

(updated post to we present our latests improvements on NeoEMF, our solution to store and access large models in a scalable way).
NeoEMF is a multi-database model persistence solution, that is able to store models in several kind of NoSQL datastores. The framework is fully compatible with the EMF API, and allows to switch from one datastore to another using EMF’s Resource options. Users can then chose the datastore that fits the best it needs for a specific modeling task, and change to another later on if needed.
NeoEMF is based on a lazy-loading approach that brings into memory model elements only when they are accessed. The current version of the framework embeds three datastores:
- NeoEMF/Graph: persists models in a graph databases to take advantages of the rich traversal language they provide (shortest path computation, complex navigation paths among several vertices/edges)
- NeoEMF/Map: persists models in a collection of in-memory/on-disk maps that provide fast access to atomic operation
- NeoEMF/Column: persists models in a distributed column-based datastore, allowing to distribute intensive read/write workloads accross datanodes
The current version of NeoEMF has been presented at the demo session of the Models’16 conference, and an extended version is published as an Original Software Publication in Science of Computer Programming. This is the version we’re reporting here. You can find the complete article here, or continue reading below. For more information about the framework itself you can visit NeoEMF website, and the project wiki on Github which gives some technical details on how to use NeoEMF. We’ll be happy to discuss about our approach in the comments! (have you ever used NeoEMF? What datastore would you like to add? Did it improved your application’s support for large models? …)
Contents
Introduction
With the progressive adoption of MDE techniques in industry [5], existing model persistence solutions have to address scalability issues to store, query, and transform large and complex models. Indeed, existing modeling frameworks were first designed to handle simple modeling activities, and often relied on XMI-based serialization to store models. While this format is a good fit for small models, it has shown clear limitations when scaling to large ones [6].
To overcome these limitations, several persistence frameworks based on relational and NoSQL databases have been proposed [2,6]. They rely on a lazy-loading mechanism, which reduces memory consumption by loading only accessed objects. These solutions have proven their efficiency but are generally tailored to a specific data-store implementation, and integrating them into existing applications often implies to update the code base.
In this article we present NeoEMF, a scalable model persistence framework based on a modular architecture enabling model storage into multiple data stores. \NeoEMF provides three new model-to-database mappings that complement existing persistence solutions and enable to store models in graph, key-value, and column databases. The framework provides two APIs, one strictly compatible with the Eclipse Modeling Framework (EMF) API – which allows integrating \NeoEMF into existing modeling tools with a few changes on the code base – and an advanced API – which provides specific features complementing the standard EMF API to further improve scalability of particular modeling scenarios -.
Problem and Background
Databases are a well-known solution to store and query large models. They are used in current modeling frameworks, such as CDO [2] or Morsa [2], and have proven their efficiency compared to state-of-the-art XMI serialization. However, existing tools generally rely on a client-server architecture that provides an additional API that has to be integrated in client code to access the model (e.g. to create the server, open a new connection, commit changes, etc).
In these approaches, the choice of the datastore is totally independent of the expected model usage (for example complex querying, interactive editing, or complex model-to-model transformation): the persistence layer offers generic scalability improvements, but it is not optimized for a specific scenario. For example, a graph-based representation of a model can improve scalability by exploiting databases’ facilities to handle complex relationships between elements, but will have poor execution time performance in scenarios involving repeated atomic value accesses.
Our previous work on model persistence [3,4] has shown that providing a well-suited data store for a specific modeling scenario can dramatically improve performance [7]. Based on this observation, we introduce a novel modeling framework based on a multi-database architecture, each one providing optimized performances for specific modeling scenarios.
Currently, NeoEMF provides three implementations -map, graph, and column – respectively optimized for fine-grained access, complex querying, and distributed model transformations. Note that the extensible architecture of NeoEMF allows easily integrating new backends. Furthermore, NeoEMF is, to our knowledge, the only model persistence framework that provides a complete mapping to store models in Neo4j, MapDB, and HBase, complementing other approaches based on relational [2] or document databases [6].
Software Framework
This section presents the details of \NeoEMF. We first introduce an overview of the framework architecture and its integration in the modeling ecosystem, then we present the main functionalities of the tool and provide some pointers to advanced usages.
