

In the search of understanding the state of affairs of modelling technology and ways to grow a healthy modelling biotope – miotope – the two previous posts examined general syntax properties and how to sort apart models from models. Eventually, that raised – not surprisingly – the matter of a solid conceptual groundwork: abstractions and architectural concepts in the modelling arena, of course already a major issue on the initial list of our 25 requirements:
(requirement 5, Appropriate Abstractions and Reasonable Meta Models)
The Modelling Arena
The following diagram shows the various areas where modelling already plays or reasonably might play a role in an organization (click on it to enlarge). Primarily, there’s the Business System itself, perceived as a purposeful arrangement of people, things, and rules. It can be broken down, and parts of it are likely IT Systems (the picture is IT biased, corresponding to the primary focus on Business and Information Technology of our undertaking).

The system parts are, for a variety of purposes and in a variety of forms, described. This System Description in itself provides its own peculiarities and is an area of interest for us. Both the system and its description are represented in form of specific artefacts, which are, despite all virtual nature of the latter, located within a certain Landscape.
Many of these artefacts are, in addition to the primary role they play as system parts, targeted by a variety of supporting systems, which form the Infrastructure of the Business System: provisioning systems, operations systems, business development systems, etc.
Next to the formalised and materialised system parts for cooperation (e.g. processes), which are central to the primary business purposes, there is usually a volatile layer of information snippets covering the scenery, used for human handling and cooperation, preformalised, premature, but nevertheless gluing it all together somehow.
Last not least we can discover a set of shared Ontologies, as explicit or implicit conceptualising frames used by humans or machines to organise their interaction with the system. These play an important role in influencing the shape of the arena as a whole and in detail.
Modeling arena - see all the areas where modeling play a role in an organization Click To TweetThe Problem
What’s wrong with the picture? Easily, in real-world scenarios, we can find substantial discontinuities, fragmentation and plain voids, like the infamous Business-IT-Gap in the System Area, laborious manual portions in the Infrastructure, and weak, suboptimal or simply non-existing information flows where it would seem natural to have some. Discontinuities, fragmentation and voids are causes of a non-negligible amount of waste. Amongst the damage they cause, they disconnect models from reality. Models without impact are a language that is not spoken, without use, without meaning (coarsely according to Wittgenstein), leading to the death-spiral of modelling technology.

Early modelling attempts often contributed more to the pile of waste than helped reducing it. Rigid, top-down predesign of the whole enterprise perceived as a machine, to give an example. The message from the first miotope article can be boiled down to what is shown to the right: horrified by clumsy modelling attempts and seemingly philosophically underpinned by agile exegesis, the mainstream turned away from MDx’s complexity. Our thesis in a nutshell: MDx concepts haven’t been sufficiently adjusted to the problems at hand, we should keep going.
Horrified by clumsy modelling attempts and seemingly philosophically underpinned by agile exegesis, the mainstream turned away from model-based complexity Click To TweetWhat are we looking for?
Good Architecture, Sustainability, Information Gardening
Healthy systems in general show properties of quality in an organic, unobtrusive fashion. In the industrial world that translates to the beautiful, swimmingly going construction, known to every true engineer (as e.g. nicely portrayed in the tales of Stanislaw Lem). But beauty alone would be hard to argue in an economic world, the point is: healthiness implies insurance of mid- to long-term economical sustainability (that’s quite the definition of healthiness) – everything is just at its proper place. What’s the secret of such systems?
In the realm of IT, corresponding to this “proper place” notion, there are two well known and universal quality indicators: Separation of Concern and Freedom of Redundancy (DRY-ness). As always, keep the balance: lack as well as exaggeration are harmful and rightfully perceived as ugliness: dirtiness in the former (e.g. code smells, plain chaos) and sterility or rigidness in the latter case (cathedral style/ivory tower architecture). These principles can be considered as being at the heart of many other architectural principles – e.g., tight coupling usually indicates an under-separated concern – and thereby of the art of modelling as well. Art, because it requires the IT equivalent of the green thumb to keep a system healthy, and personally this is my favorite role model for that job: information gardening, with plenty of interesting connotations.
