
Domain models capture the key concepts and relationships of a business domain, leaving out superfluous details. During the domain modeling activity carried out as part of a software development project, informal descriptions of a domain are translated into a structured and unambiguous representation using a concrete (formal) notation.
Despite the broad variety of languages (UML, DSLs, ER, etc.), tools and methods for domain modeling, these models are typically created by hand, making their definition a crucial (but also time-consuming) task in the development life-cycle. Given that the knowledge to be used as input to define such domain models is already (partially) captured in textual format (manuals, requirement documents, technical reports, transcripts of interviews, etc.) and provided by the different stakeholders in the project, we propose to move towards a more assisted domain modeling building process.
You don't need to model alone. Our modeling assistant uses NLP-based techniques to read any existing document (including Wikipedia!) and helps you with good autocompletion suggestions to create better models faster! Click To TweetTo facilitate the definition of domain models and improve their quality, we present an approach where a natural language processing-based (NLP-based) assistant will provide autocomplete suggestions for the partial model under construction based on the automatic analysis of the textual information available for the project (contextual knowledge) and/or its related business domain (general knowledge). The process will also take into account the feedback collected from the designer’s interaction with the assistant. This is a joint work by L. Burgueño, R. Clarisó, S. Gérard, S. Li and J. Cabot that will be part of the 33rd International Conference on Advanced Information Systems Engineering (CAiSE’21). Summary slides are also available at the end of the post.
Contents
Autocompletion of partial domain models
Our proposal aims to assist designers while they build their domain models. Given a partial domain model, our system is able to propose new model elements that seem relevant to the model-under-construction but are still missing. This is, it assists the software designer by generating potential new model elements to add to the partial model she is already authoring. We believe this is more realistic than trying to generate full models out of the requirements documents in a fully automated way.
We propose a configurable framework that follows an iterative approach to help in the modeling process. It uses Natural Language Processing (NLP) techniques for the creation of word embeddings from text documents together with additional NLP tools for the morphological analysis and lemmatization of words. With this NLP support, we have designed a model recommendation engine that queries the NLP models and historical data about previous suggestions accepted or rejected by the designer and builds and suggests potential new domain model elements to add to the ongoing working domain model. Our first experiments show the potential of this line of work.
Framework and Process
To provide meaningful suggestions, our framework relies on knowledge extracted out of textual documents. Two kinds of knowledge/sources are considered:
- general, which according to the Cambridge dictionary is “information on many different subjects that you collect gradually, from reading, television, etc., rather than detailed information on subjects that you have studied formally”, and
- contextual, which includes all the specific information collected about the project.
We do not require these documents to follow any specific template to exploit the information they contain.
General and contextual knowledge complement each other. The need for contextual knowledge is obvious and intuitive: designers appreciate suggestions coming from documents directly related to the project they are modeling. General knowledge is needed when there is no contextual knowledge or this is not enough to provide all meaningful suggestions (i.e., it may not cover all the aspects that have to be described in the domain model as some textual specifications omit aspects considered to be commonly understood by all parties). For instance, project documents may never explicitly state that users have a name since it is common sense and both concepts go hand-by-hand. Thus, general sources of knowledge fill the gaps in contextual knowledge and make this implicit knowledge explicit. Leveraging both types of knowledge to provide model autocomplete suggestions to the designer would significantly improve the quality and completeness of the specified domain models. As most common knowledge sources are available as some type of text documents (this is especially true for the contextual knowledge, embedded in the myriad of documents created during the initial discussions on the scope and features of any software project), we propose to use state-of-the-art NLP techniques to leverage this textual-based knowledge sources.