Software Architecture
Figure 1 describes the integration of NeoEMF in the Eclipse-based EMF ecosystem, the most popular modeling framework nowadays. Modelers typically access a model using Model-based Tools, which provide high-level modeling features such as a graphical interface, interactive console, or query editor. These features internally rely on EMF’s Model Access API to navigate models, perform CRUD operations, check constraints, etc. At its core, EMF delegates the operations to a persistence manager using its Persistence API, which is in charge of the (de)serialization of the model. The NeoEMF core component is defined at this level, and can be registered as a persistence manager for EMF, replacing, for instance, the default XMI persistence manager. This design makes NeoEMF both transparent to the client-application and EMF itself, that simply delegates the calls without taking care of the actual storage.
Once the NeoEMF core component has received the request of the modeling operation to perform, it forwards the operation to the appropriate database connector (Map, Graph, or Column), which is in charge of handling the low-level representation of the model. These connectors translate modeling operations into Backend API calls, store the results, and reify database records into EMF EObjects when needed. NeoEMF also embeds a set of default caching strategies that are used to improve performance of client applications, and can be configured transparently at the EMF API level.
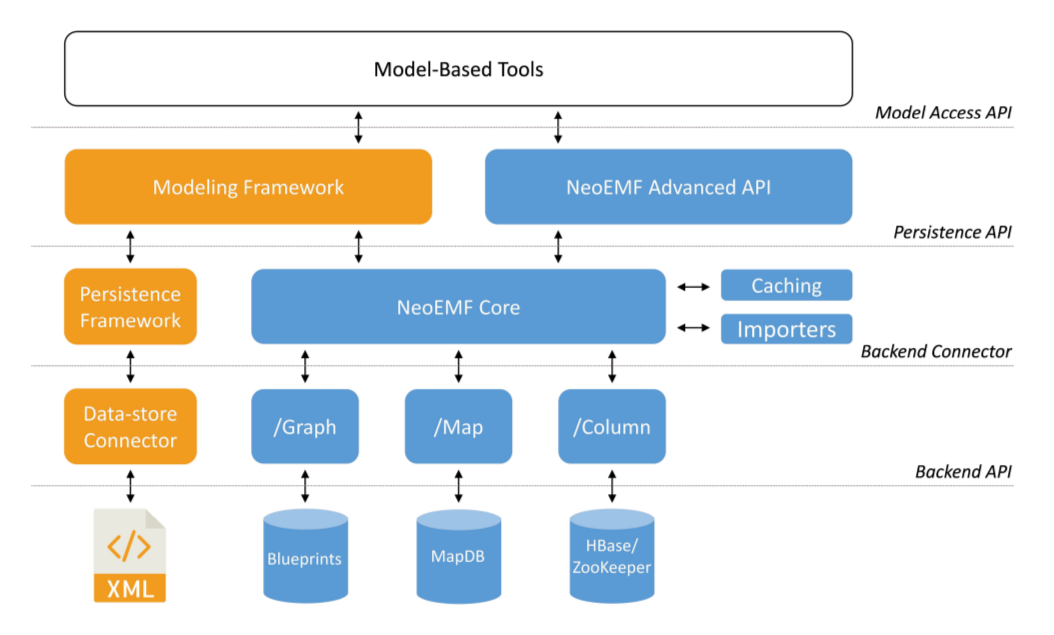
Figure 1. NeoEMF Integration in EMF Ecosystem
The package diagram shown in Figure 2 details how the NeoEMF core component interacts with the NeoEMF/Graph database connector. Note that the same architecture is used for the NeoEMF/Map and NeoEMF/Column connectors. A PersistentResource is the NeoEMF implementation of the EMF Resource interface. It contains a set of PersistentEObject (the NeoEMF implementation of EObject) and references a PersistentStore that handles EMF API calls (add, get, set methods) and delegates them to a PersistenceBackend which manipulates the underlying database. When a new PersistentResource is created, it retrieves from a global PersistenceBackendFactoryRegistry the PersistenceBackendFactory associated to its uri, and uses it to create the PersistentStore and PersistenceBackend to use to store the model.