(Tagging the Model Zoo, Modelling Quality)
Practically speaking: we want to strongly support maintenance and understandability, so that for every intent we have in mind we just need to modify the relevant information, at a single place, and nowhere else, know with ease where that place is, to keep the impact as low as possible.
In this light, looking at the Modelling Arena as a whole, the lack of such holistic quality is obvious. There are many good but isolated approaches, which deserve as well as require some alignment and tuning.
A Language, not a Monologue
Once more, to be clear about the goal: we’re looking for a language, which supports describing our systems in a “healthy” way, so that the language itself does not get in the way. We’re not looking for a specific, final, unchangeable, second sighting description of a specific, final unchangeable system. The latter (such a specific description) would be the dreaded BDUF, the former (a good language) would enable the exact opposite.
A good modeling language supports us to describe the system without getting in the way Click To TweetI.e., we would like to be able with ease to create a description with the following “Model Conformance & Care Tag”. To which extent we create such a description in a given context is a different matter. That Tag reads:

- A description of…
- a Business and/or IT system (depending)
- from the perspective of Business (at least understandable, +/- DSLs, +/- Recursive Pareto)
- covering completely (100%)
- all aspects (100%),
- sufficiently precise (100%),
- with well separated concerns and no redundancies (SoC 0/1, DRY 0/1 decomposition).
(requirement 8, Modelling Coverage – how horizontally complete a certain aspect is)
(requirement 9, System Coverage – whether all aspects of the target are captured)
(requirement 10, Modelling Precision – how vertically complete it is)
(requirement 11, Model Zooming)
(requirement 12, Model Evolution)
(requirement 13, Modelling Quality – DRYness and SoCness)
(requirement 15, Model Role – what is the model used for in a certain context?)
The Walkthrough
In the following I want to take you for a journey through the modelling arena, looking at existing approaches, watching out for sources of fragmentation, discontinuities, voids and seeking options for refactoring and harmonising.
IT System Architecture
I’d like to start with an area which is normally not considered to be, at a first sight, strongly related to modelling technology: plain old IT system architecture. Yet, given that the respective systems are occasionally a central part of what is modelled, it should be particularly striking that we need to take care of a clean target first, shouldn’t we? Otherwise, how could we hope to get a clean picture, if the original is not?
Three Tiers
Separation of Presentation, Domain Logic and Storage as a commonly accepted pattern can be taken for granted. What kind of separation? Usually, the logic layer is more or less free from presentation and storage concerns. In contrast, the presentation layer often contains undeniable amounts of domain logic, just think of validation, interaction flows and data manipulation protocols. Moreover, the separation is at most SoC-2, which means that if something is modified in the logic layer there is an immediate and often laborious impact on the UI.
A plethora of MVC and derivative [MVCP]* patterns have been developed to address these problems, to a substantial amount conceptually meandering around technical constraints (like HTTP/REST/Web) and outdated assumptions (omnipresent direct coupling), seemingly even today still in search of the escape route from the swamp.
According to our definition of SoC-1, what we seek is an abstraction that shields us from all such impacts: an abstract view of the interaction with different domain logics, untouched by implementation details of such logics and their life cycle. That sounds simple, but despite its simplicity and the age of the idea (our corresponding MVC-family relative, M3V, dates back to somewhen in the 90ies), realisations of this principle are still not to be found. Instead, if at all, abstractions go in the opposite direction: generalised user interfaces as viewed from the perspective of the domain logic.