Methods such as GloVE, word2vec, BERT and GPT-3 create word embeddings (i.e., vectorial representations of words) that preserve certain semantic relationships among the words and about the context in which they usually appear. For instance, a NLP model trained with a general knowledge corpus is able to tell us that the concepts plane and airport are more closely related than plane and cat because they appear more frequently together. For instance, the Stanford NLP Group’s pretrained GloVe model with the Wikipedia corpus estimates that the relatedness (measured as the euclidean distance between vectors) between plane and airport is 6.94, while the distance between plane and cat is 9.04. Relatedness is measured by the frequency in which words appear closely together in a corpus of text. Apart from giving a quantifiable measure of relatedness between words, once an NLP model is trained, it enables us to make queries to obtain an ordered list with the closest words to a given word or set of words. This latter functionality is the one we use in our approach. Another advantage of these techniques is that they are able to deal with text documents regardless of whether they contain structured or unstructured data.
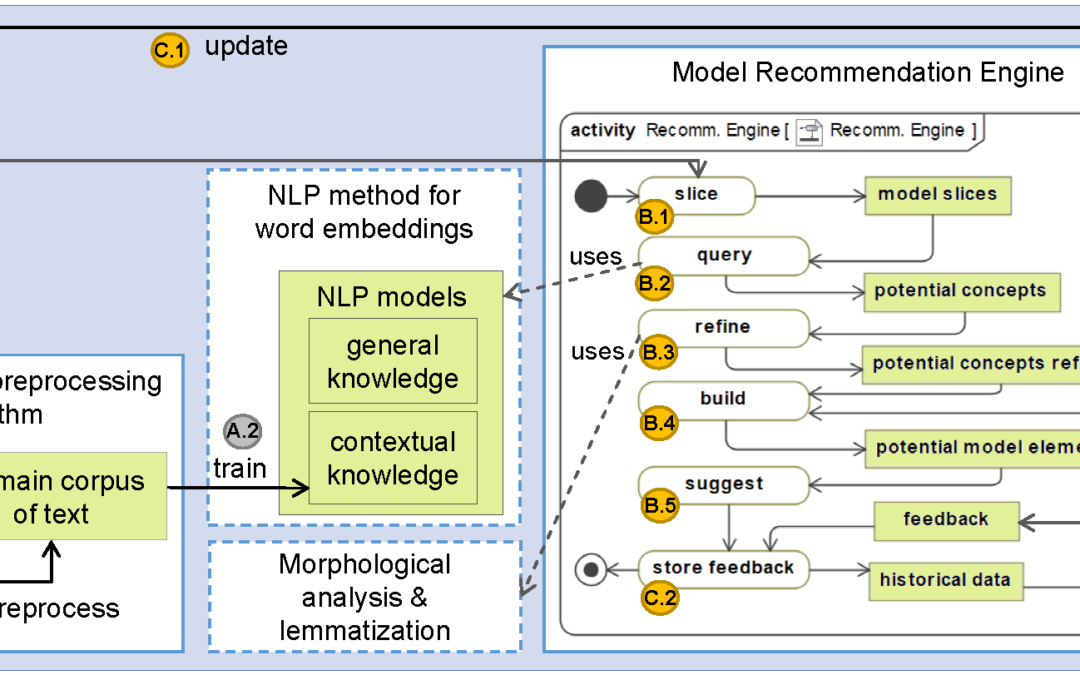
Our framework uses the lexical and semantic information provided by NLP learning algorithms and tools, together with the current state of the partial model and the historical data stored about the designer’s interaction with the framework. As output, it provides recommendations for new model elements (classes, attributes and relationships). The main components of our configurable architecture as well as the process that it follows to generate autocompletion suggestions are depicted in Fig 1. The logic of the algorithm implemented for the recommendation engine is depicted using an UML Activity Diagram.
