
The advances in Artificial Intelligence and, in particular, in the Natural Language Processing (NLP) subfield, are becoming mainstream technology. For instance, NLP recent advances such as GPT-3 are able to produce human-like text to be used in copywriting, translation or summarization tasks.
In the software engineering community, NLP techniques are being applied to code-related tasks and artefacts. For example, it is now possible to build an NLP-empowered program for the automatic generation of comments that explain what a piece of code does without any human intervention. Most of these advances rely on the use of pre-trained language models1 for NLP. Pre-trained language models can learn universal language representations from a large corpus. The resulting models are then beneficial for many downstream tasks without the need to retrain a new model from scratch.
We strongly believe that, in the same way languages such as Java and Python, are taking advantage of NLP, the Object Constraint Language could also benefit from these advances. Among others, it could be very useful for the automatic translation of OCL expressions. This is, given a NL sentence explaining an OCL query, the actual OCL code could be generated; and the other way around, given an OCL query, the NL description could be verbalized. OCL auto-completion and code generation would be another possible straight application of NLP to OCL. Last but not least, NL and OCL could be combined in an NLP Question Answer (QA) system that allows users to ask questions about the model data.
To put in place all these promising approaches, the first step is to create a NL ↔ OCL dataset that can be used to train the NLP models. To achieve this, we call for a community effort to collaboratively build such a corpus and provide the basic infrastructure to make the data collection easier and more efficient through a website in which the community will be prompted with NL queries and are expected to provide the corresponding OCL expression. We will make this dataset publicly available to everyone in the project’s GitHub repository.
Note that for our purposes, it is not enough to just collect examples of OCL expressions. We need to pair every OCL example with its natural language counterpart description. This is precisely the purpose of this initiative.
Towards an OCL corpus
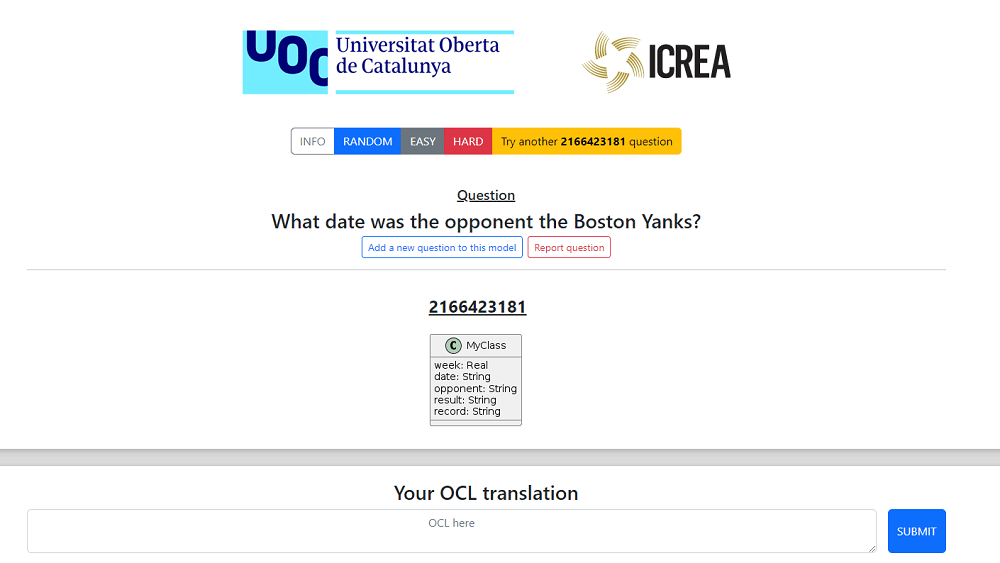
To help in collecting such examples, we have deployed a simple website that randomly shows a UML class diagram, a question/query in natural language and requests the community to write the corresponding OCL expression.

The initial set of questions to translate has been populated from existing datasets containing NL questions and SQL statements. In particular, we have used the following NL ↔ SQL datasets:
- WikiSQL, a large crowdsourced dataset for developing natural language interfaces for relational databases, and
- Spider, a large-scale human-labeled dataset for complex and cross-domain semantic parsing and Text-to-SQL Task.
To adapt them to our goals, we have processed these datasets and have:
- filtered the SQL statement so that we only keep the NL expressions expressing queries; and
- transformed the SQL schemas to UML class diagrams.
Currently, our dataset contains 9, 455 different questions on 2, 882 different UML class diagrams / models. 166 of these models come from Spider, while 2, 716 come from WikiSQL. Although the number of models coming from Spider is rather small, Spider is a valuable complement to WikiSQL as WikiSQL’s models only contain a single class. With no associations, WikiSQL models only cover a reduced subset of the OCL language.
Additionally, the community can also suggest new questions (and a first translation) that, upon manual revision, will be validated and added to the dataset to be used as additional questions to ask future users.
Note that each NL question will be presented to different users more than once and we will collect all their responses. We do it because of the high expressiveness of OCL that results in several alternative valid formalization for the same constraint. We want our model to recognize as many alternatives as possible.
It can also be the case that some answers are just wrong and therefore we cannot just rely on single answers to each query. Some of these wrong answers could be automatically detected by doing some
simple static analysis but in general it will up to us to manually doublecheck them when curating the dataset if we want a clean corpus.
How to get involved


Great initiative, guys!
I would love to see the complete model so that I can e g use it in a tool like MagicDraw and test OCL there before sending it.
And is the set of examples already available in a repository as well?
And how about extensions using stereotypes which is probably specific to UML, but not relevant for the initial seed from WikiSQL and Spider?
Thank you!
There is no such download link by now, but it is a very good suggestion…
We could implement it and notify you as soon as it is ready. It will be very very soon.
Anyway, what you will be able to download will be a model in plantuml, which is what we use to render.
You can take a look at all our Spider examples (in plantuml) following this URL:
https://github.com/SOM-Research/nl-ocl/tree/main/static/plantuml
We only have models from Spider and WikiSQL right now. Actually the more relevant and complex are the models from Spider. They are very simple and therefore do not use stereotypes.
OK, it is ready! Now you can download the model you are seeing in the website through a link. We hope this helps you.
Are there any updates on this initiative?
Not from my side, but I’d also say that new LLM are much better at “understanding” OCL and show much better results than what we obtained when testing them at the time