

It is undeniable the high cognitive load that modelers face to understand a multitude of complex abstractions and their relationships, and the urgent need to support tool builders to provide modelers with intelligent modeling assistance.
New opportunities have been explored in the field of recommenders in IDEs for specific programming languages or platforms, e.g., for code completion [1, 2], for using external libraries [3], contributing to new projects [4], or solving standard programming tasks [5]. However, current Intelligent Modeling Assistants (IMAs) lack adaptability and flexibility for tool builders, and do not facilitate understanding the differences and commonalities of IMAs for modelers. Such a patchwork of limited IMAs is a lost opportunity to provide modelers with better support for the creative and rigorous aspects of software engineering. In this blog post, we introduce our recently published paper [6], in which we present a conceptual reference framework to identify the foundations for intelligent modeling assistance.
This framework serves a twofold purpose. It is expected to:
- help tool builders when engineering future assistants, which will
- eventually provide more intelligence and situational awareness about modeling activities to various stakeholders involved in modeling activities.
We envision a momentum in the modeling community that leads to the implementation of this Reference Framework for Intelligent Modeling Assistance (RF-IMA) and consequently future IMAs. We also identify open challenges that need to be addressed to realize the opportunities provided by intelligent modeling assistance.
Contents
Reference Framework for Intelligent Modeling Assistance (RF-IMA)
Our conceptual reference framework is illustrated in Fig. 1. Here, we present its components
and their interactions and describe how such a framework would help comprehend, develop, and ultimately compare IMAs.
RF-IMA composed by 5 main components: (1) the Socio-Technical Modeling System (STMS) that provides context, (2) an IMA, (3) the connecting communication between both, (4) external sources of data, information, knowledge, and experts, and (5) crosscutting quality properties.
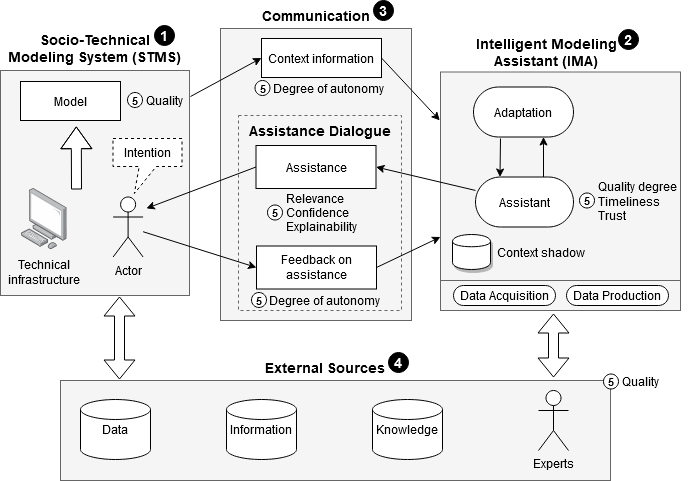
Fig 1. Conceptual Reference Framework for Intelligent Modeling Assistance (RF-IMA)
STSM
The context in an STMS consists of a modeler realizing a modeling activity in a modeling environment. It is hence composed of three parts (top left of Fig. 1): (i) the actor that can be a modeler, a team, or another software; (ii) the technical infrastructure, such as a computer and its software, including one or more modeling tools; and (iii) the models of interest. The actor has intention which defines what the actor wants to accomplish and why. Intention may be expressed explicitly or implicitly (as indicated by the dashed outline).
IMA
An IMA consists of four components (top right of Fig. 1): (i) the assistant with algorithms to compute the assistance (e.g., contextualized information, recommendations); (ii) the data acquisition/production layer that gives access to different external sources (data, information, knowledge) and has the ability to connect a modeler with domain experts; (iii) the context shadow, which contains information about the context that captures the intention of the modeling activity, any relevant information for the activity or specific to the current situation, personalized information about the actor like an internal representation of a modeler (e.g., a digital twin), and retains the local historical data related to the modeling activity, and (iv) an optional adaptation component which adapts to changing context based on the feedback by the actor (e.g., by assessing the modeler’s skill level from provided feedback).
