
I’ve been trying to write software that writes software for at least 20 years. My latest attempt doesn’t generate code, it interprets models at run time, which is why I called it ModelRunner.
ModelRunner is a complete data management platform which acts as a semantic layer above structured databases.
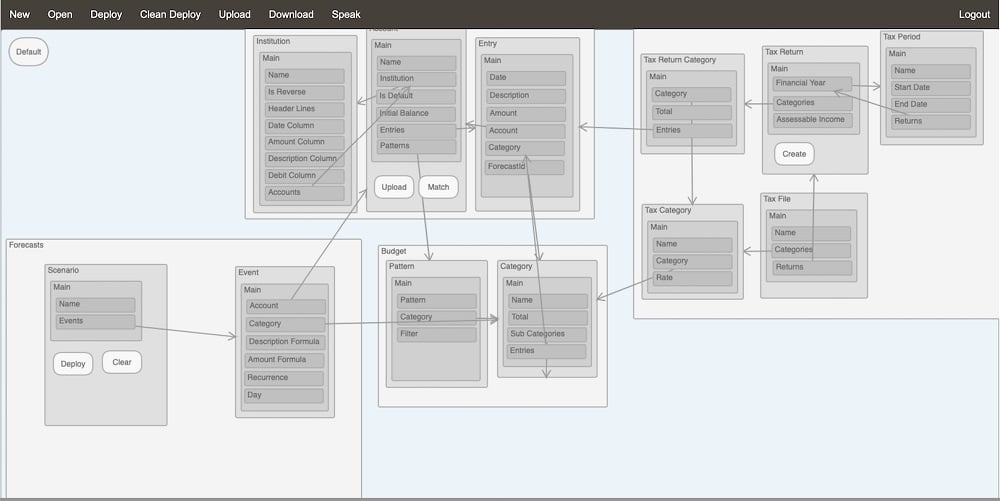
It interprets information models which are basically a mix between ER models and UML diagrams in that they describe Entities and Attributes but also include a few extra artefacts like Applications, Packages, Actions etc and support all UML relationships (plus Back References) as well as formulas which can be expressed in object notation like Person.Name and can include functions like Sum(OrderLines.Amount).
It also leverages workflow models where you can specify what happens when a data object is created or deleted or when a pre-requisite condition, expressed as a formula, becomes true.
But you’re probably thinking: “there are plenty of low-code, no-code platforms around, how is this one different?”.
Thanks for asking! The obvious main difference is that it provides a voice interface out-of-the-box and by this I mean that it doesn’t involve machine learning at all, so you don’t need enormous amount of data to train a domain specific NLU (Natural Language Understanding) model. It just leverages the semantics in the model and a simple lexicon to build an ontology which is used to process each term in the query.
This is how it works.
Design your model
It comes with a web based graphical model editor but, if you don’t like using a mouse or a keyboard, you can just talk to Google Chrome and ask the editor to create the model for you by saying things like “Please create an application called Test”, “add a Type called Person”, “add a Reference Attribute called City and set reference to City”, etc. All thanks to the Google Speech API.
Then, when you’re ready, you just need to deploy the model which you can do by clicking on “Deploy” or you could just ask nicely by saying something like “Could you please deploy the application?”.
Manage your data
Once the model is deployed, you are ready to log in to the meta-application. Select which model you want to use and you can start using a classic data driven web application to manage your data. Although, it’s not exactly a classic application because it also includes a voice interface where you can say things like “could you please create a city called Melbourne and set Zip Code to 3000 and set Notes to the most liveable city in the world” or “Get me a list of people in Melbourne aged 50”.
Here’s a short demo showcasing the voice interface:
Where are the super chatbots we were promised 10 years ago?
To understand how it works, we need to look back 40 years, when I was learning programming on my Commodore 64 … this thing could already speak! It did have a pretty strong robot-like accent but it could say “I am the Commodore 64” very well, which made Star Wars and R2D2 look like the very near future! Yet, 40 years later, we still don’t have R2D2! Why is that? And what happened to the super chatbots Gartner promised 10 years ago when they predicted: “By 2020, customers will manage 85% of their relationship with the enterprise without interacting with a human. The smart machine era will be the most disruptive in the history of IT.” – Gartner Customer 360 Summit 2011.
To me, the answer to this question is that it is easy for chatbots to chat but that’s about it. They can carry out scripted conversations and extract intent and parameters from a user’s utterances but in order to do anything with these, they need to interact with backend systems which typically have very rigid APIs. So, on the one hand we have very flexible ML-based voice and text interfaces but on the other hand, very old style backends which expect things the way they should be, i.e., the account number should be here and the transaction amount should be there and in this format or you get the equivalent of the old BASIC “Syntax Error!”.
The problem is that the conversational interface has usually no understanding of the application domain: to train a typical bank chatbot on how to check your bank balance, you need hundreds of utterances like “what’s my account balance?”. It works well but the chatbot doesn’t know what an account is or that it has something called a balance. It just assigns the #BALANCE_INQUIRY intent to the utterance and continues down the script to ask relevant details like the account type which gets assigned to a variable which in turn gets used by some form of custom script to populate query parameters and issue an API call which response needs to be parsed again with more custom code to populate another variable used in the chatbot dialog to provide the result to the user … wow!
NLU? Just leverage the semantics in the model
So this is why I think my code is different: because understanding the domain model is at the core of everything it does, interpreting natural language queries relating to the application’s domain is (almost) simple. So when asked “what’s the balance of my savings account?” it knows that “account” relates to an Account entity, that “balance” is an attribute in the Account entity which also has a Type attribute that points to an AccountType entity which has a Name attribute and that one of the AccountType objects has the value “Savings” for its Name attribute. So, by understanding the domain model and having access to the data itself, returning the balance of the Savings account is just a matter of retrieving the Account object which has an AccountType with the Name “Savings” and return the content of it’s Balance attribute.
And it works regardless of the domain model. No Machine Learning, no custom code, no magic either, just an interesting coding exercise.
And it’s Open Source!
I’ve put it all in GitHub with an MIT Open Source license: https://github.com/etiennesillon/ModelRunner. It’s not yet very well documented but I’m working on it. So please have a look and send me your comments! Thank you!



NLU = Natural Language Understanding. You are welcome.
Thanks (and true, I’ve updated the post to clarify this the first time NLU appears in the text)