
We know very well how to model databases as input/output artefacts in a model-driven development process. We know how to extract their schema, query their data or, conversely, generate the SQL code that will create them. We even know how to do this for NoSQL databases. But nowadays, many companies do NOT acces their data via a database but through a Content-Management System (CMS). In this post, we show how to integrate CMS as input data source in a modeling project.
CMSs power 66,8% of published websites
Content Management Systems (CMSs) (WordPress, Joomla, Drupal) are one of the most popular options to create content across the web. Big retail companies such as Nestle, with thousands of websites, media companies such as Le Figaro or public institutions like The White House use open-source CMSs to power their digital platforms. The content created and stored inside CMS, such as videos, news, podcasts, etc.. represent the key assets for these companies. Therefore, any new software development project in these companies will likely depend on and require these key assets.
This requires to make sure new apps are able to consume the CMS data via the exposed CMS’s API. But this is the ideal scenario. In practice, as the CMS solution becomes more complex, the integration process for new applications becomes much more challenging. Typically, large companies, such as Nestle, must deal with various deployed CMSs, some of them legacy versions, that need to be combined to satisfy the application’s informational needs. Moreover, changes on the CMS data could also affect the already deployed apps.
To facilitate this integration process, in our paper Enabling CMS as an Information source in Model-driven projects, we propose a model-driven approach to automatically discover and consume the information behind a CMS. Our approach helps software designers to abstract from the specific underlying CMS technology by:
- Extracting and representing the model behind a specific CMS installation in UML and
- Generating a ready-to-use middleware library to consume the content.
The paper co-authored by Joan Giner, Abel Gómez, and Jordi Cabot has been published in the International Conference on Research Challenges in Information Science and comes with a prototype of an open-source tool enabling the approach.
Automating the CMS schema discovery and consumption in 3 steps
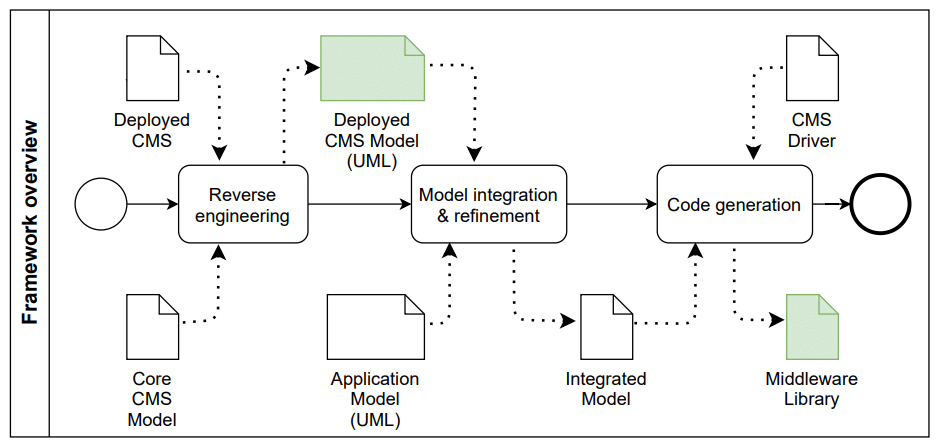
We propose a framework with 3 main steps. As we see in the featured image of the post, the first one is the Reverse engineering step. This step takes as input the target CMS (its URL and user credentials) and imports the basic data to populate the predefined Core CMS model and to extend such model with new custom types defined inside this target CMS. As a result, we get a Deployed CMS model, expressed as a UML class diagram.
