
Model Transformations are model manipulation operations that produce one or more target models from one or more source ones. There is a varied set of approaches and tools (e.g., ATL-based or even AI-based) used for the specification of different types of model transformation. Most of these approaches adopt as a strategy the local and sequential execution of the model transformation. This doesn’t work when we need to transform models with millions of elements. Big models or VLMs (Very Large Models) are present in application domains such as the automotive industry, modernization of legacy systems, the internet of things, social networks, and others.
Overview of Model Transformations in Dc4MT
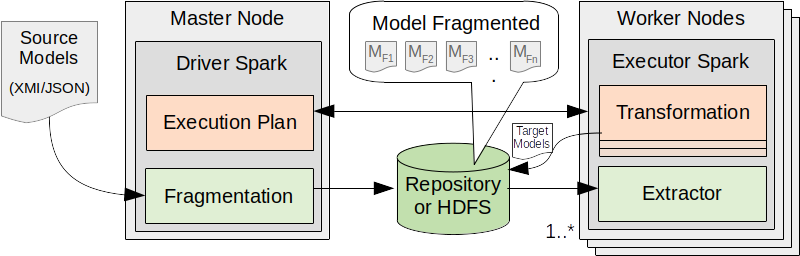
In this context, Dc4MT is proposed as an approach that supports the transformation of large models, applying and adapting data distribution techniques. This approach was inspired by works such as A Linda-based platform for the parallel execution of out-place model transformations (Lintra), Distributing relational model transformation on MapReduce (ATL-MR), and other approaches focusing on the scalability of model transformations. Dc4MT is a Data-centric (Dc) approach to Model-Driven Engineering (MDE). The approach is specified using a distributed processing framework, and it defines a set of operations for fragmentation, extraction, and transformation of models. The steps and activities of the Dc4MT are presented in Figure 2.
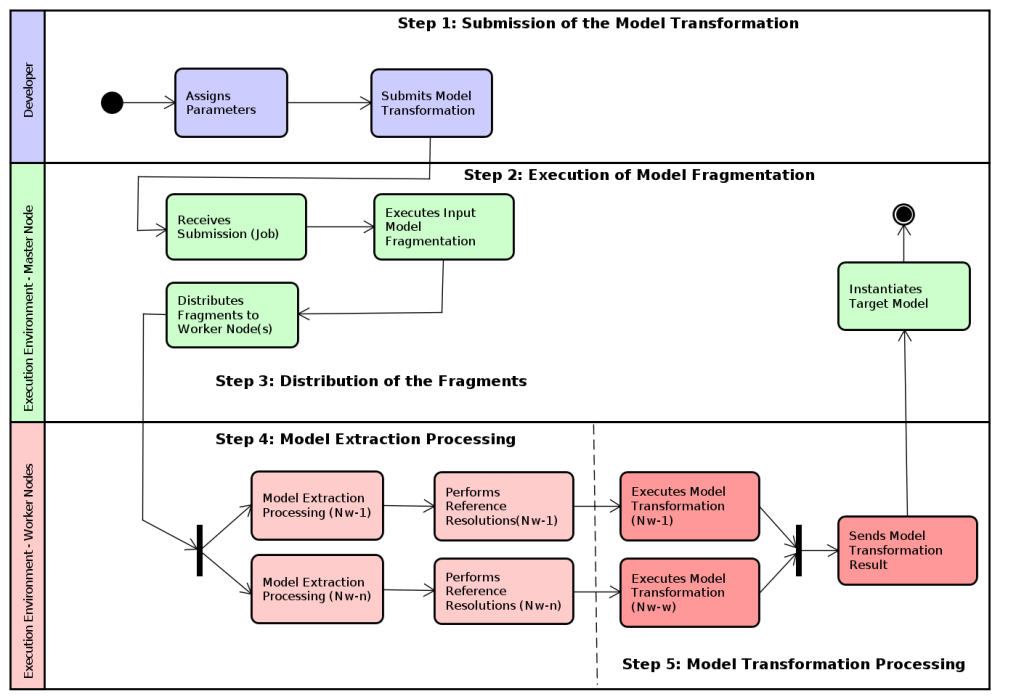
Figure 2: Dc4MT: Steps and Activities
In Step 1, the model transformation is submitted to the execution environment, including the parametrization (i.g., number of nodes, the path of the input model, etc) of the environment. In Step 2, the submission of transformation is received on the Master Node, where the fragmentation of the input model is executed. This means the fragmentation operation splits the input models (in the XMI or JSON formats) in a way that the fragments can be processed in a parallel or distributed fashion. Next, the fragments from the fragmentation operation are distributed to Worker Node(s) (Nw-1,…, Nw-n) by the Master Node in Step 3. The model fragmentation adopted for the Dc4MT includes the disjunction among the model elements. This means that an element does not belong to more than one fragment. In addition to the disjunction, the idea of proxy is used as a reference point between the elements of the same fragment. The top-down fragmentation indicates there are continuations of the model among the fragments, from the root element to the last element of the hierarchy. Figure 3 shows a representation of model fragmentation workflow, where the input model (input_model) contained in the Repository or HDFS is fragmented (i.g., fragment o, 6, 8, …) by the execution of model fragmentation. As each fragment is split, it is stored on the filesystem as a file on a directory (input_model.fragmented). Each fragment file is named as the index of its first element, featured as a proxy (e.g., 0, 6, 8) among the fragments.

