
After the release of powerful Large Language Models (LLM) such as Copilot and ChatGPT, many of us were wondering whether indeed they are good at, not only coding, but modeling. There seem to be a good number of engineers believing that LLM came to stay and that they are going to revolutionize the way in which software is developed, but: Up to what extend can LLMs be used today to model software systems? While there are many papers devoted to analyzing the potential advantages and limitations of these generative AI models for writing code, the analysis of the current state of LLMs with respect to software modeling has received little attention so far.
In a recent paper [1] published open access in the Software and Systems Modeling journal, we have investigated the current capabilities of ChatGPT to perform modeling tasks and to assist modelers, while also trying to identify its main shortcomings.
TLDR: Our findings show that, in contrast to code generation, the performance of the current version of ChatGPT for software modeling is limited, with various syntactic and semantic deficiencies, lack of consistency in responses, and scalability issues. We believe that we should start working now to improve LLMs for software modeling.
Contents
- Introduction
- Experiments
- Research questions and answers
- RQ1.: Does ChatGPT generate syntactically correct UML models?
- RQ2.: Does ChatGPT generate semantically correct models, i.e., semantically aligned with the user’s intent?
- RQ3.: How sensitive is ChatGPT to the context and to the problem domain?
- RQ4.: How large are the models that ChatGPT is able to generate or handle?
- RQ5.: Which modeling concepts and mechanisms is ChatGPT able to effectively use?
- RQ6.: Does prompt variability impact the correctness/quality of the generated models?
- RQ7.: Do different use strategies (e.g., prompt partitioning) result in different outcomes?
- RQ8.: How sensitive is ChatGPT to the UML notation used to represent the output models?
- Discussion and Conclusions
- References
Introduction
Most experts foresee a major disruption in the way software is developed and software engineering education is also expected to drastically change with the advent of LLMs. These issues are a recurrent topic in many universities and are being covered by most specialized forums and blogs. A plethora of papers are now analyzing the potential advantages, limitations and failures of these models for writing code, as well as how programmers interact with them. Most studies seem to agree that LLMs do an excellent job in writing code: despite some minor syntactical errors, what they produce is essentially correct.
However, what about software modeling? What is the situation of LLMs when it comes to performing modeling tasks or assisting modelers to accomplish them? A few months ago, together with my colleagues Javier Cámara, Javier Troya and Antonio Vallecillo, we started looking at these issues, trying to investigate the current status of LLMs with respect to conceptual modeling. Our premise is that LLMs are here to stay. So, instead of ignoring them or rejecting their use, we posit that it would be better to embrace and use them in an effective manner to help us perform modeling tasks.
