
-> Want to skip ahead? Here’s the next installment.
Hi, everyone! I am writing this new series of articles to take you step by step through the construction of a complete set of Executable UML (xUML) models. Presented with an initial set of fuzzy, incomplete and possibly contradictory requirements, we will beat them into submission in the form of an unambiguous, detailed, constrained and executable statement of the desired system. We will not begin with the classical “high level” UML models of years past. No, we aim to take the bull by the horns and tame it before breakfast. We will take the straightest path from fuzziness to absolute clarity and then deliver production code. Who’s with me? ✋
Our case study will not be a toy problem. No washing machine, ATM, gas pump or toaster here. We’re going to tackle a complete elevator system for tall buildings where the cabins accelerate as appropriate to provide express service. In fact, this case study is large enough that after we sketch out the overall system architecture, we will focus in on the primary application, stubbing out the rest. So rather than build a complete toy model, we will build a component of a much larger system, all the while maintaining a detailed context for the surrounding elements. Among other things, our architectural sketch will establish which details are modeled and which details are delegated to non-xUML system components. We aim to be specific about where everything is handled. No sweeping details under the rug with vague statements like “that will get worked out during implementation”!
The case study is an elevator (“lift” for our British friends) management system. This, of course, is not the first time such an example has been explored in the realm of software modeling and for good reason. Most of us have real-world experience with elevators so we can keep our focus on modeling without having to spend much time explaining the underlying subject matter. At the same time, the elevator system is rich enough to yield a worthwhile modeling exercise.
The relevant models, code and supporting documents for each installment of this series of articles will be posted at executableuml.org. Once all of the articles have been published, the completed elevator application will be available as an open source case study for educational and tool demonstration/benchmarking purposes.
Our recently published book Models to Code (you may want to check as well this interview where I talk about the book and my “xUML philosophy”) shows how to generate code from Executable UML models using an open source tool chain named Pycca. In this tutorial series we will introduce another open source tool chain named Rosea which provides a completely different model-to-code path. Whereas Pycca targets C code on a micro-controller, Rosea targets Tcl which you can run on a wide variety of desktop/server operating systems. What, not a big fan of Tcl or C? No worries, our focus here is on the platform independent models. Once you have these, you can choose your own path to code from the same source models without having to change them.
I invite you to comment and ask questions either here or via any of my many social channels. I will do my best to respond.
Before diving in, let’s examine two powerful features of xUML that distinguish it from your dad’s (or mom’s) UML.
Platform Independence
This is another way of saying that we want to separate the implementation from the essential requirements and then only model those requirements. So, once we capture the rules for how elevators should behave, nothing in the code design/generation process requires any alteration of those models. To get code, you will need to layer on implementation information, of course, but that information remains in a distinct layer, possibly as one or more markup files. Target another platform and you change the markup, not the models. Need to support multiple platforms? Same models, multiple markups and, possibly, more than one code generation path. No matter what target language, operating system, degree of parallel processing, programming style (functional, object-oriented, etc), the models are not affected. Executable UML gives us the means to express rules in great detail, independent of any platform technology, which we can run and test prior to code generation.
