
Data is the new code
With the rise of machine learning technologies, the need for more and better datasets is becoming one of the main challenges in the industry. Relevant scientists and practitioners, such as Andrew Ng, have proposed the need for a data-centric cultural shift in the machine learning field, where data issues are given the attention they deserve. The idea behind this proposal is simple; Better data to build better machine learning applications.
But data, beyond being the power behind the ML applications, can also be the source of ethical and social issues. For instance, recent studies, such as Khalil et al., show how facial analysis datasets with fewer darker-skinned faces could drop the accuracy of face analysis models in that particular group, representing social harm. As another example, Bender et al. demonstrate how a natural language dataset gathered from Australian speakers can reduce the accuracy of models trained to support users in the United States due to differences in language styles.
In both examples, we see the need to go beyond storing the raw data and also store information about provenance, or high-level analysis, such as the social impact on specific groups.
So, better data description, better machine learning
Answering this situation, recent works in the research community have been pointing out the potential harms and recommending best practices while building datasets (Knowing Machines collects a great set of them). Between the proposed best practices, relevant works such as Datasheets for datasets from Gebru et al., along with others, propose guidelines for documenting datasets. These guidelines aim to mitigate common problems coming from datasets by annotating the provenance of the data and providing ways to measure high-level metrics such as fairness, privacy, or traceability from the data.
Although these proposals are based on general guidelines and natural text that have limitations in terms of usage and design and are difficult for machines to compute. For instance, searching for a dataset with specific constraints in data distribution or provenance relevant to a specific use case will be difficult. Moreover, these limitations make it difficult to prove that an algorithm that uses a model trained with this data complies with the ACM’s Statements on Algorithmic and Transparency (Association for Computing Machinery).
A solution from software engineering (SE4AI)
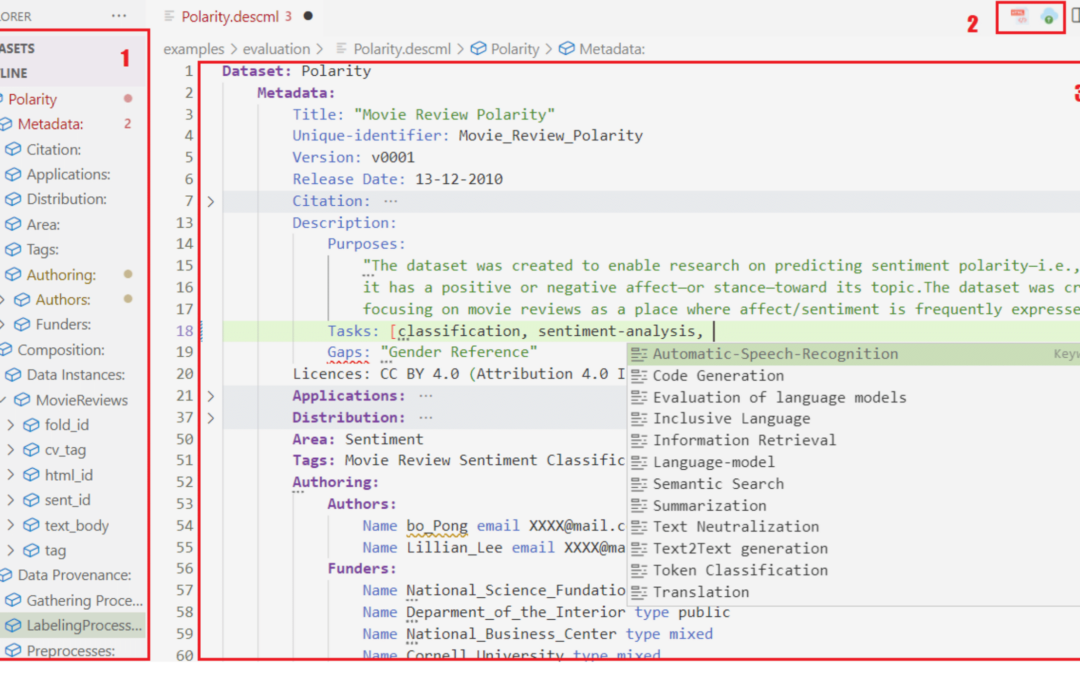
Here comes our proposal; We present DescribeML, a model-driven tool for describing machine learning datasets. The tool, which will be presented at the MODELS 2022 conference, allows data creators to describe the various aspects of the data used to train ML models in a structured manner. The tool, along with the domain-specific language on which it is based (presented here), is intended to aid in the standardization of dataset definition and documentation practices.
The tool walks creators through the dataset description process, providing modern language features like auto-completion, syntactic and semantic highlight, validation, and cross-references. The image below depicts an overview of the domain-specific language (DSL) as a metamodel with the main concepts that can be annotated from a dataset. As we can see, it enables data creators to express information about the data’s uses and authoring, composition, provenance, and social concerns. (For more information, see for a full description of the DSL.)