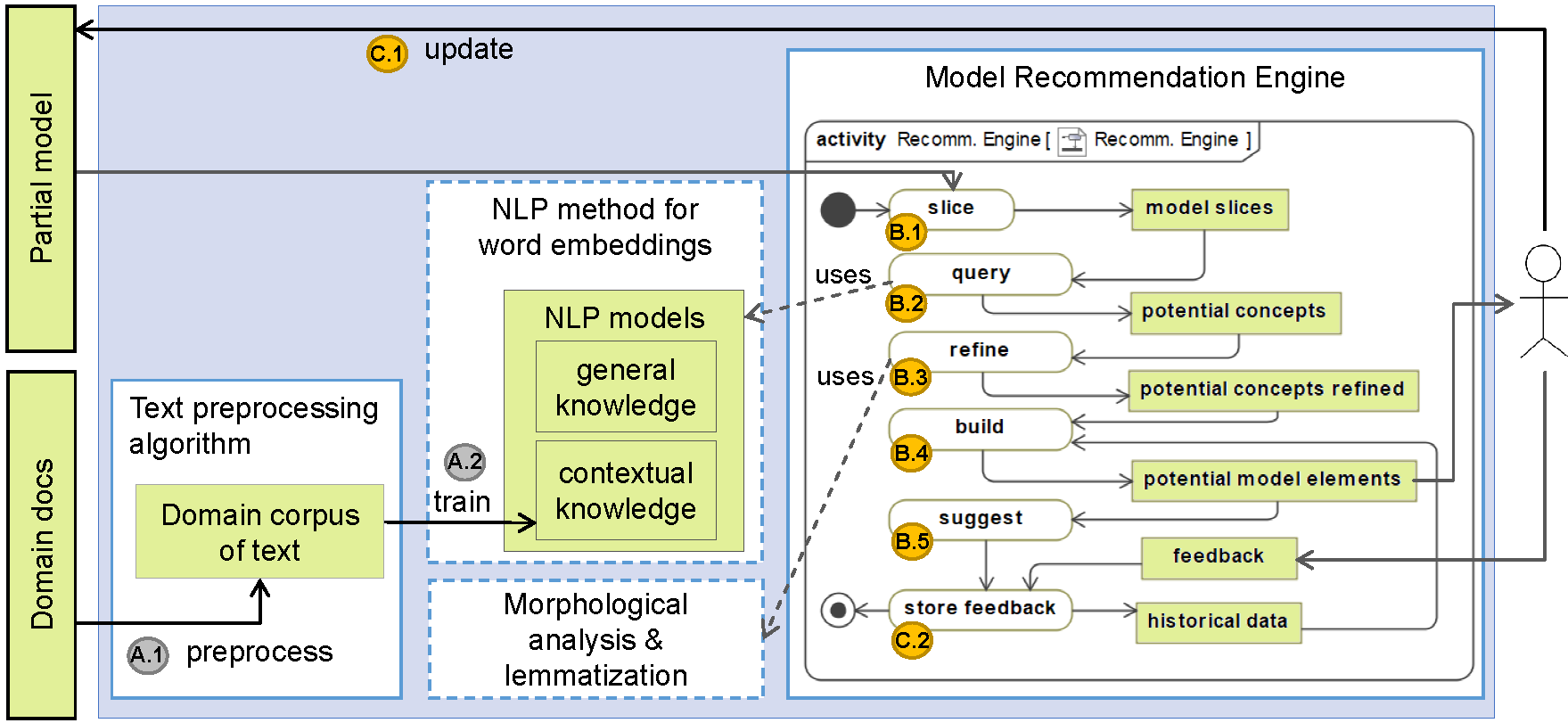
Fig. 1. Autocompletion Framework and Process for domain models
Step A: Initialization
Our process starts by preprocessing all the available documentation about the project to use it as input for the NLP training process. This step provides a corpus of text that satisfies the requirements imposed by the NLP algorithm chosen to create the NLP models, e.g., a single text file that contains words separated by spaces. For most NLP algorithms, this step consists of the basic NLP pipeline: tokenization, splitting, and stop-word removal.
Once all the natural language text has been preprocessed (i.e., the domain corpus is available), the NLP contextual model is trained. Note that we could use any of the NLP language encoding/embeddings alternatives mentioned before.
Instead, we do not train a NLP model for the general knowledge every time. Due to the availability of NLP models trained on very large text corpora of general knowledge data (such as Twitter, Wikipedia or Google News), we propose to reuse them. Therefore, neither Step A.1 nor A.2 apply to the general knowledge. Nevertheless, if desired, the use of a pretrained model could be easily replaced by collecting general knowledge documents and executing Steps A.1 and A.2 with them.
