
Have you ever developed a model-based tool and didn’t have the instances to test it and run benchmarks? Then, maybe this post is for you.
In recent years, in the AtlanMod team we have focused in the development of core technologies to support scalable modeling processes (see for instance Neo4EMF – Big Models made possible with EMF and Neo4j). However, after doing the initial testing, sometimes we didn’t have the adequate models to test and evaluate our tool. This is especially true when the needed models have to be of a considerable size, and thus, they cannot be created manually.
To solve this, sometimes we were able to use existing models from other case studies, or we simply obtained them from reverse engineering big sources of codebase. However, this is not always possible, and here is where the EMF random instantiator comes into play.
An EMF (pseudo) random instantiator
The EMF random instantiator is an open source (EPL) utility that produces sets of pseudorandom instances for EMF (Ecore) metamodels. The instantiator has been developed with three main goals:
- No domain knowledge is needed to generate the instances.
- The size of the resulting model can be controlled in terms of number of elements.
- The generation should be deterministic, providing the same set of result instances when a seed is specified.
A default configuration using uniform probability distributions for each meta-class and structural feature is provided. This configuration is ready to use, and can be invoked from command line. The default configuration considers that any non-abstract EClass without a required containing EReference is a valid type for a root EObject.
A generation configuration holds information such as (i) the metaclasses that should (not) be involved in the generation; and (ii) the probability distributions to establish how many instances should be generated for each metaclass (and which values should be assigned to structural features). Details of the configuration can be found here, and of course it can be tweaked for your own needs.
The instantiation process is guided by a goal number of EObjects (i.e., expected size of the result instance in terms of number of elements). The generation stops once this number of elements is reached and no multiplicity constraint in the containment references is violated.
The current implementation uses XMI as the persistence format for the generated models. So that, although models of up to 2 billions of elements are theoretically supported, the actual maximum number is limited by the hardware configuration. In our experiments (and with the proper hardware) we have generated models of up to 30M elements producing XMI files of up to 20GB (approx.).
Since the default configuration is metamodel-agnostic, generated models are not guaranteed to successfully pass an EMF diagnostic. This could happen for several reasons: the configuration parameters do not allow the creation of instances of a specific class, the creation of a cross reference modifies the opposite side, etc. Nevertheless, the tool can (optionally) run a diagnosis on the set of generated models and provide a detailed report if any error is found.
Running the EMF random instantiator
The EMF random instantiator can be directly executed using the provided Fat JAR which contains all the required dependencies:
$ java -jar dist/instantiator.jar <program arguments>
The only required argument is the file containing the metamodel to instantiate. Nevertheless, several additional parameters can be configured as shown in the usage information. Some of the most interesting are:
-s,--size <size>
Average models’ size, e.g. goal number of elements (defaults to 1 000)-p,--variation <proportion>
Variation ([0..1]) in the models’ size (defaults to 0,1)-d,--references-degree <degree>
Average number of references per EObject (defaults to 8). Actual sizes may vary +/- 10%.-z,--values-size <size>
Average size for attributes with variable length, e.g. Strings, arrays… (defaults to 64). Actual sizes may vary +/- 10%.-e,--seed <seed>
Seed number (random by default)
Example
The next figure shows two models generated automatically using the EMF random instantiator.
