

(leer la versión en español)
UPDATE – This project proposal has been accepted for funding. If you would be interested to be involved in the project in any way please get in touch.) In one sentence: the goal of the project is to make the promise of open data a reality by giving non-technical users tools they can use to find and compose the information they need.
More and more data is becoming available online every day coming from both the public sector and private sources. As an example, the European data portal registers over 400,000 public datasets online.
Most of this data is available via some kind of (semi)structured format (XML, RDF, JSON,…) which, in theory, facilitates its consumption and combination. Indeed, the open data movement promises to bring to the fingertips of every citizen all the data they need, whether it is for planning their next trip or for government oversight.
Unfortunately, this is still far from reality. Our society is opening its data but not building the technology and infrastructure required to enable citizens to access and manipulate it. Only technical people have the skills to consume the heterogeneous data sources while the rest is forced to depend on third-party applications or companies.
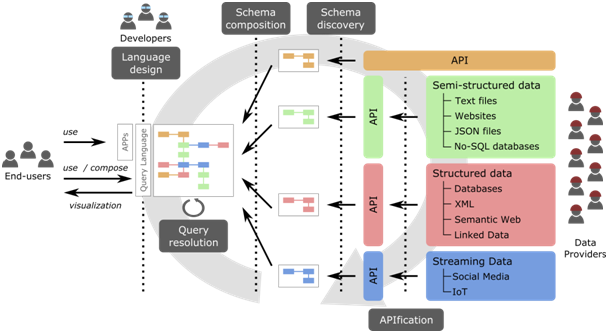
This research project aims to change this. Our goal is to empower all citizens to exploit and benefit from the open data, helping them to become not only consumers but also creators of data that add new value to our society. In this sense, the project will automatically infer a unified global schema of the knowledge available in open data sets and present that schema to the average citizen in a way she can easily browse and query to get the information she needs. This request will be then transparently translated into a combined sequence of accesses to the required data sources to retrieve, visualize and republish it (if desired). When several data sources could be used (e.g. due to an overlap in the exposed data) quality aspects of the source or even monetary costs (some sources may be only partially free) will be taken into account to provide an optimal solution.
To achieve this ambitious goal, the project will pursue the following key research contributions:
- APIfication of data sources: (Web) APIs are becoming the de facto choice for publishing content online. We will unify access to all kinds of data sources via an API interface
- Schema discovery: Most sources won’t have any kind of formal description we could use to precisely understand what information the source provides. A systematic analysis of data samples will help us to infer that schema (e.g. using a tool like JSON Discoverer), enriched with annotations regarding quality aspects (e.g. reliability, availability, etc) to better characterize the data source.
- Schema composition: Individual schemas will be matched and merged to create the global schema representing all available knowledge.
- Citizen languages: Human-computer interaction techniques will be used to build a user-friendly language to express and visualize information requests on this global schema.
- Query resolution: Each request will be translated into an optimal sequence of API calls on the underlying data sources to retrieve the data needed to respond to the request.
The results of this project will have a huge impact on our society by finally giving all citizens unrestricted access to the massive amounts of open data available online. This will also be beneficial to data providers, that could reach a broader audience, and software companies that will now have a simpler way to build new applications exploiting the links among a diversity of datasets. These benefits will be validated by means of case studies on open data sets provided by the city of Barcelona and the governments of Catalonia and Canarias, implemented on top of an open source platform released by the project.
The following figure illustrates the proposed approach.
Spanish version / Versión en español
Desde el grupo de investigación SOM Research Lab, liderado por el Dr. Jordi Cabot Sagrera, tenemos interés en desarrollar un proyecto de investigación que lleva por título Open Data for All: an API-based infrastructure for collecting and disseminating online fecha sources.
Este proyecto tiene por objetivo desarrollar la tecnología necesaria para permitir a los ciudadanos acceder a la gran cantidad de datos disponibles actualmente en abierto.
En particular, se pretende construir un modelo global unificado del conocimiento disponible en abierto y presentarlo a los ciudadanos de manera que puedan navegar fácilmente y transparentemente por la información que sea de su interés. Técnicamente, las solicitudes de los usuarios se traducirán en una secuencia de accesos a las fuentes de datos necesarios (generalmente, a partir de APIs) para recuperar y combinar los datos y así poder generar el resultado esperado por el usuario. En caso de que se tengan que utilizar diversas fuentes de datos (por ejemplo, debido a un solapamiento de los datos) se tendrán en cuenta factores como la fiabilidad de los datos o incluso los costes monetarios (ya que algunas fuentes pueden ser sólo parcialmente libres) para proporcionar una solución óptima. Puede ver más detalles del proyecto en el resumen inglés al principio de este post.
Para cualquier duda pueden escribir directamente a jordi.cabot at icrea.cat .
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Hi Jordi, I really liked that your goal to build a global schema of the knowledge available to the average readers, although, that is going to be really hard to achieve. Honestly, my sincerest best wishes!
Thanks George. Let’s hope I have good news to share in a few months!
Looking forward to the next post about this, with the results!