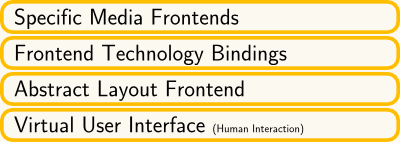
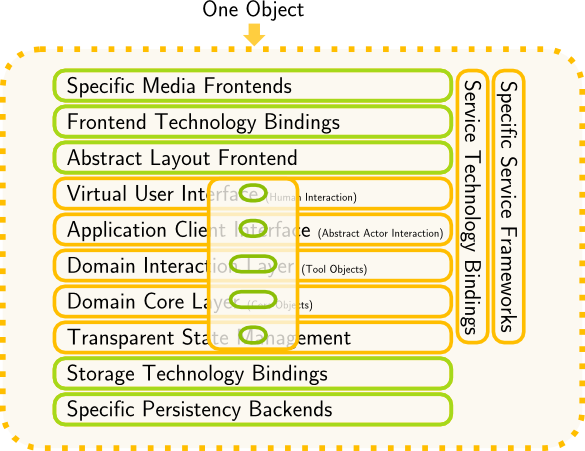
We call this abstraction, effectively providing an API enabling humans to interact with arbitrary domain logics, but without being rendered to any media, the Virtual User Interface (VUI). Following this approach more or less naturally suggests some further finegrained separation, as is illustrated in the diagram to the right: on top of the VUI we can build an abstract representation (Abstract Layout Frontend, ALF) of certain media specific ways and customer tastes of layouting the VUI, which in turn is mapped (by Frontend Technology Bindings, FTB) to Specific Media Frontend (SMF) technologies, like HTML, JS, Desktop/Browser etc. Note that the relations ALF/VUI and FTB/ALF can be cleanly implemented as SoC-1, while the relation SMF/FTB depends on the architecture of the SMF, but this is not a per-project issue, so it does not really hurt.

In addition, following this approach, all the former domain logic which was buried in the UI needs a new home then: the Domain Interaction Layer (DIL), which resides on top of the Domain Core Layer (DCL), also coupled in a clean SoC-1 relation. The DIL contains tools, workbenches and automata needed to work with the core objects, and the DIL is by all means domain related, i.e. the DIL as well as the DCL together form the domain logic layer (this distinguishes the DIL from layers on top of the DCL in other multilayer approaches).

A similar reasoning can be applied to the persistence layer. Here, the separation is traditionally already much better, but still suffers from the “Law” of Leaky Abstractions: Domain Objects usually exhibit a few but still annoying persistency specific properties, and transaction handling often sneaks around in the domain logic, even the UI logic, often in disguise. Without going into details, a possible approach is shown to the right, with similar implications to SoC-1 separation as within the UI.
Concerning Concerns – An Architectural Walkthrough of the Business and Information Systems Arena Click To TweetServices
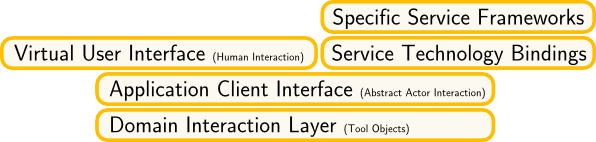
Where do services fit into the three-layer picture? They share some functionality with the UI – authorisation, token/session handling or state transfer – but they are often more core oriented than user oriented. Obviously, there’s another concern in-between, which can be shared by both client types: an Application Client Interface (ACI). It provides the shared server-side connectivity functionality required by every kind of independent actor, be it a human or an automated one. On top of that than the bindings differ, dependent on the actor type.
Pasta, Pasta!
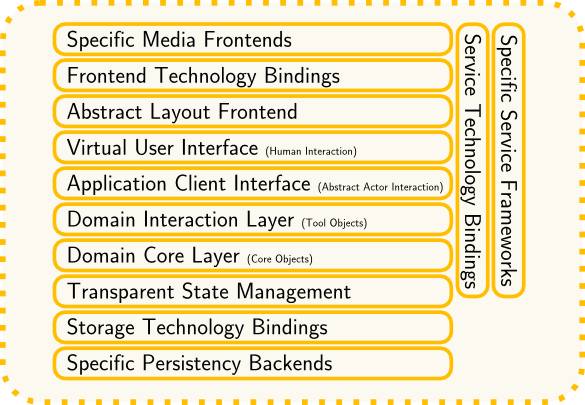
Putting the pieces together we get some fine lasagna, as illustrated to the right. Did we make things worse? What about DRY?