Communication
In general, there might be a federation of IMAs that process a context with various information and each actor may interact with multiple IMAs. Individual IMAs may interact with each other, e.g., to collaborate and coordinate changes across actors. The communication between STMS and IMA (top middle of Fig. 1) is bidirectional and characterized by different degrees of autonomy. STMS to IMA communication is used to deliver context information and actor feedback. IMA to STMS communication feeds the assistance to the actor in a way that is specific to the modeling activity. In turn, this communication may affect all parts of the context (not only the intention and the specific actor, but others as well, as context may be shared among actors). IMA to STMS communication may also provide an explanation about the choice of the assistance.
External sources
An IMA may use a variety of external sources (bottom of Fig. 1), which may be categorized into data, information, and knowledge according to the data, information, knowledge, and wisdom pyramid. These external sources may be used for specific recommendations. For example, technical project information may lead to feedback regarding modeling patterns, information about the technical infrastructure to feedback on energy models, and development process information to improved resource usage models. Furthermore, information from social networks and technical background from résumés may lead to feedback on which modeling expert to contact, business information to improved development processes, information from the execution of a system or simulation to more accurate metrics about model elements, and information about the environment to cheaper locations to run computationally intensive model analyses. Information about laws and regulations may lead to warnings of possible certification issues, scientific information to suggestions on novel modeling solutions, and information about stakeholders and culture to feedback on the real values and intentions of stakeholders. Last but not least, metadata about an IMA itself and interactive feedback from actors may improve an IMA’s performance over time.
Quality Properties
Quality properties are highlighted across all four main components of the reference framework.
First for IMAs, the assistant’s quality degree and timeliness (how often is adequate assistance provided in a timely manner?) as well as the trust of modelers (as in the perception of the quality of IMAs from the modeler’s perspective) are issues. At a high level, one of the factors that has a big impact on the quality degree relates to the level of sophistication required from IMAs (e.g., syntactic auto-completion vs design trade-off analysis).
Second for Assistance, the relevance of and confidence in the provided information are important (how adequate is it for the current modeling context and how sure is the IMA that it is adequate?). Furthermore, explainability is important, characterized as the degree to which an actor understands why a particular assistance is provided to her. Without adequate assistance at a high confidence level, the usefulness of an IMA suffers. However, even with high relevance and high confidence, an IMA’s help may be of limited use, if it is not possible to explain why the provided help is relevant.
Third for Feedback on assistance and fourth for Context information, the degree of autonomy needs to be considered (e.g., existing levels of autonomy, such as offering no assistance and the modeler making all decisions, suggesting an action and executing that action if approved by the modeler, automatic execution of improvements, to an IMA acting fully autonomously).
Last but not least, the quality of the model is also an issue in terms of well-formedness, absence of anti-patterns, etc. as is the quality of the modeling activity (i.e., process-related quality indicators). Similarly, the quality of external sources also must be considered (e.g., transparency, accessibility, data curation concerns).
Open Challenges
Beyond the identification of the core foundations and main components for IMAs, we have also identified the following open challenges.
STMS
For STMS, understanding the modeling context (incl. the actor and its intention) is of utmost importance. Hence, context monitoring of the modeler (e.g., to predict the actor’s intentions) requires non-invasive, privacy-preserving methods. Mining of modeling intention may be needed instead of relying on explicit expressions of modeling objectives, and quality criteria for modeling activities and artefacts need to be established considering the domain of interest. For instance, interpreting actor’s activities and predicting intentions correctly may require to build a model, to determine which variables influence each other, to learn about model’s parameters, and to complete the model in case of missing data (e.g., an actor’s preferences).
IMA
For an IMA, learning opportunities exist to provide the most relevant assistance, such as (i) understanding behavior and skill of modelers, as well as understanding the specific modeling need for assistance or (ii) transfer learning between domain-specific modeling languages. There is also a need to determine the most appropriate algorithms to learn from existing data and infer relevant new knowledge in the context of a given model or modeling activity. In addition, there are questions on how to analyze the impact for recommended model changes for both short-term and long-term effects, on how to adapt to the evolving needs of the modeler, and on how to select, filter, structure, and manage relevant context information in the context shadow.
