
Model Transformation (MT) is a key concept in MDE’s success. MT languages have been designed to help users specifying and executing model-graph manipulation operations. The AtlanMod Transformation Language (ATL) is one of the most popular examples among them, and a plethora of transformations exist addressing different model types and intention.
Why distributing model transformations?
In the past few years, MDE has been recently facing the growing complexity of data and systems, that comes in MDE in the form of Very Large Models (VLMs). For example, the Building Information Modeling language (BIM) contains a rich set of concepts (more than eight hundred) for modeling different aspects of physical facilities and infrastructures, and a building model in BIM is typically made of several gigabytes. Consequently, existing MDE tools, including MT engines, are based on graph matching and traversing techniques that are facing serious scalability issues in terms of memory occupancy and execution time. This stands especially when MT execution is limited by the resources of a single machine.
One way to overcome these issues is exploiting distributed systems for parallelizing model manipulation (processing) operations over computer clusters. This is made convenient by the recent wide availability of distributed clusters in the Cloud. MDE developers may already build distributed model transformations by using a general-purpose language and one of the popular distributed programming models such as MapReduce. However such development is not trivial. Distributed programming (i) requires familiarity with concurrency theory that is not common among MDE application developers, (ii) introduces a completely new class of errors w.r.t. sequential programming, linked to task synchronization and shared data access, (iii) entails complex analysis for performance optimization.
Meet ATL – MapReduce
ATL-MR offers an implicit distribution, i.e. the syntax of the ATL is not modified and no primitive for distribution is added. Hence, no familiarity with distributed programming is required. Thanks to the semantics alignment of ATL and MapReduce.
MapReduce is a programming model and software framework developed at Google in 2004. MapReduce is inspired by the map and reduce primitives that exist in functional languages. Both Map and Reduce invocations are distributed across cluster nodes, thanks to the Master that orchestrates jobs assignment. Input data is partitioned into a set of chunks called Splits. Every split comprises a set of logical Records, each containing a pair of <key, value>.
Given the number of Splits and idle nodes, the Master node decides the number of workers (slave machines) for the assignment of Map jobs. Each Map worker reads one or many Splits, iterates over the Records, processes the <key, value> pairs and stores locally the intermediate <key, value>pairs. In the meanwhile, the Master receives periodically the location of these pairs. When Map workers finish, the Master forwards these locations to the Reduce workers that sort them so that all occurrences of the same key are grouped together. The mapper then passes the key and list of values to the user-defined reduce function for processing. I recommend readers not so familiar with ATL or MapReduce to check them up.
In the remaining of the post, we refer to a single case study related to the analysis of data-flows in Java programs. The case study is well-known in the MDE community, being proposed by the Transformation Tool Contest (TTC) 2013. We focus on one phase of the scenario, the transformation of the control-flow diagram of a Java program into a data-flow diagram. Such task would be typically found in real-world model-driven applications on program analysis and reverse engineering of legacy code.
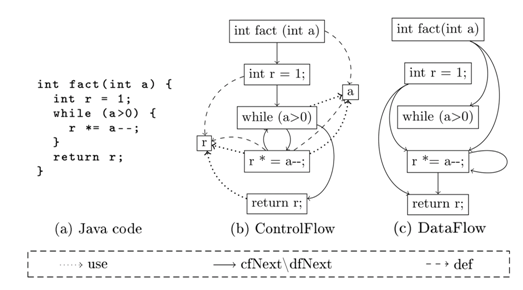
Figure above shows an example of models, derived from a small program calculating a number factorial. Instructions are represented by rectangles, and variables by squares. An instruction points to the set of variables it defines or writes (def), and a set of variables it reads (use). The links ‘cfNext’ and ‘dfNext’ refer to the next control flow and data flow instructions respectively. As it can be seen in the figure, the transformation changes the topology of the model graph. Source of the transformation can be found in the tool website.
Our ATL-MR transformation engine follows a data-distribution scheme, where each one of the nodes that are computing in parallel takes charge of transforming a part of the input model. Its source code is available at the paper’s web-site. The engine is built on top of the ATL Virtual Machine (EMFTVM) and Apache Hadoop.
Figure below shows how the ATL transformation of our running example is executed on top of three nodes, two map and one reduce workers.
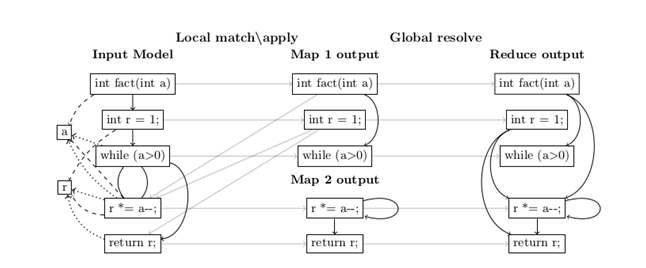
- Map Phase: The input model is equally split over map workers. In the map phase, each worker runs independently the full transformation code but applies it only to the assigned subset of the input model. We call this phase Local match-apply. Afterwards each map worker communicates the set of model elements it created to the reduce phase, together with trace information. These trace links encode the additional information that will be needed to resolve the binding, i.e. identify the exact target element that has to be referenced based on the tracing information.