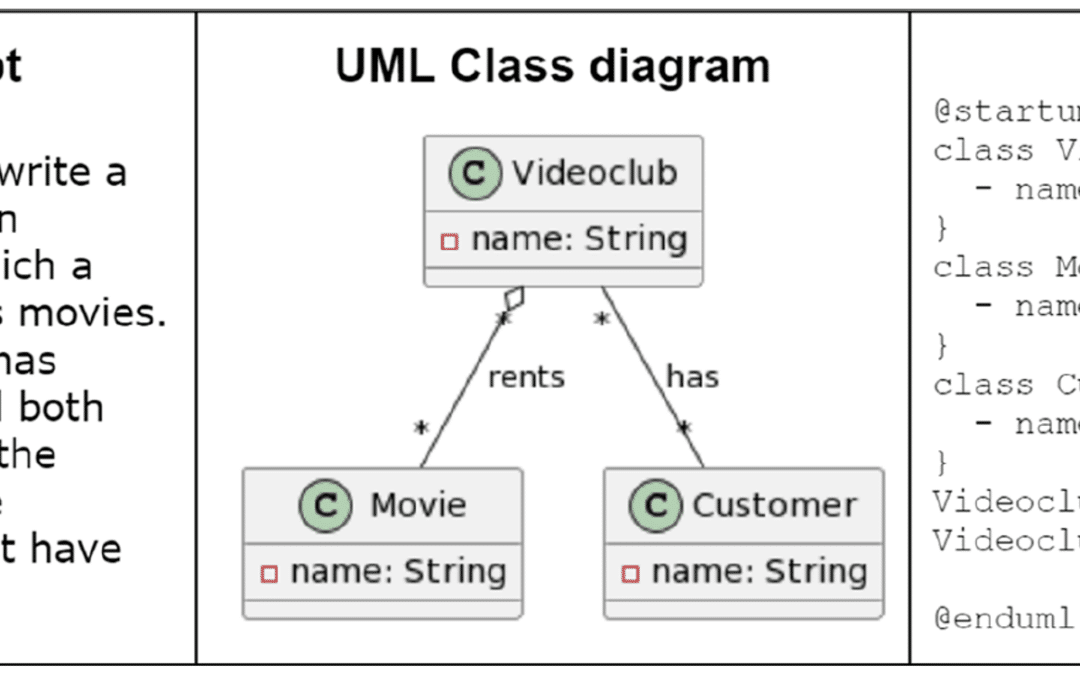
In our paper [1], we focused on how to build UML class diagrams enriched with OCL constraints using ChatGPT. To do so, we investigate several issues, such as:
- the correctness of the produced models;
- the best way to ask ChatGPT to build correct and complete software models;
- its coverage of different modeling concepts and mechanisms;
- its expressiveness and cross-modeling language translation capabilities; and
- its sensitivity to context and problem domains.
Experiments
We conducted an experiment to understand the current capabilities of ChatGPT to perform modeling tasks. We defined two phases: (1) some exploratory tests to gain a basic understanding of how ChatGPT works with software models, as well as its main features and limitations; and (2) more systematic tests that aimed to further characterize ChatGPT’s modeling capabilities. All the details of the experiments, the materials and examples, and all our findings are listed in our paper.
We formulated eight research questions for which we wanted to find an answer. These are presented in the following.
Research questions and answers
RQ1.: Does ChatGPT generate syntactically correct UML models?
The UML models produced by ChatGPT are generally correct, although they may contain small syntactic errors, which depend on the notation used (PlantUML, USE, plain text, etc.). Although we did not test it thoroughly, the level of syntactic correctness of the models produced in PlantUML was much higher than those generated in USE, for example.
RQ2.: Does ChatGPT generate semantically correct models, i.e., semantically aligned with the user’s intent?
This is the weakest point that we observed during our interaction with ChatGPT. Some studies suggest that LLMs are better at syntax than producing semantically correct results, and our findings corroborate this fact. This includes errors in both the semantics of the language and the semantics of the domain being modeled. On many occasions, we observed that ChatGPT proposed seemingly random models that made no sense from either a modeling or domain standpoint.
RQ3.: How sensitive is ChatGPT to the context and to the problem domain?
Our findings show that not only the problem domain influences the resulting models, but also the information exchanged during the dialogues with ChatGPT. In addition, the more ChatGPT “knows” about a domain (i.e., the more data about a domain was used during training), the closer-to-correct class models it produces. ChatGPT produces its worst results when it has little or no information about the domain or the entities to be modeled, as it happened when asked to produce software models of entities such as Snarks or Zumbats, for which it did not seem to have any reference or semantic anchor.
RQ4.: How large are the models that ChatGPT is able to generate or handle?
ChatGPT currently has strict limitations on the size of the models it can handle. It has serious problems with models larger than 10–12 classes. Even the time and effort required to produce smaller models are not insignificant.
RQ5.: Which modeling concepts and mechanisms is ChatGPT able to effectively use?