Communication
For communication, there is a need to study user interactions (among the very heterogeneous stakeholders and modeling activities) and user experience for assistance in terms of (i) degrees of automation, (ii) the emotional state of the modeler as well as her positive and negative modeling experiences, (iii) content and form of presenting assistance, and (iv) dialog structure with the modeler to facilitate explainability.
External sources
For external sources, one crucial challenge is related to the availability of required repositories for models and their metamodels. What is the corresponding modeling knowledge for an IMA that needs to be made explicit to support modeler’s decision-making, comprehension, etc.? How does the modeling knowledge base evolve and how is it maintained, and at what granularity of classifications (by domain, ontologically, etc.)? Which data schemas are required to manage modeling artifacts? Another challenge involves the mining of modeling knowledge and professional information of modelers to determine best practices and identify domain experts.
Global perspective
From a global perspective, a key challenge is to identify modeling activities where intelligent assistance is relevant, together with required models and data. An immediate concern for the modeling community is how to determine the, possibly evolving, requirements for an IMA to provide timely assistance based on confidence and relevance as well as modeler’s skill and trust.
To identify such requirements, further work is needed to support comparison of IMAs based on more fine-grained properties of RF-IMA (e.g., through an assessment grid). As with any other reference framework, RF-IMA helps define the boundaries between components.4
An overarching challenge is now to define appropriate, generic, domain-independent modeling interfaces and protocols (e.g., similar to the language server protocol for programming languages), allowing seamless integration of various IMAs and modeling environments. Such interfaces between STMS and IMA (in both directions) and protocols for communication have to (i) provide understanding of context as well as the feedback on the offered assistance and (ii) convey available knowledge from external sources that is useful for an IMA. The grand challenge is to make functionality for modeling assistance reusable across a wide range of domains.
References
[1] Bruch, M., Monperrus, M., Mezini, M.: Learning from examples to improve code completion systems. In: Prof. of the 7th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT International Symposium on Foundations of Software Engineering, pp. 213-222 (2009). DOI: https://doi.org/10.1145/1595696.1595728
[2] Svyatkovskiy, A., Zhao, Y., Fu, S., Sundaresan, N.: Pythia: AI-assisted code completion system. In: Proc. of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, p. 2727-2735 (2019). DOI: https://doi.org/10.1145/3292500.3330699
[3] Thummalapenta, S., Xie, T.: Parseweb: A programmer assistant for reusing open source code on the web. In: Proc. of the 22nd IEEE/ACM International Conference on Automated Software Engineering, p. 204-213 (2007). DOI: https://doi.org/10.1145/1321631.1321663
[4] Liu, C., Yang, D., Zhang, X., Ray, B., Rahman, M.M.: Recommending github projects for developer onboarding. IEEE Access 6, 52,082-52,094 (2018). DOI: https://doi.org/10.1109/ACCESS.2018.2869207
[5] Silva, R., Roy, C., Rahman, M., Schneider, K., Paixao, K., Maia, M.: Recommending comprehensive solutions for programming tasks by mining crowd knowledge. In: Proc. of the 27th International Conference on Program Comprehension, pp. 358-368 (2019)
[6] Mussbacher, G., Combemale, B., Kienzle, J., Abrahão, S., Ali, H., Bencomo, N., Búr, M., Burgueño, L., Engels, G., Jeanjean, P., Jézéquel, J.M., Kühn, T., Mosser, S., Sahraoui, H., Syriani, E., Varró, D.; Weyssow, M. Opportunities in Intelligent Modeling Assistance. Software and Systems and Modeling (2020). DOI: https://doi.org/10.1007/s10270-020-00814-5.
Lola Burgueño is an Associate Professor at the University of Malaga (UMA), Spain. She is a member of the Atenea Research Group and part of the Institute of Technology and Software Engineering (ITIS). Her research interests focus mainly on the fields of Software Engineering (SE) and of Model-Driven Software Engineering (MDE). She has made contributions to the application of artificial intelligence techniques to improve software development processes and tools; uncertainty management during the software design phase; model-based software testing, and the design of algorithms and tools for improving the performance of model transformations, among others.


Recent Comments