The NeoEMF/Graph component extends the core architecture at four levels: it defines (i) a BlueprintsURI class that is used to create graph-based PersistentResources, (ii) a BlueprintsPersistenceBackend that extends PersistenceBackend by providing methods to manipulate graph databases (addVertex, addEdge, etc), (iii) a BlueprintsStore that maps EMF API operations to the graph primitives provided by the BlueprintsPersistenceBackend, and (iv) a dedicated BlueprintsPersistenceBackendFactory that creates instances of BlueprintsStore and BlueprintsPersistenceBackend from BlueprintsURIs. Using this architecture, creating a graph-based PersistentResource only requires to associate BlueprintsURI and BlueprintsPersistenceBackendFactory in the PersistenceBackendFactoryRegistry. The created graph-specific store and backend are transparently associated to the PersistentResource.
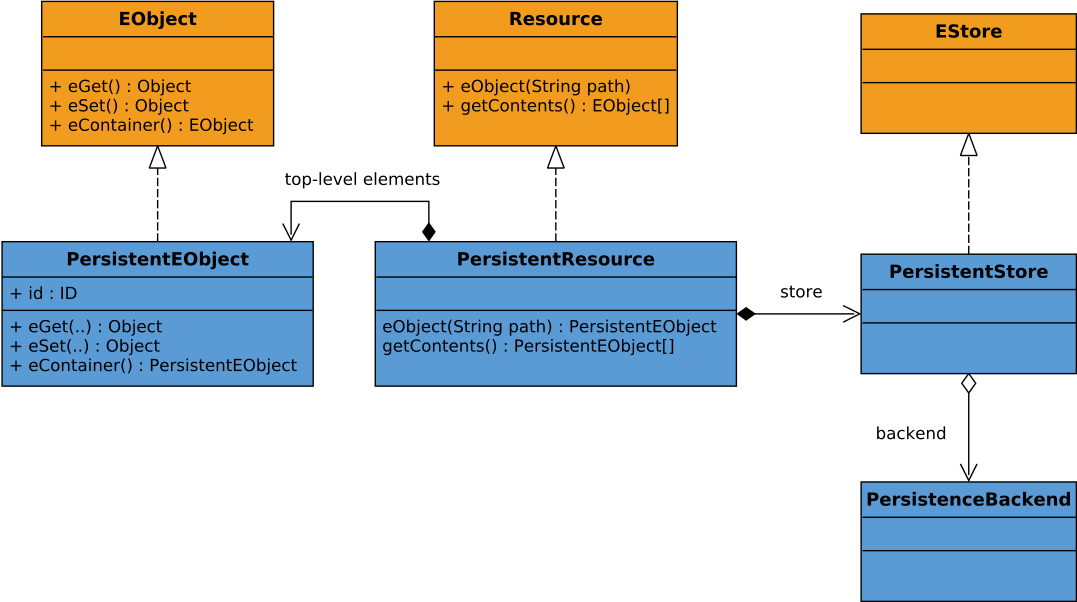
Figure 2. NeoEMF Backend Interface
Software Functionalities
An important characteristic of NeoEMF is its compliance with the EMF API. All classes/interfaces extending existing EMF ones strictly define all their methods, and we put a special attention to ensure that calling a NeoEMF method produces the same behavior (including possible side effects) as standard EMF API calls. As a result, existing applications can easily integrate NeoEMF and benefit immediately from its scalability improvements. Current code manipulating regular EMF EObjects does not have to be modified, and will behave as expected.
Specifically, NeoEMF supports all typical EMF features including: (i) a dedicated code generator that allows client applications to manipulate models using generated java classes, (ii) support of Reflective/Dynamic EMF API, and (iii) a Resource API implementation.
As other model solutions, NeoEMF achieves scalability using a lazy-loading mechanism, which loads into memory objects only when they are accessed. Lazy-loading is defined at the core component: NeoEMF implementation of EObject consists of a lightweight wrapper delegating all its method calls to an EStore, that directly manipulates elements at the database level. Using this technique, NeoEMF benefits from datastore optimizations (such as caches or indices), and only maintains a small amount of elements in memory (the ones that have not been saved), reducing drastically the memory consumption of modeling applications.