Step B: Suggestion Generation
Step B.1. Model Slicing
The input to this step is a partial domain model (e.g., a UML model). To optimize the results, we do not generate autocomplete suggestions using the full working model as input. Instead, we slice the model according to multiple (potentially overlapping) dimensions and generate suggestions for each slice. This generates a more varied style and a higher number of suggestions and enables the designer to also focus on the types of suggestions she is more interested in (e.g. attribute suggestions vs class suggestions).
The slicing patterns have been thoroughly designed taking into account the information and encoding of the NLP models to take full advantage of them. Each type of slice focuses on a specific type of suggestion. For instance, if we want to generate attribute suggestions, it is better to slice the model isolating the class for which we want to generate the attribute suggestions so that the NLP recommendations are more focused around the semantics of that class and avoid noise coming from other not-so-close classes in the model. There is clearly a trade-off of how much content should be included in each slice depending on the goal. We have refined our current patterns based on our experimental tests.
In short, in each iteration (steps B.1-C.2), we slice the model according to these patterns:
- one slice that contains all the classes in the model after removing their features (attributes and relationships);
- one slice for each class C in the model (keeping its attributes and dangling relationships); and
- one slice for each pair of classes (keeping its attributes and dangling relationships). These slices aim to suggest new classes, attributes and relationships, respectively, as we explain in step B.4.
Step B.2. Querying the NLP models and historical data to obtain word suggestions
Given a slice, we start by extracting the element names. They become the list of positive words employed to query the two NLP models (i.e., general knowledge and contextual knowledge). The historical data is used to provide negative words when querying the NLP models. Indeed, if the same list of possible words was used in the past to query the NLP models and the designer rejected a suggestion, that suggestion is stored in the historical data (as explained next in Step C.2), and used as a negative case here.
Each query returns a list of new word suggestions sorted by the partial ordering relation (e.g., Euclidean distance) between the embeddings of the initial list of words (i.e., the element names extracted from the model slice) and each suggestion. Therefore, the result after querying the two NLP models for each model slice returns two different lists of related concepts, sorted by shorter to longer distances between embeddings (i.e., sorted by relatedness) that we use to prioritize our suggestions. By default, we merge the two lists (the one coming from the contextual knowledge and the one from the general NLP models) into a single sorted list. If a word appears in both lists, the position in which the word appears in the merged list is that whose distance to the slice is smaller (i.e., the relatedness to the slice is higher).
This process can be customized. Our framework is parametrizable in two ways: (i) you can select the number of suggestions to receive at once, and (ii) customize how the two lists should be prioritized by defining a weight parameter. Regarding the latter, as previously said, by default, our engine mixes the recommendations coming from both sources into only one sorted list. Nevertheless, we provide a parameter to assign different weights to the two sources of knowledge, gn, a value in the range [0..1], where gn=0 means that the user does not want general knowledge suggestions at all, and gn=1 that she only wants general knowledge suggestions. The weight assigned to the contextual knowledge will be 1-gn. This prioritization can be used to only get contextual information suggestions, general ones, give different weights to each of them (so that they appear higher in the list) or even to ask for two different lists, which helps trace where the suggestions come from, improving the explainability.
Step B.3. Morphological analysis
Before building the potential model elements that will be presented to the designer, we perform some final processing of the lists to remove/refactor some candidate suggestions.
In particular, we use auxiliary NLP libraries (i.e., WordNet) to perform a morphological analysis of each word (Part-of-Speech (POS) tagging) followed by a lemmatization
process, paying special attention to inflected forms. For instance, if one of the terms returned by a query to an NLP model returns the word flyers, our engine lemmatizes it as a verb, resulting in the word fly; and as a noun, resulting in the word flyer. Therefore, it considers the three words as possible candidates to be the name of a new model element. We also use the POS tag to discard words when they do not apply (for instance, verbs as class names).
Step B.4. Building potential model elements to add
As a final step, we transform the refined lists of words into potential new model elements. The interpretation of the right type of model element to suggest depends on the type of slice we are processing.