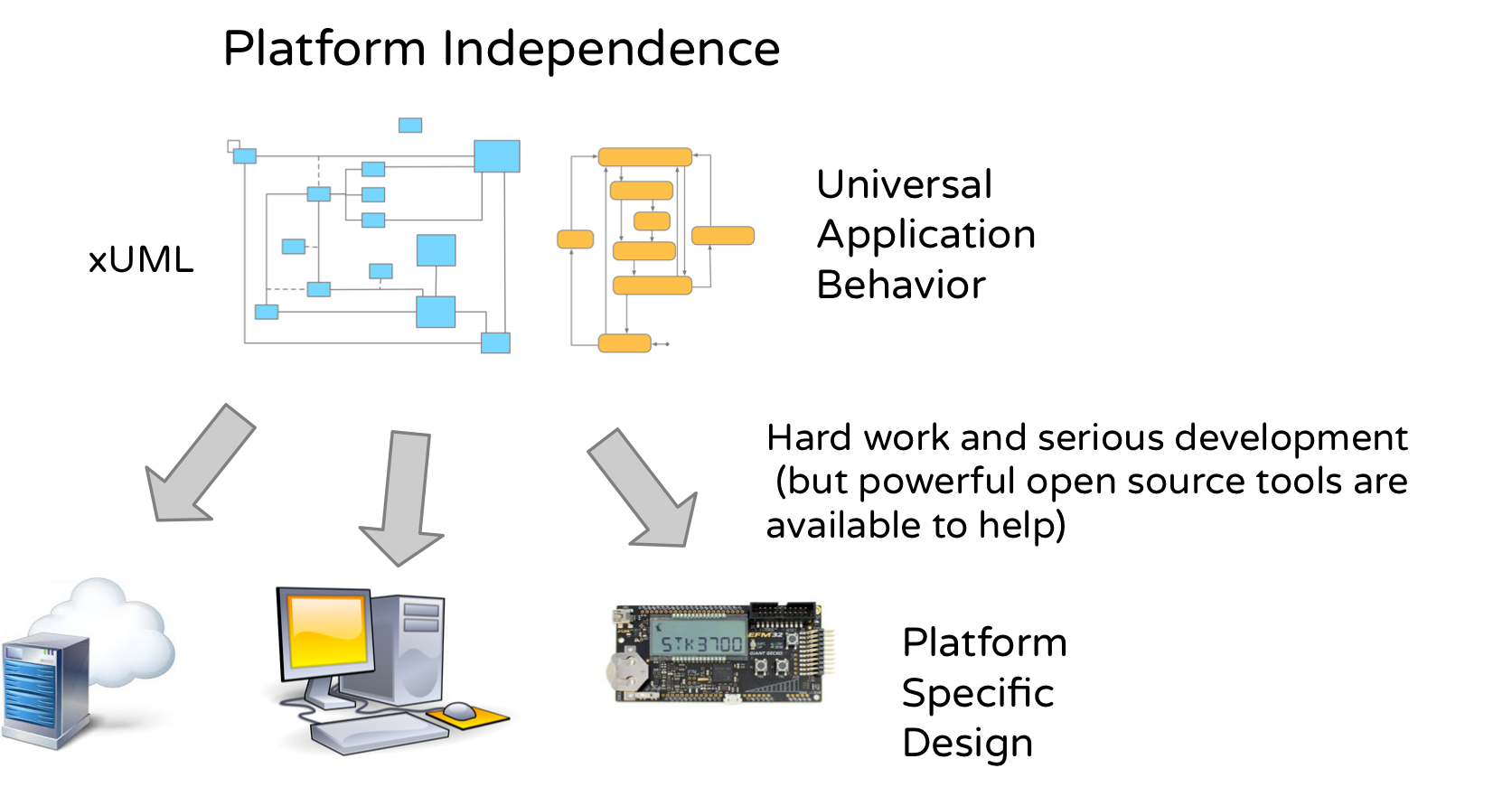
For example, the requirement that the doors of a cabin cannot open while the cabin is in transit is one such platform independent rule. Not only can this rule be formalized distinct from any implementation, it MUST be preserved on every potential platform. The rule doesn’t care about your favorite template library. The models do change, however, if, and only if, the requirements change. Here in Sweden, I live in an apartment building where there is no inner door and, as an American on my first visit, I watched in bemusement as the floors flew by. So a Swedish version of our elevator model might be different.
Most large systems have tons of data, rules, constraints, behavior and computations that can, and should, be isolated from any specific implementation. If this task were easy, platform independence would be the rule rather than the exception. At least two major obstacles stand in the way. First, you need a modeling language that is simultaneously nit-picky enough to express executable detail, yet abstract enough that it doesn’t rely on any implementation assumptions. But it’s not enough to have a language (or the tools to support it). The entire skill set necessary to build effective platform independent models, is quite distinct from that of programming. A common organizational mistake is to blindly promote programmers to modelers, send them out for a little tool training and then expect modeling magic to happen. It doesn’t. Instead of magic, you get models that so closely mirror Java or C++ designs that it would have been more productive to just write code. That said, I have worked with many fine programmers who have acquired analysis and modeling skills with enthusiasm, but they are notable exceptions. Those analysis and modeling skills antithetical to a programming mentality are something I will be pointing out as we model along.
