

The increased adoption of model-driven engineering comes together with a proliferation of new model-based courses and programs in computer science and engineering schools in order to respond to the needs and demands of students and industry.
Unfortunately, in modeling courses, as in any other kind of course, plagiarism is an issue. Most of the existing MDE courses include assignments where students are required to build modeling artifacts. In many cases (up to 76% of the courses), these assignments are the only means to evaluate the students. Therefore a fair assessment of these artifacts is key for proper student evaluation. As such, plagiarism in modeling courses is particularly serious.
Even if modeling and, especially, full-fledged MDE, is a somehow recent field, there are already a number of large courses, repositories and solved exercises online that could be used for plagiarism. Having a good plagiarism tool for modeling assignments would not only help to detect these issues but also act as deterrent, making the students less prone to incur in plagiarism, and thus, improve academic integrity.
We believe that in order to effectively asses the outcomes of model-driven programs, plagiarism detection must be integrated into the toolset and activities of instructors.
Unfortunately, while ready-to-use plagiarism detection mechanisms exist for textual documents, there is nothing really useful for plagiarism detection on modeling artefacts. Approaches proposed for classical computer programming language assignments, while specially designed to deal with academic assignments (e.g., they can deal with artefacts that are smaller than their real-life counterpart and often more similar among them), are not directly usable at the modeling level, where we need specific comparison mechanisms. The few MDE-specific approaches available typically require pairwise comparison of models, too computationally expensive.
To address these issues, we provide in this paper an efficient mechanism for the detection of plagiarism in repositories of modeling assignments based on an adaptation of the Locality Sensitive Hashing (LSH) technique to the modeling technical space. LSH is an approximate nearest neighbor search mechanism successfully used for clustering. Effectively, using LSH over a (model) repository results in its classification (without the use of pairwise comparisons) in a set of buckets which basically constitute a set of similarity-based (modeling) clusters.
We demonstrate the feasibility of our approach by evaluating our prototype on a real use case consisting of two repositories containing 10 years of student answers to MDE course assignments corresponding to lessons related to modeling (and metamodeling) and model transformation taught between 2007 and 2017. As a result, we have found that:
- As expected, plagiarism occurred on the aforementioned course assignments and
- Our tool was able to efficiently detect them, and thus, may be used by instructors to asses the outcomes of their courses.
You can find all the details of this work in the paper Salvador Martínez, Manuel Wimmer & Jordi Cabot (2020). Efficient plagiarism detection for software modeling assignments, Computer Science Education, DOI: 10.1080/08993408.2020.1711495 (author copy if you face a paywall with the previous link: PlagiarismDectectionForMDE).
A short overview of the method follows. The first step of our approach (see next figure) is to transform complex models into an easier to manage representation that enables the use of LSH techniques. The key requirement of this new representation is to ensure that it preserves the similarity of the models. The more similar the original models are, the more similar this derived representation must be. Robust hashing functions meet this requirement, as described in detail in our previous work on robust hashing for models. We then use Locality Sensitive Hashing to classify the model (represented by their vectors) into buckets containing similar models, without having to go through the very computationally expensive pairwise model comparison process. Our banding strategy makes similar robust hash vectors pairs much more likely to be hashed to the same bucket than dissimilar pairs. Pairs of models that show several collisions (different parts of their respective hashes end up in the same band), we have a strong plagiarism candidate. The final decision is up to the teacher that can now focus on deeply examining these few colliding candidates instead of the full set of assignments.
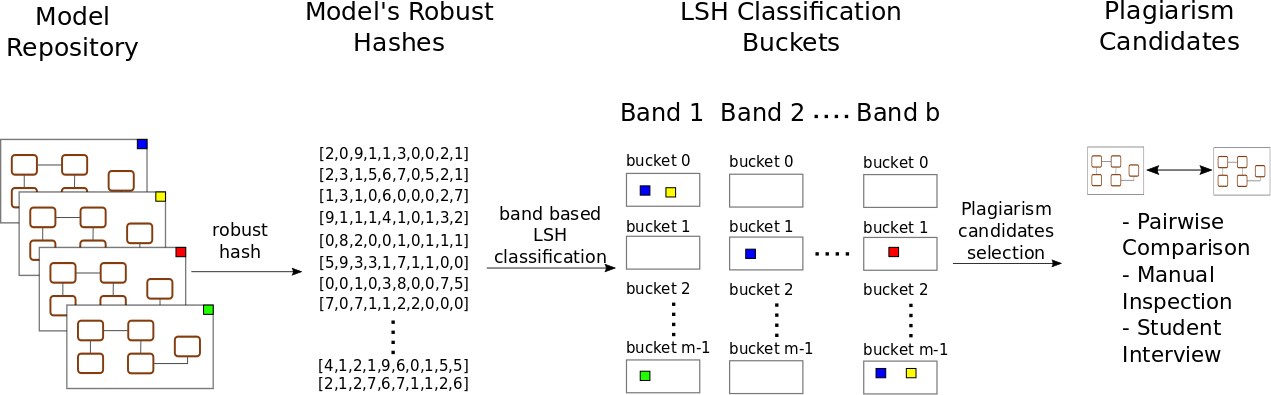
Steps of our plagiarism detection approach for software models
Featured image thanks to mimiandeunice
Salvador Martínez Pérez currently works at CEA-List lab (Paris) in collaboration with the SOM Research lab (Barcelona). Salvador does research in Computer Security, Reliability, Software Engineering, Software Evolution and core Model-driven engineering. Their current project is ‘Model-based Reverse Engineering.’


Recent Comments