- Reduce Phase: the reduce worker is responsible for gathering partial models and trace links from the map workers, and updating properties value of unresolved bindings. We call this phase Global resolve. Each node in the system executes its own instance of the ATL VM but performs either only the local match-apply or the global resolve phase. The standalone and distributed ATL engines share most of the code and allow for a fair comparison of the distribution speedup. Further explanation can be found in the paper.
How does ATL – MR perform?
We experimentally evaluate the scalability of our approach by conducting two different but complementary experiments. We run our experiments in our running example and compare how it performs in two different test environments (clusters). The transformation covers a sufficient set of declarative ATL constructs enabling the specification of a large group of MTs. We use as input different sets of models of various sizes, reverse-engineered from a set of automatically generated Java programs. While The first one shows a quasi-linear speed-up w.r.t. the cluster size for input models with similar size, the second one illustrates that the speed-up grows with increasing model size.
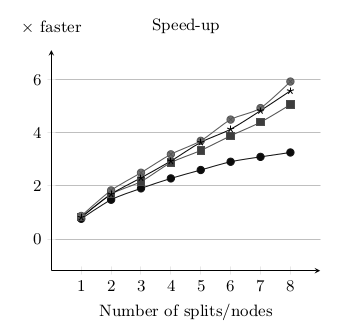
For the first experiment, we have used a set of 5 automatically generated Java programs with random structure but similar size and complexity. The source Java files range from 1 442 to 1 533 lines of code and the execution time of their sequential transformation ranges from 620s to 778s. The experiments were run on a set of identical Elastic MapReduce clusters provided by Amazon Web Services. All the clusters were composed by 10 EC2 instances of type m1.large. Each execution of the transformation was launched in one of those clusters with a fixed number of nodes – from 1 to 8 – depending on the experiment. Each experiment has been executed 10 times for each model and number of nodes. In total 400 experiments have been executed summing up a total of 280 hours of computation (1 120 normalized instance hours). For each execution, we calculate the distribution speed-up with respect to the same transformation on standard ATL running in a single node of the cluster. Next figure summarizes the speed-up results.
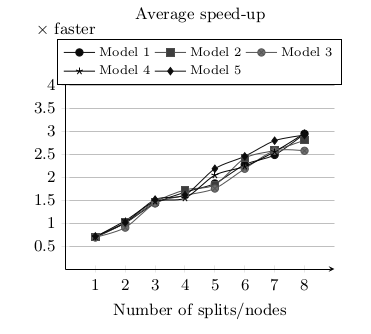
To investigate the correlation between model size and speed-up we execute the transformation over 4 artificially generated Java programs with identical structure but different size (from 13 500 to 105 000 lines of code). Specifically, these java programs are built by replicating the same imperative code pattern and they produce a balanced execution of the model transformation in the nodes of the cluster. This way, we abstract from possible load unbalance that would hamper the correlation assessment. This time the experiments have been executed in a virtual cluster composed by 12 instances built on top of OpenVZ containers running Hadoop 2.5.1.
As shown in the next figure, the curves produced by Experiment II are consistent with the results obtained from Experiment I, despite the different model sizes and cluster architectures. Moreover, as expected, larger models produce higher speed-ups: for longer transformations the parallelization benefits of longer map tasks overtakes the overhead of the MapReduce framework.
I want to read more about distributing the execution of model-to-model transformations on top of a MapReduce infrastructure
Full details of our approach are available in this paper: Distributing relational model transformation on MapReduce accepted at the Journal of Systems and Software. You can also download the pdf or read first the abstract below.
MDE has been successfully adopted in the production of software for several domains. As the models that need to be handled in MDE grow in scale, it becomes necessary to design scalable algorithms for model transformation (MT) as well as suitable frameworks for storing and retrieving models efficiently. One way to cope with scalability is to exploit the wide availability of distributed clusters in the Cloud for the parallel execution of MT. However, because of the dense interconnectivity of models and the complexity of transformation logic, the efficient use of these solutions in distributed model processing and persistence is not trivial.
This paper exploits the high level of abstraction of an existing relational MT language, ATL, and the semantics of a distributed programming model, MapReduce, to build an ATL engine with implicitly distributed execution. The syntax of the language is not modified and no primitive for distribution is added. Efficient distribution of model elements is achieved thanks to a distributed persistence layer, specifically designed for relational MT. We demonstrate the effectiveness of our approach by making an implementation of our solution publicly available and using it to experimentally measure the speed-up of the transformation system while scaling to larger models and clusters.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


To use side effect free by design languages has advantages.
Really nice work, desperately waiting for industrial strength tools providing parallelized model transformations.
Many, many thanks,
Carsten