For slices aiming at new class suggestions, the list of potential concepts refined returned by the NLP morphological analysis refinement step (B.3) is filtered to remove verbs, adjectives and plural nouns. After the filtering process, each of the remaining words, w, is a candidate to become a new class named w. For instance, let us assume that we are going to build a model in the domain of flights. Consider that we start from a partial model with a single class named Flight and no attributes as Fig. 2a shows. After the slicing, querying and lemmatization, we obtain the list of potential concepts refined [flights, plane, pilots, pilot, flying, fly, airline, airlines, airplane, jet].
We use the POS tag to filter the list by discarding verbs, adjectives and plural nouns. The list of remaining words is [plane, pilot, flying, fly, airline, airplane, jet]. For each word in this list, our algorithm suggests adding a new class with the same name.
For slices aimed at suggesting new features for a class C, for each output word, w, we offer the user three options:
- (a) add a new attribute named w to C (the user is in charge of selecting the right datatype);
- (b) add a new class called w and a new relationship between C and w;
- (c) if there is already a class called w in the partial model, our engine suggests the addition of a relationship between C and w.
Continuing with the example, for a slice containing the class Flight with no features (Fig. 2a), the list of potential concepts refined is: [flights, plane, pilots, pilot, flying, fly, airline, airlines, airplane, jet]. For example, when the designer picks the word pilot, she will receive the three options above, and she could select, for instance, to add it to the model as a new class and relationship (option b) and obtain the model in Fig. 2b.
For slices aimed at discovering new associations, each word, w, is suggested as a new association between the two classes in the slice. For instance, let us assume that we kept building the model and added a new class called Plane with no association with the other two (Fig. 2c). In this partial model, for the pair of classes Flight and Plane, our engine suggests the engineer to add associations with names: flights, pilots, pilot, flying, fly, jet, airplane. Our designer could select to add two relationships flights and plane to obtain the model in Fig. 2d.
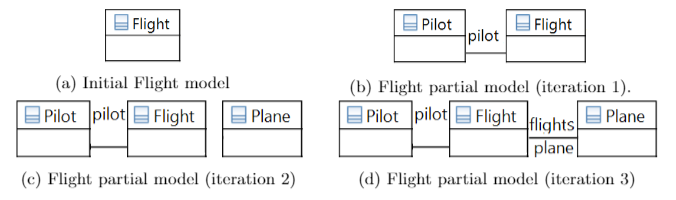
Fig. 2. Flight model evolution
Step B.5. Suggestions provided to users
In this step, the generated suggestions are provided to the designer. She can accept, discard or ignore each of them. While the two first options are processed (either by integrating them into the partial model or by marking them as negative test cases), when suggestions are ignored, we do not handle them and they can be presented to the designer in the future again.
Step C: Update model and historical data
Step C.1. Partial model update
In this step, the suggestion(s) accepted by the designer are integrated into the partial model.
Step C.2. Feedback and historical data
Every time the designer discards a recommendation, we store and annotate it as a negative example in order to avoid recommending it again and to guide the NLP model in an opposite direction (i.e., providing the concept as a negative case).
Note that the more complete the partial model is and the more feedback we have, the more accurate our suggestions will be.
Tool support
We briefly present the implementation of each component present in our architecture in Fig. 1.
Domain Corpus of Text. The text preprocessing algorithm that generates the domain corpus of text is implemented as a Java program that reads the input text documents, removes all special characters and merges them into a single textual file. The resulting file only contains words, line breaks and spaces.
NLP models. To build the NLP models we use the Stanford’s implementation of GloVe written in Python, which is an unsupervised learning method that creates word embeddings via statistical data analysis. It is trained on the entries of a global word-word co-occurrence matrix, which tabulates how frequently words co-occur with one another in a given corpus. Populating this matrix requires a single pass through the entire corpus to collect the statistics, which makes it an efficient method.