Objections to such constructions usually go by the antipattern called Lasagna Architecture: coupled or redundant information is scattered around, changes affect too many locations and thereby they do not help to decouple the matter, but make it chewy by tangling it all together.
Slicing Objects, Samurai-Style
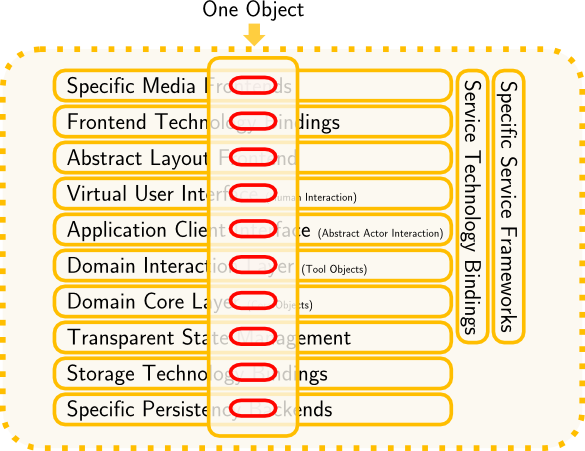
Imagine a sword fighter who cuts onions flying through the air into multiple slices. In my wild fantasies, my take is that it would be most practical do this in a horizontal fashion, thereby the image. Onions correspond to Objects, or similar small domain oriented portions of code.
This lasagna/slicing problem has been known since OO and layers are around, and indeed it is unfortunate.
Does it apply to the proposed layering here?
As a first observation, we should note that we introduced SoC-1 here exactly to address that problem. Which means, a certain amount of our layers is not at all related to the specifics of our domain logic anymore, and vice versa. Instead, they rely on appropriate abstractions, and are merely specific to isolated concerns, e.g. the respective frontend or backend technologies.
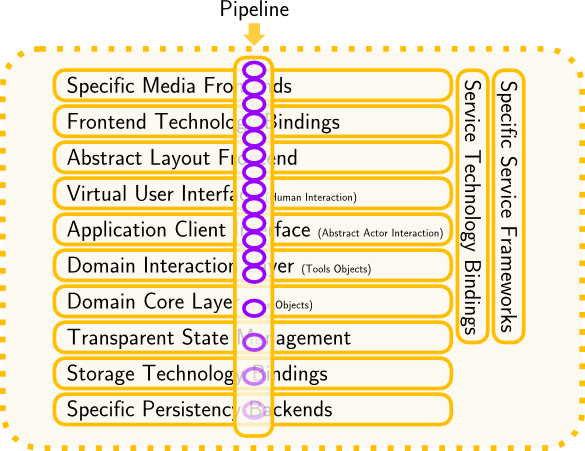
Therefore the upper and lower layers do not deal with project specific issues, but melt into the fabrics of our platform: frontend and backend mapping as an infrastructure provided service, to be developed once and for all (well, nearly for once, nearly for all…).
Looking at our object, that leaves only a handful of slices. Are they undesired?
Your mileage may vary, but doing the SoC & DRY stuff properly provides us with a nice set of boxes to put the respective concerns into: adding a new field might affect a couple of them, but if the logic goes here and the styling there, this looks quite apt to me.
Secondly, depending on the situation, there is no need to represent all layers strictly, the important point is to keep them in mind and that the concerns are clearly distinguishable – it is perfectly possible to implement a Raspberry Pi based service written in C in a single .cpp file that follows these ideas.
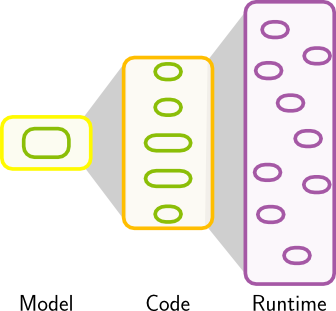
And finally, last not least and most important, we should not forget that our goal was not to find The Best Architecture ™ for manual coding, but crafting a target that can be easily hit by modelling technology.