A common organizational mistake is to blindly promote programmers to modelers, send them out for a little tool training and then expect modeling magic to happen. Click To TweetI won’t lie to you, a lot of hard work goes into implementing models on distinct platforms. The good news is that once you’ve developed (or acquired) the technology to support a class of platforms, you can re-use that model-to-code path for numerous applications and platform variations. Nonetheless, it is foolish to charge forward modeling without a clear path from models to code on your particular class of platform.
Executability
To execute like code, a model must be painstakingly detailed, expressing data, rules, constraints, synchronization and computations. Unlike code, we can omit implementation details such as choices of data structure (array vs. linked list), concurrency (services vs. threads vs. tasks vs. one big loop), persistence mechanisms and so on. Unlike classical UML, xUML dispenses entirely with the ill-defined notion of “high” and “low” levels of detail. As you will see, it’s the nature and not the degree of detail that varies from one model to the next.
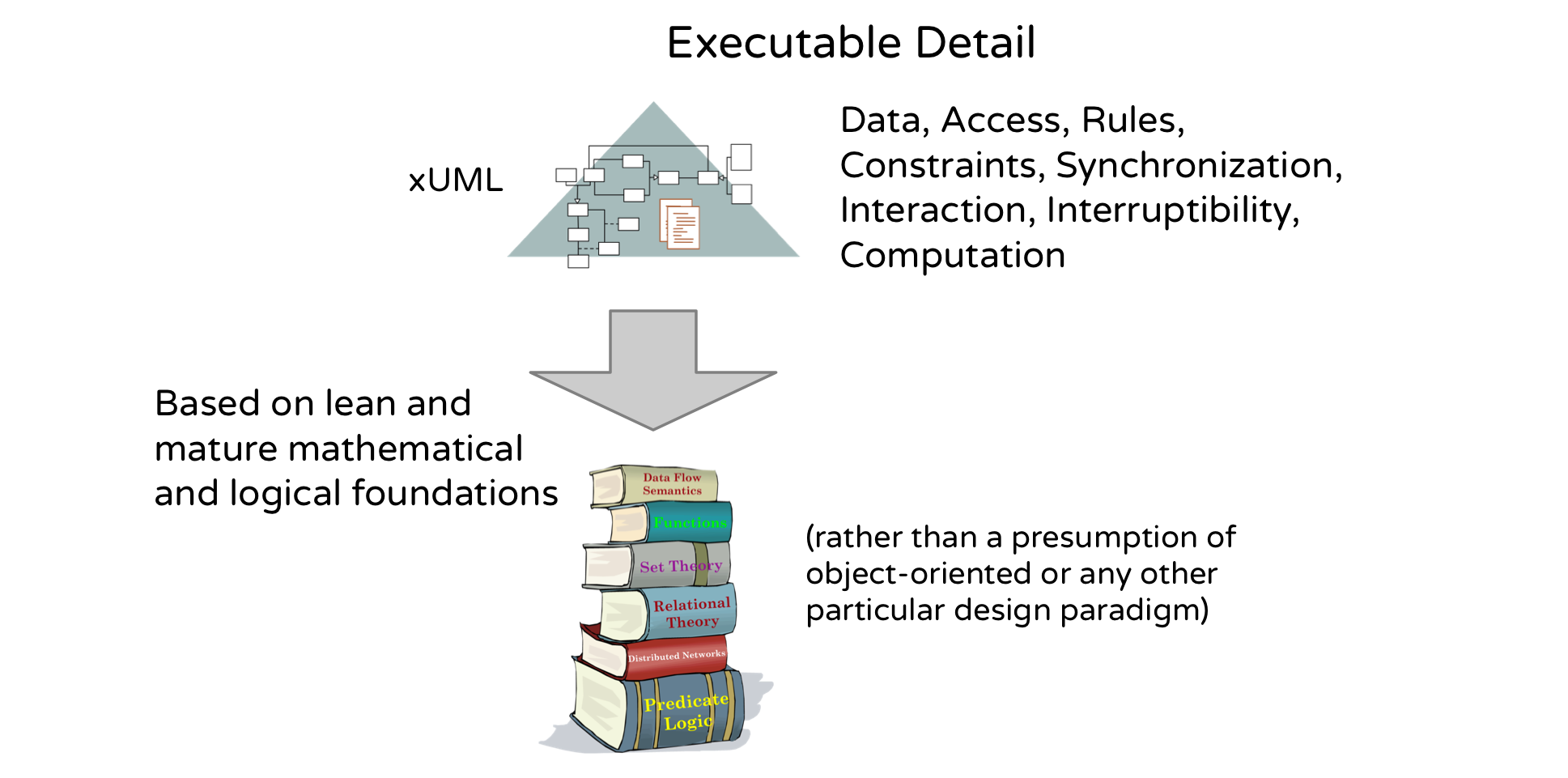
An executable modeling language based on lean mathematical foundations has numerous benefits over one layered over an object-oriented programming bias. Most uses of UML have Java style object oriented programming assumptions subtly and not so subtly baked in. Those assumptions can impose severe limitations if you are delivering software on a resource starved embedded system. They also shackle developers who may want to employ a different programming paradigm. The modeling language shouldn’t dictate how you write code. Nor should it limit the modelers by adding unnecessary complexity to the language. The Executable UML I will be demonstrating does more with less. Less notation, less rules, less impositions on the programmer/code generator.