Our NLP component encapsulates two GloVe models, one trained with general data and one with contextual project one (when available). We have created a simple Java library with the necessary methods to create, train, load and query these two NLP models. This library provides functions such as get_suggestions(nlp_model, positive_concepts, negative_concepts, num_suggestions).
NLP tools. As auxiliary NLP tools for morphological analysis and lemmatization, we use WordNet, which is part of the Python NLTK (Natural Language Toolkit). We query WordNet to obtain the parts of speech of words (i.e., noun, verb, adjective, etc.) and use its lemmatization tool.
Model Recommendation Engine. Our implementation supports models in EMF (Eclipse Modeling Framework) format. Since this framework is implemented in Java and our engine needs to heavily interact with it, the model recommendation engine is implemented in Java, too. For example, our engine uses the EMF API to read the input domain model, represented as a UML class model and slices it. The engine is in charge of orchestrating also the previous Python components and implements the suggestion algorithm described before.
Historical Data. This component stores feedback from the designer. This feedback is stored for each user and model, i.e., it keeps track of the suggestions that the designer has discarded for each model. The discarded suggestions are used to both avoid suggesting them again and use them as negative cases from which we also learn. Given the way in which GloVe word embeddings are encoded, it enables the search of words that are both as close as possible to a set of words (positive cases) and as far as possible to another set of words (negative cases). The recommendation engine uses this feature when querying the NLP models.
Example
Let us consider an example of an industrial project: the introduction of a notice management system for incidents in the municipal water supply and sewage in the city of Malaga, Spain. In 2015, the Malaga city hall and the municipal water and sewage company (EMASA) started a project to manage the incidents that clients and citizens notify to have occurred either in private properties or public locations. This project replaced the previous process that was handled via phone calls and paper forms. In this project, contextual knowledge can be derived from the project documentation (e.g. requirements specification). Meanwhile, general knowledge can be extracted from texts in Wikipedia entries, Google News, or similar sources covering general water supply and sewage issues. The project developers produced manually the domain model of this system shown in Fig. 3.
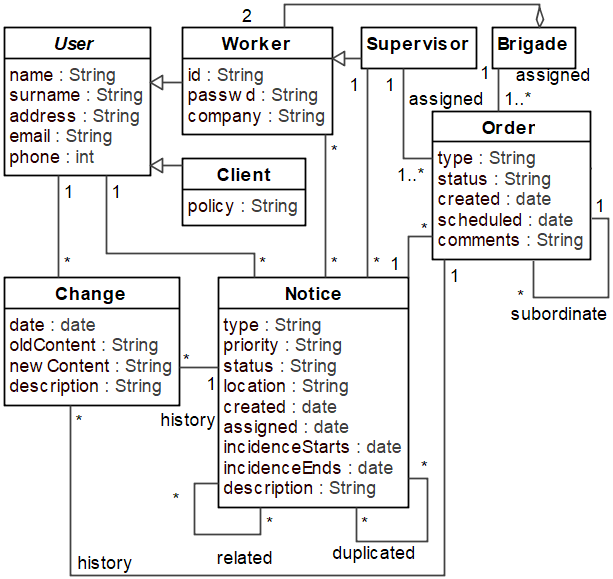
Fig. 3. Emasa domain model (manually created by experts).
For this experiment, the contextual model was trained with the project documentation provided by the client: a presentation (21 slides), forms and the software requirement specification document (78 PDF pages) that after being preprocessed turned into a 48KB text file with 7,675 words. These documents are not publicly available due to industrial property rights. Nevertheless, the software artifacts derived from them are available in our Git repository. For the general knowledge model, we have reused the GloVe word embeddings pretrained with the corpus of text from Wikipedia.
As a preliminary evaluation, we have taken 5 different sub-models from Fig. 3, each simulating a potential partial model with a single class and no attributes/relationships. Fig. 4 shows our five initial models.