We analized 16 modeling concepts. Some of them as simple as classes and attributes, and some of them more advanced such as OCL constraints and or association classes. We observed there is a high degree of variability in how ChatGPT handles them. ChatGPT is able to manage reasonably well (with some exceptions) associations, aggregations and compositions, simple inheritance and role names of association ends. However, it requires explicit indications for using enumerations, multiple inheritance and integrity constraints. Finally, we found out that its results are not acceptable when using abstraction, and it cannot handle association classes.
RQ6.: Does prompt variability impact the correctness/quality of the generated models?
We observed that there is plenty of variability when ChatGPT generates responses to same prompt. We learned that it is useful to start a new conversation from scratch when the results were not good, in order to find better solutions for the same intent model.
RQ7.: Do different use strategies (e.g., prompt partitioning) result in different outcomes?
First, the size of the models that ChatGPT is capable of handling in a single query forces the modeling task to become an iterative process in which the user starts with a small model and progressively adds details to it. The variability and randomness of ChatGPT responses or when results within a conversation start to diverge often force the modeler to repeat conversations to try to obtain better models.
RQ8.: How sensitive is ChatGPT to the UML notation used to represent the output models?
ChatGPT is capable of representing models with several notations, although in general it makes fewer syntactic mistakes with PlantUML. It is also much better with OCL than with UML. Finally, we also looked at how accurate ChatGPT was with cross-modeling language translation, realizing that this task works better within the same conversation, but not across conversations.
Discussion and Conclusions
From our study, we conclude that ChatGPT is not yet a reliable tool to perform modeling tasks. Does that mean we should discard it, or at least wait to see how it evolves before taking any action? Our position is that, on the contrary, we should start working now to strengthen the modeling skills of ChatGPT and other LLMs to come (including also their capabilities regarding the LLM understanding of other languages beyond UML), and to build a future where these assistants are destined to play a prominent role in modeling.
In our opinion, ChatGPT or any other LLM can be of invaluable help in many areas of MBSE, complementing the current work of software modelers and letting them focus on the tasks for which they really provide value.
The use of large language models has the potential to revolutionize software modeling engineering and education, making it more accessible, personalized and efficient. To get to that point, we will first need to improve the current consistency and reliability of the models produced by LLMs such as ChatGPT. Second, we will need to change the way in which we currently develop software models and teach modeling.
We encourage you to read out paper for more details and contact us if you would like to discuss!
References
[1] Javier Cámara, Javier Troya, Lola Burgueño, Antonio Vallecillo. On the assessment of generative AI in modeling tasks: an experience report with ChatGPT and UML. Softw Syst Model (2023). DOI: 10.1007/s10270-023-01105-5
Lola Burgueño is an Associate Professor at the University of Malaga (UMA), Spain. She is a member of the Atenea Research Group and part of the Institute of Technology and Software Engineering (ITIS). Her research interests focus mainly on the fields of Software Engineering (SE) and of Model-Driven Software Engineering (MDE). She has made contributions to the application of artificial intelligence techniques to improve software development processes and tools; uncertainty management during the software design phase; model-based software testing, and the design of algorithms and tools for improving the performance of model transformations, among others.


We have been working on this topic for one month now, at FHOSTER, trying to implement a conversational interface to the modeling environment of Livebase, our model-driven GraphQL service generation platform. I almost totally agree on the results reported on of this paper, with one notable exception: in our experience it’s very hard to make ChatGPT create PlantUML models with specific role names at the ends of associations.
Morover, trying to create models with multiple associations between a given pair of classes most of the times ends up in incorrect models. For instance, we told ChatGPT that we wanted to manage cars and persons, and track for each car its owner of the drivers allowed to drive it. No matter how carefully we provided such specifications, many times ChatGPT created four classes (Car, Person, Owner and Driver) and two relationships Car-Owner and Car-Driver. Whem we clarified that owners and drivers are actually persons, ChatGPT sometimes created a generalization, which would have been acceptable if owners and drivers had different attributes (which was not the case).
Thanks for your input, Antonio. We faced similar situations, too, in which no matter what we tried, the model was not the one we were expecting. There is still a lot of room for improvement.