This is yet another thing that we’ll revisit as we work our way through the upcoming installments.
An executable modeling language based on lean mathematical foundations has numerous benefits over one layered over an object-oriented programming bias Click To TweetThe xUML process
Here is a brief list of the steps we must take to develop a complete set of xUML models.
- Analyze the requirements (in whatever form they exist)
- Organize the entire project into modeled and non-modeled domains (independent execution units), then, for each domain we choose to model in xUML:
- Build the class model
- Build the state models
- Write the action language
- Translate the xUML models into code (with model level debugging support) linked or otherwise interfaced with non-xUML code
- Test the code with a model level debugger
This is just an overview of the engineering process and quite a few critical activities are encompassed in each item. We will, in fact, perform various degrees of execution and testing in steps 4, 5 and 6. Also, in reality, we don’t proceed forward in a nice neat line. It is common, for example in step 5 and 6 to realize that there are deficiencies from step 4 that need to be fixed. Nonetheless, we proceed in this primary order for reasons to be revealed as we tackle each step.
Development of separate domains may proceed roughly in parallel. So you need to imagine these steps running alongside each other for each domain. Domains are factored in such a way, as you will see, that minimize (but doesn’t eliminate) the need for communication between teams. That’s because each domain sees the other as a black box. In xUML, it is the domain, and not the class, that establishes the primary unit of encapsulation and re-use (I will define precisely what I mean by “domain” in the context of Executable UML in the next installment and just leave you with ‘black box of modeling stuff’ for the moment).