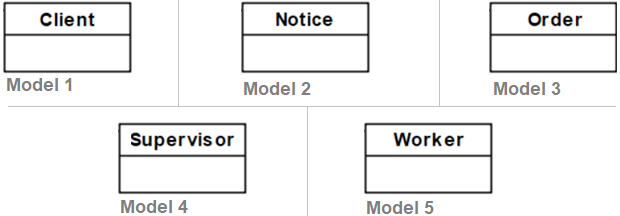
Fig. 4. Initial Models.
Starting from these models, our goal is to reconstruct the model shown in Fig. 3 from each partial model. We have parameterized our engine to provide 20 suggestions per round and opted to receive contextual and general knowledge separately.
We have automated the reconstruction process by automatically simulating the behavior of a designer using our framework. As we know the final target (the full model) we can automatically accept/reject the suggestions based on whether they do appear in the full model or not. Accepted ones are integrated in the (now extended) partial model. New rounds of suggestions are requested until no more acceptable suggestions are received.
As an example, Fig. 5 shows the autocompletion produced starting from an empty class Notice.
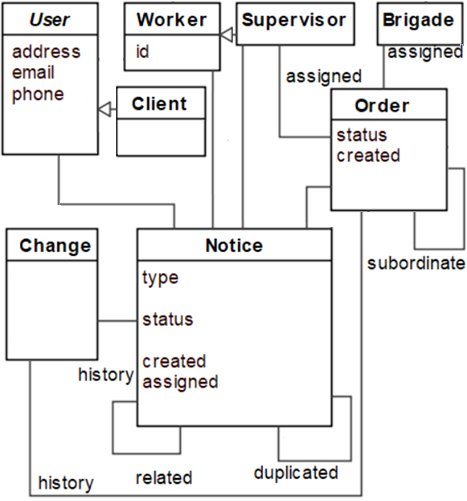
Fig. 5. Autocompleted domain model (fully automated).
Note that this evaluation can be regarded as a worst-case scenario as the evaluation criteria is very strict: in a real-case scenario, a designer could consider as good suggestions a broader set of scenarios as there is no single and unique correct model for any domain. And, obviously, real designers can completely stop the suggestions at any time, edit the model manually and then resume the suggestions again.
Results
Our experiments show that, in all 5 cases, our simulation has been able to reconstruct all classes, but not all attributes and relationships. On average, our approach was able to identify approximately 62% of the model.
Furthermore, on average, 85.7% of accepted suggestions came from contextual knowledge. This is expected as this is a very particular domain for which it is difficult to assume there is a rich-enough description in a general knowledge source. Nevertheless, the general knowledge has complemented the contextual one and has helped to discover implicit knowledge in the contextual descriptions.
These experiments have been executed in a machine with Windows 10, an Intel i7 8th generation processor at 1.80 GHz, 16Gb of RAM memory and 4 cores with 8 logical processors. We have observed that suggestions were always generated in less than one second.
More details about our experiments (e.g., precision, recall, performance, etc.) and technical details can be found in our paper CAiSE’21. A preprint can be accessed here.
Summary slides
Lola Burgueño is an Associate Professor at the University of Malaga (UMA), Spain. She is a member of the Atenea Research Group and part of the Institute of Technology and Software Engineering (ITIS). Her research interests focus mainly on the fields of Software Engineering (SE) and of Model-Driven Software Engineering (MDE). She has made contributions to the application of artificial intelligence techniques to improve software development processes and tools; uncertainty management during the software design phase; model-based software testing, and the design of algorithms and tools for improving the performance of model transformations, among others.


Hello Loli,
This is really an interesting approach. Should this by applicable for ArchiMate or BPMN models too?
Regards
Hello Bert,
Thanks!
The idea of extracting information from textual descriptions will be the same for any type of model and hence can be reused. The process dealing with the slicing of partial models and the generation of new model elements to be suggested needs to be adapted to the structure and semantics of each type of model though.
Loli.
Is there any *aaS platform for this approach?
Woud a Docker based strategy likely be the closest thing?
https://hub.docker.com/r/rappdw/docker-glove
If you mean GloVe, I’m not aware of any service publicly available. Our prototype needs to be executed locally. We’re working on improving our tool though. We will consider providing it as a service (if possible).