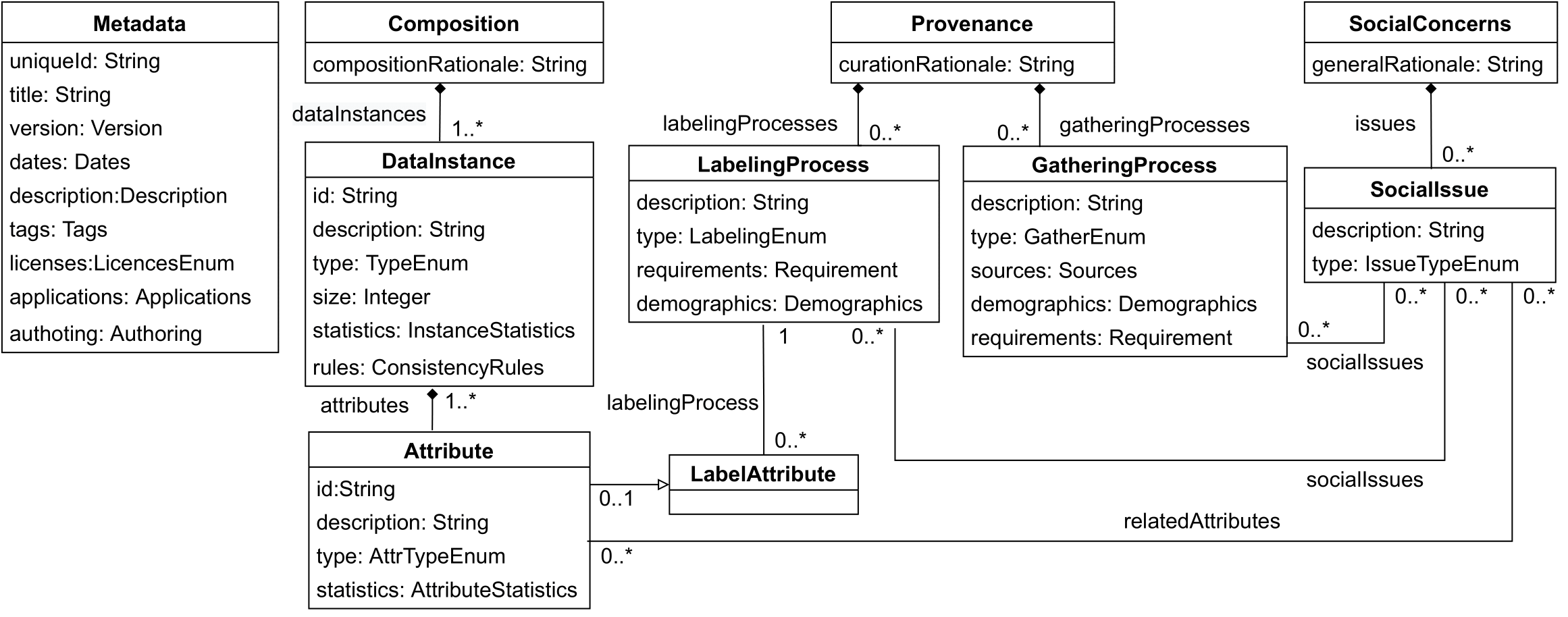
An overview of the DSL for datasets description
But why a structured format is useful? Describing datasets in a structured format opens the door to a set of semi (automated) scenarios. To mention a few:
- Compare datasets targeting the same domain to highlight their differences. For instance, datasets intended for Melanoma detection could be compared based on the type of camera used to capture the images, the expertise of the personnel who take or annotate the images, skin color balance, genre balance, and so on. (Take, for example, one of the most well-known Kaggle competitions.)
- Search for the best dataset based on the needs of the ML projects, beginning with what could become a dataset marketplace in the future. Following the example of the NLP dataset of Australian speakers, we may require a natural language dataset collected or annotated in a specific demographic to match the language style of our potential users.
- Generate other artifacts from a valid dataset description such as documentation, bill of material (BOM) for traceability, test suites, fairness reports etc.
- Facilitate the replication of ML research results by better mimicking the conditions of the datasets used in the experiment when the same ones are unavailable. This is a common case in healthcare, where data usually has substantial privacy restrictions, and the publication of specific data documentation could help other researchers replicate the experiments.
Ok! Let’s see the tool
The tool is developed as a Visual Studio Code plugin, open-sourced here, and published in the Visual Studio Code Market as a plugin extension. The tool is developed using Langium, a language engineering toolkit intended to create DSL based on TypeScript. The tool consists of a DSL grammar implementation and a set of extension services that extend the IDE’s capabilities.
As a result, in addition to the common language features, the tool includes a data loader service that allows data creators to upload their data, extract insights from it, and generate a semi-completed documentation file. When a description file is valid, the tool allows creators to generate HTML documentation using schema.org, the notation used by Google dataset search to index datasets.
A short video presenting the tool can be seen here:
Do you have an interest in our work? Do you want to learn more or work together? We would appreciate hearing from you by leaving a comment on this article or sending an email to [email protected].

Joan Giner is a PhD student based in Barcelona. He is a software engineer specialized in web design and content strategy using content management systems.


Recent Comments