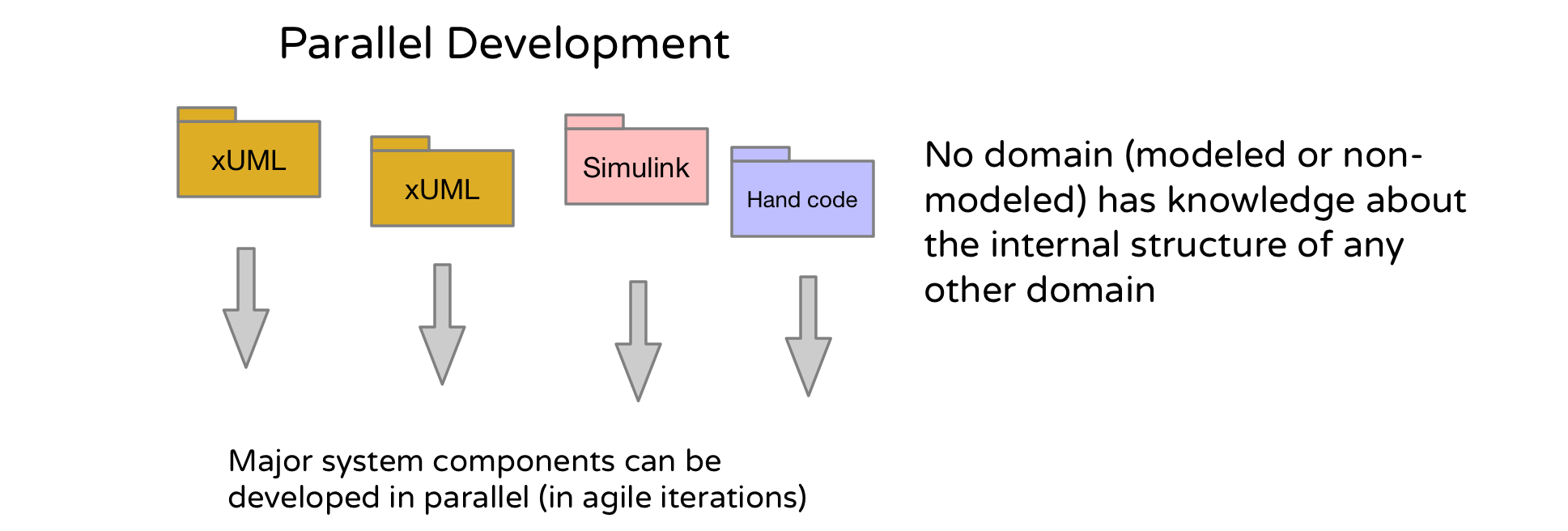
As we proceed through each step, I will explain the rationale for doing that step in the specified order and the negative consequences of proceeding otherwise.
Executable models can, and should be, developed in an agile manner Click To TweetAgile developers (executable models can, and should be, developed in an agile manner) will cycle through all seven steps as a unit of iteration. Depending on your resources and degree of modeling expertise and project constraints, you will size those increments as appropriate.
Ok, enough ambling preamble, let’s get started with step 1!
Analyze the requirements
Our goal is to create models that demonstrate behavior consistent with the provided requirements. In this sense the models express requirements, but they are not the source of the requirements themselves.
On real projects, requirements are expressed on a spectrum anywhere from highly detailed documents typical of military and medical systems to extremely fuzzy stories extracted, with difficulty, from the minds of product visionaries. As an xUML modeler, you will typically have a lot of work to do before you build your first model. I have written extensively about this in my book Executable UML: How to Build Class Models and I hope to write more about this in an upcoming book.
Requirements analysis is serious business requiring interviews with subject matter experts, extensive reading and reorganization of source materials to find useful patterns often hidden in the data. Project to project, I have found that most programmers suck at this task. It’s no surprise since requirements analysis skills lean heavily on communication, asking questions, presentations, taking careful notes, documentation, etc. If you’ve signed up to be a programmer, you probably did so because you hate doing that stuff and that’s okay. When I go into programming mode, as my wife will tell you, my communication and skills rapidly deteriorate.