The principles of SoC and DRY may be applied very differently to different types of artefacts in our provisioning chain: to different modelling levels, code levels, release artefacts, the installation and finally the runtime process. At the end of the day, we need to find out about which level we care to which degree. Certainly no one will disable the disk cache because memory pages are redundant.
Polydimensional Vegetables
Layers have been criticised for other reasons, and quite rightful. There are patterns around like Hexagonal, Onion and Clean Architecture, summed up in this very nice blog series by Herberto Graca.
The common idea is to isolate the domain logic completely from the rest around, so the logic becomes agnostic to its environment. To emphasize this fact, the visual layering has been abandoned and things arranged differently (hexagonal, circular, etc.; my variation of this theme from 1995 can be found here (Cyberspace Architecture Project) and here (Cyberspace Foundation).
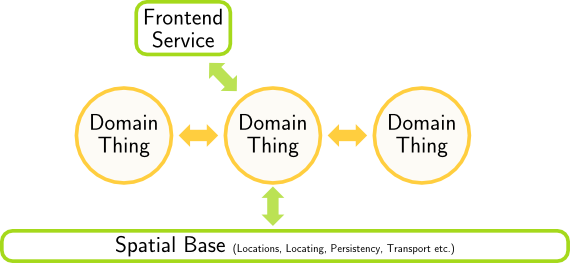
Besides isolating the domain logic, the matter of SoC can be pushed slightly further, as illustrated to the left.
We can distinguish two levels of separation: first, a technical separation of a) the pure domain logic, b) the Spatial Base, which encapsulates issues like locations, persistency, and networking and c) a collection of front-end services which allow humans to get in touch with the domain logic. Then, secondly, within the domain logic we can concentrate on domain issues alone and e.g. think about how different domain things view each other and interact with each other, logically.
I.e., in contrast to the above-mentioned architectures, I wouldn’t put e.g. infrastructure, user interface and communications into the same external service pot, but separate the technical external aspects (like communication and interaction) from the domain logical external ones (like interacting with another component).
In this light, the layering in the previous section is not in conflict with these architectures at all: the SoC-1-dependencies already emphasise the independence of the layers from each other, specifically the domain logic layer, but further on also all other layers: our lasagna is, in fact, a very tasty one!
Geological Ground Drilling
The issues with the sliced object in recent years have been proven to be the tip of just another iceberg: Reactive and Beyond. For the object-oriented expert eye, the reactive style of doing stuff at first might look horrifying. Like with geological ground drilling, the layers are sliced vertically, not even sliced but actually perforated, with few regards to whether a method belongs to which object or whatever.
Another prominent example and hard to gnaw on is state transfer (REST), i.e. whether we store the state of ongoing interactions in the server or send it around the internet.
What’s the reason for such vandalism? The arguments brought up in favor of the reactive programming style are quality issues concerning user experience with modern interfaces as well as to some degree concerning large and highly distributed systems behind. Nothing wrong with that, sure enough. But why throwing out the baby with the bath water?
Let’s try the SoC perspective. We can sort apart three major concerns competing for our attention: a) information organisation oriented around ontological alignment with the business domain for purposes of system development sustainability, b) data and control flow optimisation for the above given purposes, and c) peculiarities of operation execution for comprehensibility as well as for conforming to and supporting (b).
The last concern, operation execution, is quite an enormous iceberg, just to give an idea of it’s size – which is, even by sophisticated reactive approaches, still not fully recognised – here’s a list of related issues:
- 1. execution state and reporting ● 2. error reporting, handling, translation and design ● 3. completion state reporting ● 4. operation specification, parsing and preparation ● 5. execution context injection for e.g. progess visualisation and for external interception (debugging, stepping) ● 6. execution control, i.e. coordination of intent, invocation, preparation, execution planning, actual execution, progress and healthiness feedback, completion and back reporting ● 7. resource scheduling (when, where) ● 8. reactiveness (backpressure etc.) ● 9. dataflow optimisation (GraphQL, CQRS) ● 10. wiring of events and callbacks ● 11. decision handling (what if, repairing, aborting) ● 12. analysis (debugging, logging, stepping) ● 13. predefined and dynamically constructed execution plans, reporting of, lifecycle of ● 14. pre- and post-execution impact analysis ● 15. reporting and dispatching of state changes ● 16. spontaneous vs. long term processes and workflows ● 17. multiple resources and coordination in the light of processes/workflows ● 18. defining specific algorithm for execution vs. defining only the desired target state ● 19. parametrisation all around.