Figure 3: Model Fragmentation Workflow
In Step 4, the extraction operation is executed on the Worker Node(s), translating input model fragments to a directed graph (G(V, E)). In the extraction operation, the containment references are preserved in the graph as edges. Non-containment references among input model elements are also resolved. However, the elements that present non-containment references are at first partially solved, where the addresses of these elements (a set of strings) are assigned to the vertices. The resolution of references extracts from these vertices the exact address of each element (strings processing), and preserves the hierarchy of these elements. For this, new vertices and edges are added to the graph. Figure 4 shows a representation of the model extraction designed for the Dc4MT. According to the representation, the root element features two child elements, linked by the edges 0 and 1 respectively. These elements have the A (name=”A”) , and B (name=”B”) attributes. A reference (ref=”/1″) links the A element to the B element, which has the detailOne, and detailTwo as child elements.
During the extraction, every element of the input model is translated into a vertex, containing an id and the name as content. The edge that connects an element to a parent element contains its index (e.g., 0, 1). The element attributes are also converted to vertices of the graph, whose contents is the attribute value (A, B, …). The edge connecting the vertex of an attribute to its element has as its key the attribute name itself (in this case, name). The elements that have references (i. g., “/1”) to another element indicate the target element position in the containment hierarchy, using a path of indexes from the root element.
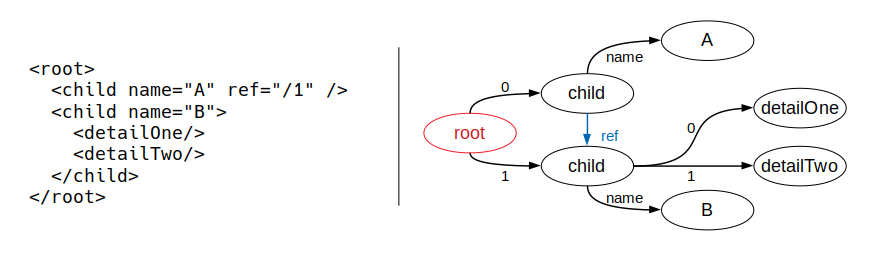
Figure 4: A Representation of the Model Extraction
The Dc4MT operations are built on top of the Apache Spark framework, using Dc aspects such as high-level programming, parallel/distributed environment, and considering that a model element is a set of data. The RDD, DataFrame, and GraphFrames APIs were used in the implementation of the Dc4MT in the Scala language. The source code is at https://github.com/lzcamargo/Dc4MT. Furthermore, the Dc4MT is structured in modules, which may be implemented in different implicit parallelism platforms, such as Hadoop, Cloudera, Google BigQuery, and others.
Figure 5, shows a representation of the Family model elements translated to a graph, which is structured as a GraphFrames. Circles and rectangles are used for illustrating the model element structures and their relationships. For example, the vertices and edges marked in red demonstrate the structure of the lastName Sailor element, and the blue ones denote the firstName David element. The relationship of these two elements is marked on the edge, where the src column value is noted in red, and the value of the dst column is noted in blue. The join of these structures (the match between id, src, and dst columns) allows us to identify that David is a son (sons), and belongs to Sailor Family. Thus, the model elements are structured as a GraphFrame so that they can be queried and processed for different purposes.