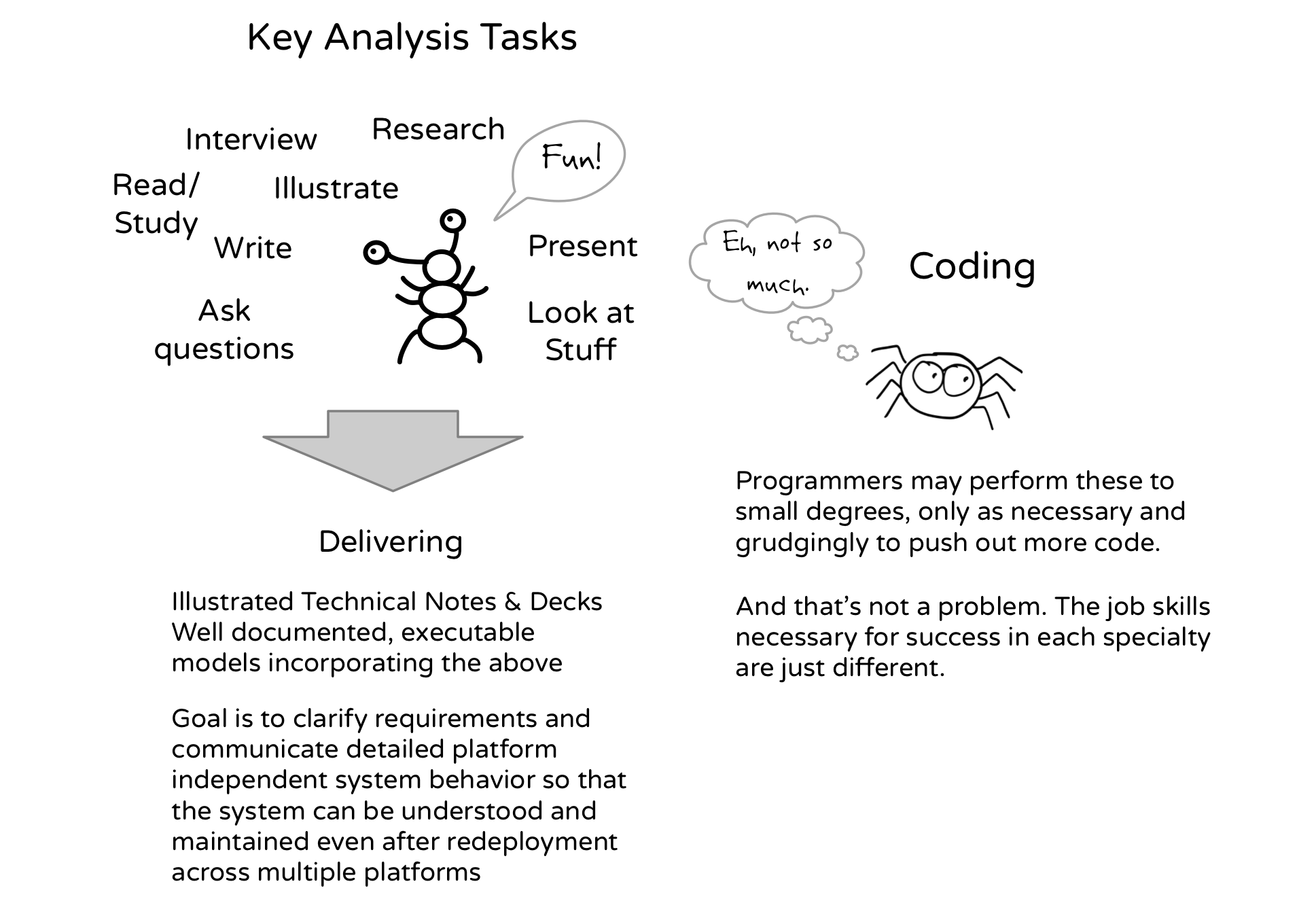
It definitely pays off to spend some time studying the requirements, background materials, existing systems/code and interviewing subject matter experts. Once you get a rough sense of the system, it is often best to dive into modeling stages 2 and 3 (in that order) as both of these steps can be infinitely more productive at exposing issues than less formal activities.
For this case study, I will give you a fairly light treatment on the requirements with an eye toward using the early modeling stages to drive clarity. Here is a link to the requirements, such as they are. As you can see they are neither military or medical grade, but better than nothing and adequate to begin the modeling process. Browse through them, ponder a bit and we will analyze them and move on to step 2 in the next installment.
I help agile software teams succeed with requirements analysis, domain definition, platform independent, executable modeling and high quality code generation. Other websites: executableuml.org, modelstocode.com


Leon,
Love your article! May I suggest that you reference Software Requirements 3E by Wiegers & Beatty as a very useful source that covers many different aspects of ‘requirements’ in significant detail. There’s even a nice relatively succinct but well explained chapter on Agile Projects. Like you (I think), I have spent a good deal of my professional life dealing with requirements (from interpreting, to eliciting, to translating etc.). I have found Wiegers & Beatty both a great introduction to the topic and a go-to for ideas when I’m not sure what to do next!
Thanks, Clive. I’ll check it out. And thanks for reading! / Leon