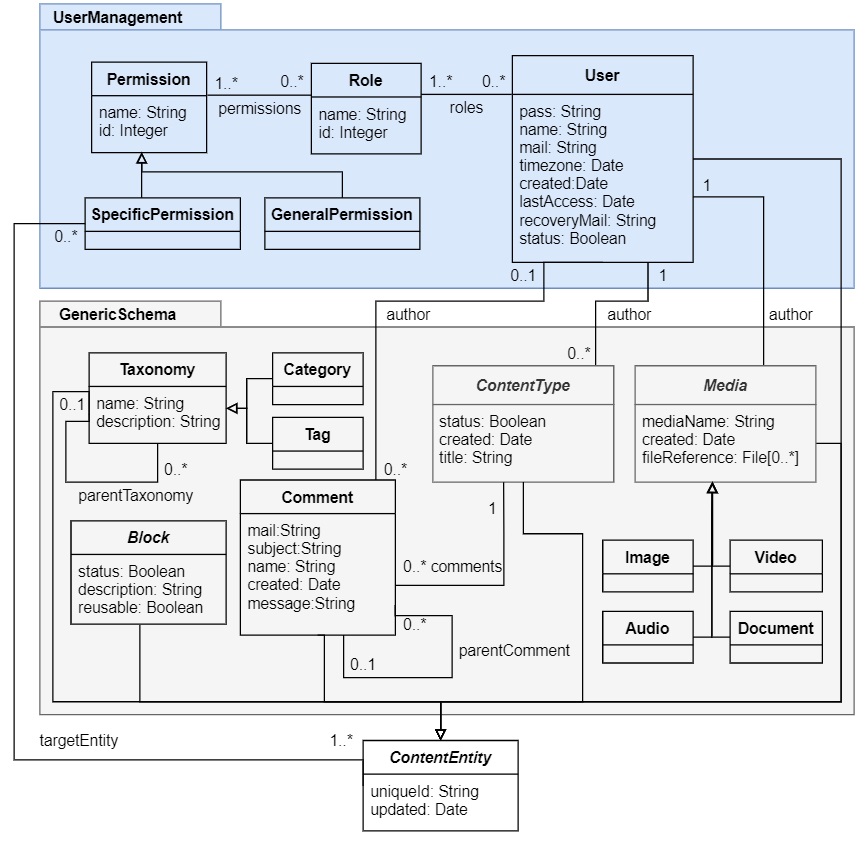
CMS Model to represent the core aspects of a CMS installation
As this obtained model is purely standard, designers can refine it and combine it with other models in the Model integration and refinement step. For instance, we can easily model how a User Interface model (e.g. an IFML one) queries the CMS model to retrieve the information it needs to show to the user in a platform-independent way. Finally, the Code generation takes the integrated model and a CMS driver (a static class tied to a particular CMS technology) and generates a Middleware Library ready to be used by the consumer applications (for instance, a mobile app).
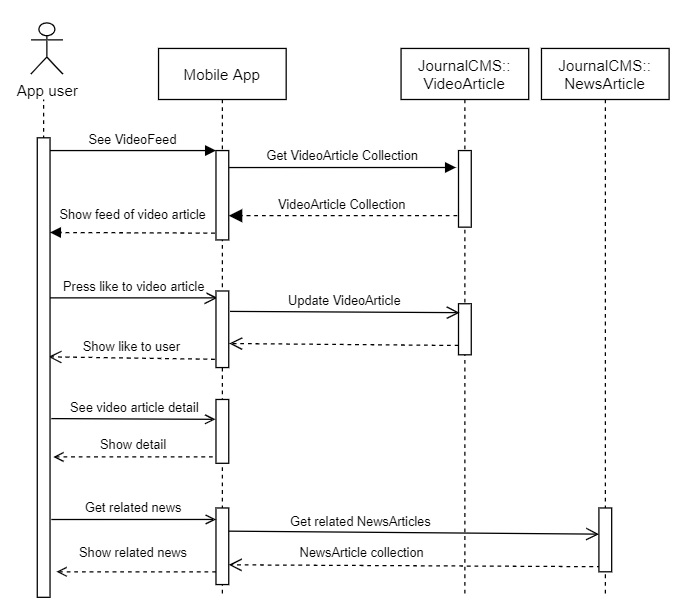
Modeling the interaction of a front-end with a CMS backend. We can then translate these interactions into the actual code that will call the CMS API
Potentials and future work
The integration of CMSs with consumer applications is still a challenging field. Our approach could be used not only for faciliating new project developments but also as pivot infrastructure to be used during the migration from one CMS to another. This migration could be useful, for instance, to advance towards the unification of the technology stack of the companies and reduce the cost derived from it. This unification attempt is much more difficult without an approach like ours that can offer some platform independence persective during the migration.
The Technologic Radar from Thought Works has recently included the Server-driven UI approach, which delivers UI information from the server API, as a technological challenge. This approach allows mobile developers to perform fast UI changes to the application avoiding the typical app store’s round trip to release new versions. As further work, we plan to study how the Reverse Engineering step could consider this server-driven UI approach and purpose methods to the CMS community to expose the UI information in a unified way.
And CMS data is not important only for web-based applications. It is in fact crucial to any data-driven scenario. And one of the most data-driven applications right now is Machine Learning. As such, we would also like to explore the benefits of exposing CMSs data in other domains, like Machine Learning, where easy access to CMS data could help in a better training of ML models. In this context, deploying our framework as a plugin for model-based data science tools like KNIME could be interesting. Finally, at the tool level, we plan to extend our support to other CMSs and validate the tool in industrial settings.
If you want to know more about this research, collaborate, or talk about it, please don’t hesitate to contact us or give our tool a try!

Joan Giner is a PhD student based in Barcelona. He is a software engineer specialized in web design and content strategy using content management systems.


Recent Comments