In addition to its compliance with the EMF API, NeoEMF provides specific utility features to bypass EMF’s limitations, tune internal data stores, and configure caches.
Datastores
The previous features are available for a variety of databases supported by NeoEMF. In this section we introduce the different available data stores, describing briefly the model representation in these stores, their differences and the specific modeling scenario they better address. Both standard and advanced features presented in the previous section are implemented in all of them.
NeoEMF/Map has been designed to provide fast access to atomic operations, such as accessing a single element/attribute and navigating a single reference. This implementation is optimized for EMF API-based accesses, which typically generate this kind of atomic and fragmented calls on the model. NeoEMF/Map embeds a key-value store, which maintains a set of in-memory/on disk maps to speed up model element accesses. The benchmarks performed in previous work [4] shows that NeoEMF/Map is the most suitable solution to improve performance and scalability of EMF API-based tools that need to access very large models on a single machine.
NeoEMF/Graph persists models in an embedded graph database that represents model elements as vertices, attributes as vertex properties, and references as edges. Metamodel elements are also persisted as vertices in the graph, and are linked to their instances through the instance_of relationship. Using graphs to store models allows NeoEMF to benefit from the rich traversal features that graph databases usually provide, such as fast shortest-path computation, or efficient processing of complex navigation paths. For instance, these advanced query capabilities have been used to develop the Mogwaï tool [1], that maps OCL expressions to graph navigation traversals.
NeoEMF/Column has been designed to enable the development of distributed MDE-based applications by relying on a distributed column-based datastore.
In contrast with Map and Graph implementations, NeoEMF/Column offers concurrent read/write capabilities and guarantees ACID properties at model element level. It exploits the wide availability of distributed clusters in order to distribute intensive read/write workloads across datanodes.
Implementation and Empirical Results
NeoEMF has been implemented as a set of open source Eclipse plugins distributed under the EPL license. The NeoEMF website presents an overview of the key features and current ongoing work. The source code repository and wiki are available on GitHub (http://www.github.com/atlanmod/NeoEMF). NeoEMF has been used as the persistence solution of the MONDO European project and is used to store large models automatically extracted from reverse engineering processes.
In the following we present a result extracted from the NeoEMF benchmarks available on the project repository (see the wiki for more details and complete results). Note that additional evaluations are also provided in our previous work [3,4]. We consider four persistence solutions in our evaluation: NeoEMF/Graph, NeoEMF/Map, CDO, and the default XMI serialization mechanism of EMF. The executed query accesses the model using the standard EMF API, making them agnostic of which backend they are running on.
The executed query is extracted from a software modernization use case, and finds in a model representing a Java program all the unused methods, that corresponds to private methods that are not internally called. The query is executed over three models of increasing sizes, containing respectively 6756, 80665, and 1557007 elements.
Results
Table 1 presents the results of executing the presented query over the benchmarked persistence frameworks. Note that execution time is measured in milliseconds, and each table cell contains both the execution time in a large (8} GB) and a small (512 MB) JVM configuration, in order to evaluate how the persistence frameworks handle highly-constrained memory environments.
| Model | XMI | CDO | NeoEMF/Graph | NeoEMF/Map |
| set1 | 7 / 7 | 3213 / 2924 | 1942 / 2346 | 1425 / 1437 |
| set2 | 46 / 42 | 12255 / 12169 | 10274 / 11652 | 7283 / 7177 |
| set3 | 654 / OOM | 171558 / 1160980 | 97782 / 1368399 | 114539 / 118498 |
Discussion
The analysis of the results show that both NeoEMF/Graph and NeoEMF/Map are interesting candidates to store and access large models in constrained memory environments. Both NeoEMF implementations perform better than CDO in a large JVM context, and are able to handle set3 in a constrained memory environment while XMI-based implementation crashes with an OutOfMemory error. However when the model to query fits in memory, the XMI serialization outperforms all the existing solutions in terms of execution time. This result is expected because XMI initially loads the full model, allowing to compute the entire query in memory while lazy-loading approaches bring into memory elements when they are needed, and have to perform more input/output operations to enable element unloading and improve memory consumption.