The debates about the superior coding paradigm seem to demonstrate just one fact: that with current practises and/or language features the concerns (a), (b) and (c) cannot be separated well enough, so that one or two of them have to be sacrificed in favor of the third: optimise or keep DRY or stay flexible.
While we can with no difficulties combine the approaches to a certain degree, it is equally clear that things can be stressed to an extent that this will not work anymore. Yet again: modelling to the rescue! The conflict exists on the implementation language level, the learning for us is to keep these different slicing, drilling and perforating techniques in mind and remember what the purpose of each is. On the modelling level, we can and should separate the logical domain from optimisation strategies as well as from, see below, architectural decisions.
Subterranean Cross-Holes

As a final remark on optimisation, a realm where nothing is off limits, think e.g. of shared data synchronization via REST vs. SQL vs. memory page mapping. Hardcoded well-designed layers and shieldings can get in the way and occasionally have to be taken down, vertically, horizontally or howsoever. All the more we need to become aware that our present programming languages are still implementation languages, and not necessarily well suited to express sustainable solutions.
More on Vegetable Dicing
The matter of slicing has a softer and a harder aspect: the softer one is about organising the code and implementing internal interfaces, the harder one is about separating runtime artefacts. Obviously, code organisation is a prerequisite for separating.
Separation affects horizontal layers, like between browser and server: which part, how much logic, by which abstraction, put where? Recently we observed e.g. the diffusion of logic from the server into the client, up to the point of anemic domain models. Separation also affects vertical parts, like the partitioning into microservices, to give the most prominent example.
A well done organisation should give us the freedom to choose the granularity of our system, as we wish, even if we now and then change our mind. Well done, again, translates to separation of all technical aspects from the domain logical ones, and within the domain logic further separation according to business concerns, like units, responsibilities, tasks, using appropriate Bounded Contexts, represented in a couple of distributed, yet still to some degree aligned models.
All in all…
…we can distinguish the following main areas of concerns in IT systems, which can be divided further on in respective subconcerns:
- Application Domain: organizing the domain related properties of the systems, like objects, interactions, and constraints. We will look closer on that in the next major part of the Modelling Arena, the Business System Architecture.
- Technical Functionalities: the classic separation along provided functionalities like presentation and storage, as explicated by means of the pasta image, which define the subconcerns in this area. The information associated with these concerns can be conveniently provided on the modelling level in correspondingly organised stereotypes, as described here
- Boundaries and Slicing: how to distribute the first two areas onto the various artefacts from code to runtime, and which boundaries to implement for the sake of understanding, maintainability, exchangeability and potential scalability. There are the two major subconcerns of how to organise the code and how to distribute onto runtime artefacts. The means to do this is a set of architecture models, associated with the domain models.
- Strategies and Optimisations: whatever we need to make the customer happy. Due to the general nature of these issues they cannot necessarily be located at a well defined place in the model, but the placement within stereotypes in the domain model as well as in the architecture model is often sufficient.
While it seems we cannot take all these requirements simultaneously into account with present programming language capabilities, all the more we shall carefully consider their separation in our models.
Previous post concerning miotope: Tagging the Model Zoo – Symbols for Model Conformance and Care
Next post concerning miotope: Concerning Concerns – Terms and Examples
I’m working in IT since the late ’80ies of the last century. Half of my time I spent crafting software of various kinds for customers, increasingly based on model related technology. The other half I invested in research and development of a fully model driven software production system and respective suitable concepts, most of which is available as open source or creative commons. Since the beginning of the millenium I’m doing this in my own Hamburg-based company and offering software production as a (model based) service — Andreas


Recent Comments