDD OR code generation, but just FOR communication/documentation. FOR that use CASE, well-formedness IS very low ON the list (if AT ALL) OF important features.
Cheers,
Rafael
if we need to communicate let’s try TO communicate well!
MagicDraw, which IS NOT based ON Eclipse UML2, does a lot OF the validations you ARE asking FOR. IN fact, it does NOT allow either OF the generalizations IN your test diagram — so, in this respect, it is in “group four”.
However, it also provides a nice capability for incremental validation in a number of other areas, highlighting parts of the model that become invalid and even providing options for both manual and automatic fix up. So, in this respect, it is also in group three. (Some of the validations and fixes it provides go well beyond just simple well-formedness constraints — its capabilities for keeping the arguments of a call action in sync with changes to the formal parameters of the called behavior is particularly useful.)
— Ed
However, as model execution becomes more and more a reality, and more and more desirable, it becomes more and more important that the models are well-formed. In particular, the formal Foundational UML execution semantics only apply to models that are well formed.
One of the main reasons I got involved in the OMG Model Interchange Working Group was not just to see if drawing tools could interchange models between themselves, but also to see if models could be interchanged between drawing tools and execution engines. And, when we did two tests of interchanging activity diagrams, I attempted to execute the exports from all the tested tools. This definitely pointed up any cases when the exported models had not been constructed completely correctly!
— Ed
For sure, model execution is exactly my interest in UML.
But many UML tools out there will let you create class diagrams where types of attributes are missing, and that is exactly what most people seem to expect, as it is convenient.
The TextUML Toolkit in the beginning required type information for all typed elements, but later I decided due to “popular demand” to allow “any” to be specified, which is basically to allow omission of type information.
Rafael
TRUE, but we usually don’t use tools to constrain our communication.
Poor analogy, but imagine an email client that didn’t allow you TO send a message until you corrected ALL spelling AND grammar errors?
Rafael
AS TO your specific example, attributes without types ARE actually well-formed. The TYPE ON a typed element IN UML IS, IN fact, optional! Untyped elements do NOT have their VALUES constrained — that is, they have the effective semantics of having type “any”. Just leaving off the type is the standard way to specify that in UML.
That said, often people leave the types off attributes because either the they don’t know the exact type yet, or they don’t care, or the type is obvious to human eyes from the name of the attribute. Even if doing this was ill-formed, it still would be useful for informal modeling — as are other cases. But if and when you get to the point at which you want to execute the model, then you are no longer modeling informally, and ill-formed (or inexact) models become a real problem.
So, in may cases, I would like tools to be in Jordi’s “group three”: let me know what the problems are, and let me decided whether or not to fix them. On the other hand, some things really just don’t make sense at all in UML, and tools should not allow such things. Jordi’s ill-formed generalization examples are in this category — his sample diagram just has no meaning in UML, even informally. It is better not to allow people to even draw things like this, rather than encourage them to try to give meaning to meaningless models.
— Ed
Continuing the analoyg, to me, the email client should not allow me to send the email if there are so many errors (or there only a few but very big ones) that the reader won’t be able TO understand the email content.
If the model cannot be understood because it IS NOT well-formed THEN we lose the communication power OF the model. OF course, we should FIRST decide what errors ARE so grave that should be always prevented AND which ones can be tolerated depending ON the planned USAGE FOR the model.
Good point. Incomplete != ill-formed. But FROM a point OF VIEW OF executability, AS you point out, they BOTH can be equally deterrent.
BTW, if it isn’t clear, I totally agree modeling tools should validate as much as possible – I was just trying to make a point on why tools can get away without implementing proper validation – because most people don’t care!
For a significant NUMBER OF users/uses, UML modeling tools ARE just glorified drawing tools. I believe most people ARE NOT modeling, they ARE sketching/documenting. Usability, good looking diagrams, integration WITH word processors, graphic formats supported etc ARE high VALUE areas IN that context AND AS such END up getting MORE attention AND making model validation less important.
Rafael
Design brainstorming, modeling to approximate complete/partial behaviour of a system, and graphical programming are routinely treated as equivalent by people who really should know better.
I don’t expect OR want validation FROM the blackboard around which my team AND I ARE standing while fleshing out an idea. But I certainly expect it FROM my compiler. Many modeling tools advertise themselves AS capable OF ALL three roles, AND if users ARE themselves NOT certain which OF these three activities they ARE performing, OF course the behaviour OF the modeler IS going TO surprise them further.
I have just checked the example given at the top of this paper.
I’ve drawn the diagram WITH Papyrus, THEN checked it WITH UML Model Editor : RIGHT-click ON the *.uml files produced by Papyrus, choose Open With, THEN either UML Model Editor OR Simple Reflective Ecore Model Editor. IN the tree-VIEW OF the model editor, RIGHT-click the topmost node, choose Validate, THEN you will GET an error message.
This works ALL fine. May be one could object the validation should be done FROM the Papyrus diagram editor. OK, this would be good, but if you really want TO validate, this just needs three mouse-click : one TO save the digram (that save the *.uml file IN the while), one TO OPEN the *.uml file IN one OF the two common UML editor, AND one TO run the Validate command.
Yannick Duchêne (Hibou57)
IN my VIEW, there ARE several ways TO integrate a validation mechanism IN a tool (see options 1 TO 4 IN the post) AND what you DESCRIBE here would correspond TO OPTION 2.
I´m NOT saying that it´s NOT possible TO validate a model, my point IN the post IS that I´d prefer tools TO implement OPTION 3 OR 4. IN my opinion it´s NOT safe TO let designers TO choose whether they want TO validate OR NOT the model FOR SOME kinds OF well-formedness rules.
Yes, I agree, 90% of editors does not provide any validation at all (ex. some people like say Dia is good at UML). Actually there are two UML diagram editors (well, model editor, as the diagram is just a view on the model), with support for option 4 : ArgUML (already mentioned) and TopCased.
But even these may be questionable, as I get validation errors on model created with both. Something dealing with a visibility which can only be either public or private (I checked in UML Superstructure it is indeed required).
May be a reason why this is not easy to require this feature, is there are other matters : does it save and import XMI ? Does it save and import UML-DI ? As an example, ArgoUML is validating (with the provision given above), but does not know about UML-DI. TopCased is validating, but seems to have many troubles with import of XMI (and also have many pointer error at runtime. Papyrus do save XMI and UML-DI (while does import as well as expected), but is not validating.
You can always have this-and-that but not all. I would the first requirement is Validation+XMI (save and import) and then UML-DI. Validation comes at a first place (useless to draw a diagram which means nothing).
[…] level of quality. Of course, some do a better job than others (check our previous discussion on the poor validation of UML models in some Eclipse tools ) but still it’s much better than […]
Late to the discussion, but maybe more relevant now it’s FOSS, BridgePoint provides level 4.