
In the last few days, I’ve learned about a new model repository (in a broad sense, remember “Everything is a model”): MDEForge , attended a demo of the new functionalities in ReMODD and learnt about a Morse (older) model-aware repository. Remember that not so long ago I also launched a (modest) OCL-focused repository. And the number of UML models automatically mined from GitHub is also quickly growing. And to those, you need to add (semi)private repositories owned by many commercial tool vendors (e.g. GenMyUML for instance or the xtUML one) and more “domain-specific” ones like this one on Robotics. The Free Models initiative keeps (or should I say, “it used to keep”?) an index of all these initiatives (though there are still some more out there like oomodels).
So, plenty of research initiatives, each with their own interesting specificities (e.g. MDEforge aims at not only storing the models but executing them even suggesting possible transformations to the user, ReMODD allows you to upload images and pdfs representing models to avoid restricting submissions to specific formats, my OCL repository is a GitHub project to let users contribute without having to register or learn yet another interface) but one common problem. They are all mostly empty.
And this is not going to change in the near future wich such a fragmented market. And I don’t foresee them converging either (for a variety of reasons, ranging from personal to technical). This hampers a lot their appeal to other researchers. As of today, if I want to evaluate my modeling tool over a representative set of models I may need to interact with several repository interfaces (and a few of them do not have option to access all models so I’d need to manually donwload them one by one). Just to give an example, this is one of the biggest problem we have with EMFtoCSP : we can’t find good models to prove how good (or bad) EMFtoCSP behave with industrial models and, even less, get a set of models that could be used as the basis for comparing EMFtoCSP against similar verification tools.
IMHO, the only viable solution is to federate the different approaches in a virtual model repository that acts as a single entry point for any user that wants to browse/query (and maybe even contribute to) the repository. This would allow each individual repository to exist on their own while at the same time enable end-users to query all of them at the same time. Technically, I think it´s easier than it seems. It would be “just” a matter of defining a common API that, each individual repository interested in becoming part of the federation, should implement. The virtual repository would focus on giving a transparent access to all members of the federation, not try to replace them.
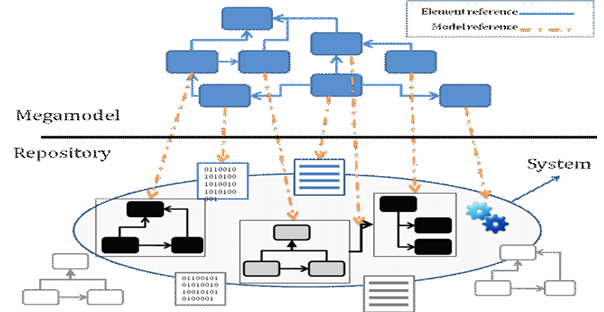
We did some experimentation on this topic some time ago while working on MoScript – a textual DSL for querying and manipulating model repositories. MoScript used a megamodel to abstract from the specificities of individual repositories and give the possibility to define abstract queries on them. For instance, with MoScript, you could use this query to retrieve all metamodels with less than 20 elements:
| 1
2 |
Metamodel::allInstances()
−>select(mm | mm.allContentInstancesOf(‘EClass’)->size() < 20) |
and this one to get all models of type Java and apply to each of them a predefined java2dNet transformation
|
1 2 3 4 5 6 7
|
let javaModels : Collection(Model) = Model::allInstances() −>select(m | m.conformsTo.kind = ‘Java’) in
let java2dNet : Transformation = Transformation::allInstances() −>any(t | t.identifier = ’java2dNet’) in javaModels->collect(jm | java2dNet.applyTo(Sequence{jm})) |
Hope to finally see some day (before I retire I mean) a useful model repository. This virtual federation is my pragmatic proposal to this open challenge. What’s yours?
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Since each repo is likely to use different metamodels, it seems you are proposing a standard meta-meta attributes.
I think that is feasible, *if* you limit things to very general characteristics. But since metamodels can be quite different, what would this set of common attributes look like? Even ‘number of elements’ (your example) can have a very different meaning between two metamodels (if they are quite different coarseness-wise).
In principle I think all of them accept models conforming to any possible metamodel. In practice, they either end up storing models of a fixed set of well-known metamodels (UML, BPMN,…) or they store metamodels and transformations but in this case not the instances of those metamodels. With this I mean that most times you don’t have two levels in the same repository which simplifies the queries (and their semantics)
Hi Jordi, thanks for raising again this important topic. Please find below what I was thinking while reading the thread so far.
On the one hand, I think that you do not need a global repository for the specific use case that you mention (i.e., finding good models/tools to benchmark against). I encourage you to look again at the various solution papers we have at http://www.transformation-tool-contest.eu/, and after checking those papers you go to the related VMs in http://share20.eu to find the needed model, metamodels, transformation definitions and supportive tools. There are many good things out there that are not yet used enough, in my perception… and I think going through the papers is worth the effort anyhow (you will see which metamodels have less than 20 classes but you will also learn about valuable context information).
On the other hand, I think it may be good to push all our models to broader repositories like http://gist.neo4j.org/. I don’t think it is technically that hard to store some modelmetamodel references there, as well as references from/to transformation models. I am not against maintaining also the current silos but I am unsure whether a virtual repository makes more sense than just replicating content also in repositories like http://gist.neo4j.org/ (syncing from time to time should not be a bottleneck, as far as I can see).
Best regards,
Pieter
Hi Pieter,
You do have some nice sets of models from the different TTC editions but, again, everybody has a few interesting examples in their repositories. My point is that I don´t want to explore them one by one instead I just want to be able to launch a query on all of them at the same time. How then this query is executed is another discussion. I think the API solution is easier than asking repository owners to dump their content also to a central repository (good luck with that! 🙂 ) but from a user point of view this is irrelevant as long as I can do what I want.
In general I agree with the idea of a generic entry point to model repositories. However, while we (the Free Models Initiative) were/are indexing existing repositories we identified another hurdle that might be relevant for your proposal: this is less the problem of different licenses associated to models in the different repositories, but more the fact that some repositories require users to have an account, e.g. intending a restriction of access, which should be given to researchers only, as in the BPMI.
Hi Jordi, I also do not want to stress the technical differences. In particular, you write ” It would be just a matter of defining a common API that, each individual repository interested in becoming part of the federation, should implement.” while I was thinking of sucking out models from the different repositories and store them uniformly elsewhere (e.g., in GIST). I agree that from a user point of view the difference is largely irrelevant. Then again, coming back to my first point, I think that for scientific use case that you mentioned (finding interesting models for benchmarks) the repository approach is probably overkill in the first place (although many people talk about it as a barrier, I see it largely as an excuse for not checking seriously what is out there). I think the repository approach (virtual or not) would be motivated better when thinking of non-scientific knowledge management use cases. For example, I have in mind use cases along the lines of reference models for clinical pathways (see http://link.springer.com/chapter/10.1007%2F978-3-642-39088-3_14#page-1 for more info).
Best, Pieter
We had some success with using SPARX Enterprise Architect, which can run on top of a relatively open (if poorly documented) SQL repository. Yes, SPARX is a proprietary commercial tool :-(, but still reasonably priced and well worth the $300 (or so) for anybody who needs to do serious modeling work.
Because I didn’t see any possible convergence either, my idea of real URIs for models wasn’t that stupid. Basically, doing for the MDE what have been done for the Web.(http://olegoaer.perso.univ-pau.fr/works/posterMODELWARDS_2017.pdf)