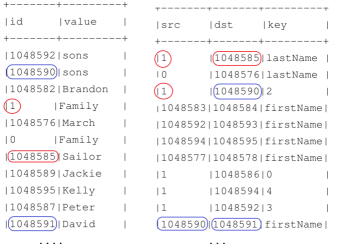
Figure 5:Model Elements Translating to GraphFrames
Last, in Step 5 the model transformation (M2M) is executed on Worker Node(s), transforming input model elements into an output model. The transformation executions can be parallel (local) or distributed. There is the use of filters for selecting the model elements, such that these elements are used in domain transformation rules. The specifications of the filters and rules consider the structures of model elements in a GraphFrames. Figure 6, demonstrates the Family2Person transformation rule written in Scala as a singleton object (object Family2Person). The male and female elements are separated in the maleEdgesDF and femaleEdgesDF DataFrames. They contain the target values (dstm, dstf, dst) that link each last name with their first names. The select, join, and filter functions are used to select the last and first names from maleEdgesDF. For each join operation, the filter function (lines 4, 6, 12, and 14) is used to ensure the accurate selection of model elements. In this case, the selection is performed by the relationships among edges and vertices (“dstm” === “id”). The select and concat functions are used (lines 7 and 15) to assign the full name (lastName and value) to the maleFullNamesDF and femaleFullNamesDF DataFrames.

Figure 6: Family2Person Rule
The main aspects that differ the Dc4MT from the Lintra and ATL-MR approaches:
- the Dc4MT executes M2M transformations, whereas the Lintra approach handles M2M, T2M, and M2T transformations;
- unlike the Lintra, the Dc4MT provides a model fragmentation that allows the parallel processing of model fragments without inserting the model into memory at once;
- Lintra and ATL-MR transform input models in format XMI, and the Dc4MT in XMI and JSON formats;
- in terms of distributed transformations, the Dc4MT and ATL-MR are scalable. Regards model partitioning, ATL-MR uses an algorithm based on a dependency graph for distributing the model fragments among the environment nodes. The Dc4MT uses a fragmentation model, where the model structure itself is used to generates balanced blocks of fragments. These blocks are launch to distributed nodes of the execution environment;
- Dc4MT provides a method for minimizing the data dependency (in this case, the shuffle partitions of Spark framework), during the parallel or distributed executions.
Evaluation of our data-centric approach for Transformations of Models
Performance of Dc4MT was evaluated on parallel (a single machine) and distributed (a cluster of machines) environments. In both, a distinct set of source models (XMI format) were used as experiment. Figure 7, shows an example of a target model as a transformation result. This result is obtained with a merging of the transformation rule outputs in a single data partition.

Figure7: Persons Model Scrap
In the experiment, we executed transformations with and without the partitioning method of data (shuffle partitions). The parallel and distributed executions have an average performance increase of 19% and 17,35%, respectively. The results of the experiments shown that the model fragmentation and extraction operations favor the scalable transformation of models. Moreover, aspects such as immutability, lazy-evaluation, and implicit parallelism present in Dc4MT, allowed the parallel/distributed processing of transformation rules on a scalable platform.
Main Results
The main points of Dc4MT:
- balanced model fragmentation, allowing for parallel/distributed model executions;
- the parallel or distributed model extraction enables the lazy loading of models. The fragment size can be adjusted to the capacity of the processing environment, without the need to load the whole model to main memory at once;
- the strategy of translating input models in XMI or JSON formats to a graph enables these models to become part of a single technical modeling space;
- the implicit method of partitioning data is a way to minimize the data dependency among the processing nodes, during the parallel or distributed model transformation execution.
Improvements
The Dc4MT requires improvements such as:
- inserting of the directives to the model fragmentation, allowing the fragmentation of models in text format, such as pseudo code, source code, and others;
- to broaden the domain of model translation to the graph format, in addition to XMI and JSON. Furthermore, it is possible to enable the model fragmentation for other application domains such as the construction and collaborative manipulation of VLMs;
- to insert M2T and T2M transformations;
- to propose a strategy for graph partitioning (GraphFrames) in memory, minimizing the data dependency during the model processing;
- to insert a layer to the Dc4MT with distributed model persistency.
Conclusion
Model transformations are an arduous task (mostly VLMs), because of the structural complexity of the models and the number of elements to be processed. The Dc4MT approach was proposed based on the MDE and Dc approaches, for the parallel and distributed transformation of models. MDE is a Software Engineering approach used in software development and focused on models, and the Dc is a Data-centric approach, where data is the main element. The Dc4MT was proposed to join the aspects of these heterogeneous approaches for scaling VLM processing. This post is a very short version of a doctoral thesis, which has supervised by Prof. Marcos Didonet Del Fabro, Ph.D.
Professor, Researcher, and have expertise in Software Industry. I have a Master’s and Doctorate in Computer Science.


Recent Comments