In the presented results NeoEMF/Map outperforms other scalable persistence frameworks in terms of exectution time. In addition, the constrained memory environment does not have a significant impact on the connector’s performance, enabling very large model querying. This can be explained by the model to data-store mapping used in NeoEMF/Map that is optimized to access a single feature from a modeling element. Technically, the framework does not require any complex in-memory structure to represent the model, and only keeps in memory one key-value pair representing the element currently processed. This architecture allows removing elements from memory as soon as they have been processed, thus reducing the memory consumption.
NeoEMF/Graph also outperforms CDO when a large virtual machine is allocated to the computation, but is less interesting in constrained memory environment. This can be explained by the underlying model to graph mapping, which allows efficient model navigations, while CDO’s relational schema requires multiple table join operations to compute a complex navigation. However, the nature of the EMF API that performs low-level and fragmented queries implies a lot of database lookups to find a node corresponding to a given element, which is typically costly in terms of memory in graph databases, limiting NeoEMF/Graph benefits in highly constrained memory environment.
Example
NeoEMF wiki provides a set of examples and resources for beginners and advanced users: a tutorial showing how to install and get started with NeoEMF, a ready to use demonstration, code examples, database configuration snippets, and specific backend configurations. An additional demonstration video is available online.
As an example, Listing 1 shows how to create and manipulate a NeoEMF/Graph Resource. First, we register the BlueprintsPersistenceBackendFactory that will be used to create the database connection and persist the model (lines 1 and 2). This initial step is specific to NeoEMF, but it is transparently done when running the application in an Eclipse-based environment, thanks to the extension points mechanism. Then, we create and initialize a ResourceSet using standard EMF methods (lines 4-6) and associate the PersistentResourceFactory to the NeoEMF/Graph protocol. The ResourceSet is then used to create a Resource using the BlueprintsURI helper to create a NeoEMF/Graph compatible URI (lines 8-9). NeoEMF provides option builders to ease the definition of backend-specific settings through the standard EMF option Map. In our example we use the builder BlueprintsNeo4jOptionsBuilder to set the autocommit behavior to our Resource (lines 10-11). Finally, we save the Resource to create the underlying database with the provided options, and we manipulate it using standard EMF API calls (lines 12-14).
Listsing 1. NeoEMF Resource Creation and Manipulation
PersistenceBackendFactoryRegistry.register(BlueprintsURI.SCHEME,
BlueprintsPersistenceBackendFactory.getInstance());
ResourceSet rSet = new ResourceSetImpl();
rSet.getResourceFactoryRegistry().getProtocolToFactoryMap()
.put(BlueprintsURI.SCHEME, PersistentResourceFactory.getInstance());
Resource resource = rSet.createResource(
BlueprintsURI.createFileURI(new File("models/sample.graphdb")))) {
Map<String,Object> options = BlueprintsNeo4jOptionsBuilder.newBuilder()
.autocommit().asMap();
resource.save(options);
resource.getContents().add(...); // Standard EMF calls
resource.save(options);
Conclusion
We have presented NeoEMF, a multi-datastore model persistence framework. It relies on a lazy-loading capability that can be configured to load model elements individually or larger collections, allowing very large model navigation in a reduced amount of memory, by loading elements when they are accessed. NeoEMF provides three implementations that can be plugged transparently to provide an optimized solution to different modeling use cases: atomic accesses through interactive editing, complex query computation, and cloud-based model transformation.
References
[1] Gwendal Daniel, Gerson Sunyé, and Jordi Cabot. Mogwaï: a Framework to Handle Complex Queries on Large Models. In Proc of the 10th RCIS Conference, pages
225–237. IEEE, 2016.
[2] Eclipse Foundation. The CDO Model Repository (CDO), 2017.
[3] Abel Gómez, Amine Benelallam, and Massimo Tisi. Decentralized Model Persistence for Distributed Computing. In Proc. of the 3rd BigMDE Workshop, pages 42–51. CEUR-WS.org, 2015.
[4] Abel Gómez, Gerson Sunyé, Massimo Tisi, and Jordi Cabot. Map-based Transparent Persistence for Very Large Models. In Proc. of the 18th FASE Conference, pages 19–34. Springer, 2015.
[5] John Hutchinson, Jon Whittle, and Mark Rouncefield. Model-driven engineering practices in industry: Social, organizational and managerial factors that lead to
success or failure. SCP, 89:144–161, 2014.
[6] Javier Espinazo Pagán, Jesús Sánchez Cuadrado, and Jesús García Molina. A repository for scalable model management. SoSym, 14(1):219–239, 2015.
[7] Seyyed M Shah, Ran Wei, Dimitrios S Kolovos, Louis M Rose, Richard F Paige, and Konstantinos Barmpis. A framework to benchmark NoSQL data stores for large-scale model persistence. In Proc. of the 17th MoDELS Conference, pages 586–601. Springer, 2014.
I am a postdoctoral fellow in the Naomod research team and co-founder of Xatkit. My research interests are mostly focused on foundations of Model-Driven Engineering, such as model persistence, querying, and transformation, but also on the application and democratization of MDE techniques to concrete domains.


It’s unclear to me what size models this framework supports and how this is fundamentally better than a CDO-based solution. Is there a side-by-side comparison somewhere? Is it related to the amount of low-level configuration of CDO that is required to scale? The models I manipulate are very large (100M+ object range) and, yes, we’ve had to add some lower-level hooks to the persistence framework. But, that’s not necessarily out of the ordinary if you want to scale up.
Hi Stéphane,
I would not say that NeoEMF is fundamentally better but different. Gwendal may be able to provide a more technical answer / evaluation but I would summarize the 2 main reasons why we’ve built NeoEMF as:
– NeoEMF does not use a single type of backend but provide several ones and in our experience different use case scenarios (even for the same model) require different backends for optimal performance
– NeoEMF is at the same time fully compatible with the EMF API (which to us is important) and offers a “backdoor” we can use when not only the model is big but the query is complex (in this case, we bypass the API and benefit from the the more natural representation of models in a graph database to execute our query directly there and only bring back the final result, see Mogwaï: Querying large models via an OCL to NoSQL / GraphDB transformation
Thanks Jordi for the answer.
I’m a bit surprised by the first reason you mention. You use several backends to store and query a same model? I’d be interested in how you manage that. To build our large models, we had to use some specialized patterns (like CAS) to ensure that the model stays consistent.
As for the second point, that’s something in our pipeline. Chances are that we’ll likely do that for XPath support before OCL. FYI, our datastore is HyperGraphDB.
Hi,
Not the same model at the same time. What I meant is that knowing how you’re going to use a model allows to choose the best backend for that scenario. If the way a model is typically used evolves you can also switch it to another backend. BUT if you use the same model in several scenarios at the same time, then so far you’re forced to choose the backend offering the best trade-off
Hello
I read the arcticle with great interest, as we are looking for persistency solution for our modeling framework for planning and optimization MOPLAF.
It is certainly valuable to offer a generic framework to provide model persistency. But the solution should not bind the user to a given solution (or framework). We want to offer reusable components that do not force the integrator to a given persistency provider of framework; components that should be able to work in different contexts. Concretely, I do no want my object inherit from PersistentEObject nor my components depend on some NeoEMF plugin. Why is this dependency necessary?
Hi Michel,
I am not sure I understood completely your question, so please forgive me if this reply does not address all your concerns. NeoEMF is based on the EMF infrastructure, that contains a generic layer (EObject, Resource, etc.), and a code generator that creates concrete implementations of this generic layer based on a given model. In the EMF environment, every generated class extends EObject. NeoEMF follows the same approach: it provides a custom implementation of the EMF generic layer (PersistentEObject, PersistentResource, etc), and a custom code generator that relies on the NeoEMF generic layer. As you can see in this architecture, there is a mandatory dependency between the generated code and the NeoEMF core plugin. However, please note that there is no mandatory dependency between the generated code and the concrete data storage solution that is used to store and access the model (hbase, mapDB, blueprints), such dependencies can be added manually based on the application requirements (and combined if the modeling scenario involves different tasks that could be optimized by different data stores).
If you want to build a modeling solution that handles several persistence approach (such as CDO, NeoEMF, EMF-Fragment, or any other model storage solution), you may need to define an additional layer unifying their APIs in order to access them transparently using your component-based infrastructure.
Regards,
Gwendal