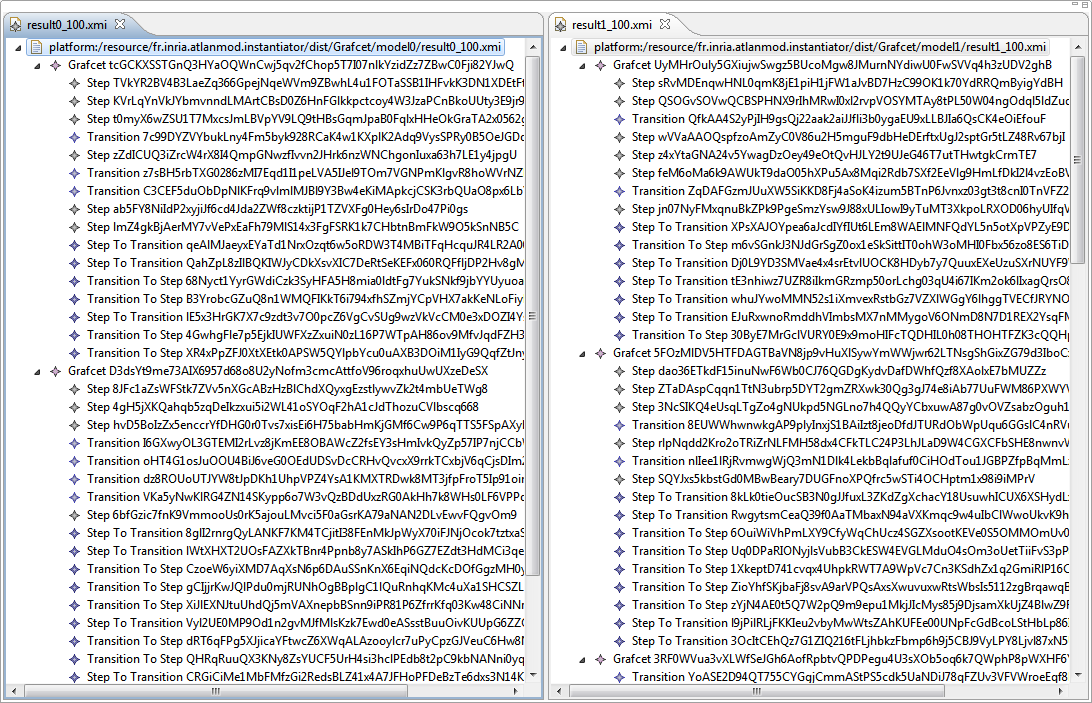
Generated models for the Grafcet.ecore metamodel using the pseudorandom model instantiator
The command to generate those instances is:
$ java -Djava.util.logging.config.file=logging.default.properties -jar instantiator-fatjar.jar -m Grafcet.ecore -n 2 -s 100 -g
It specifies that a set of 2 random models will be generated, of an average size of 100 elements, and using the default configuration with a random seed. The file logging.default.properties is used to control the verbosity of the log messages. The produced log messages can be seen in our GitHub page.
Credits
The EMF (pseudo) random instantiator has been developed by the AtlanMod Team (Inria, Mines Nantes, Lina), reusing some code from the emf.specimen generator from Obeo.
I’m a Postdoctoral Researcher at SOM Research Team, in Barcelona. Currently, I’m involved in the development of scalable tools for MDE, especially in the persistence of Very Large Models.


Hi Abel,
That sounds great. We at Generative Software have developed a generic editor and parser for textual DSLs, based on EMF. We use our “Virtual Developer Modeler DSL” to define internal DSLs that are all handled by a single generic parser and a single generic editor.
We also have the problem to provide big models to be able to load test our code generation platform as well as our code generators (and code generators of others). Possibly, the EMF random instantiator might not work for us due to the generic nature of our editor and parser? For some of our metatypes we would have to control the values of certain EReferences. We for instance have an EClass “Element” that has an EReference “elementDefinition” (pointing to EClass “ElementDefinition”) where the element definition must not be a random object. Do you see any chance that something like this is easily doable with EMF random instantiator?
Cheers,
Marcus
P.S.: If you are interested, you can make the EMF random instantiator publicly available on our generation platform “Virtual Developer” (code generation as a service). This way, anybody could execute the random creation of models without having to install or build any software. Just drop me an email if you want to know more about it.
Hi Marcus,
given the problem description you have done, probably you are right and the random instantiator does not work four you as is. The instantiator only takes type information to fill containment and cross references, and any additional constraint on your metamodel will not be considered.
Nevertheless, I would say that the code is not specially complex (7 classes), and it wouldn’t be difficult to tailor it to your needs. The creation of the models is done in two steps: first, the full containment tree is populated (+ attributes) and an index of is created; second, the cross references are filled based on the type information (the index is used in this step to get valid candidates). The class fr.obeo.emf.specimen.SpecimenGenerator is the one in charge of creating the model; and it contains a method called “generateCrossReferences(EObject eObject, …)” that fills the references on an EObject according to the configured distribution using the index. Any additional constraint that you need to check to populate the cross references could be added at this point.
It’s true that some coding is needed, but I think that it’s easily doable. Since the project is open source, I encourage you to test it 😉
Hi Abel,
Your tool seems interesting.
I’m also working on a model generator based on CSP (http://www.lirmm.fr/~ferdjoukh/english/research.html).
I want to know how your tool is able to fill an Ereference between two EClasses ?
And how two models are different ? Do you quantify this difference ?
What about OCL constraints ?
Best Regards
Adel
Hi Adel,
can you elaborate a bit more your question? I don’t know exactly what are your doubts…
Just for summarizing, as I explained before, the process is as follows:
First, the full containment tree is populated and all the attributes are filled. Mandatory attributes are initialized, and optional attributes maybe initialized (or not) randomly). Additionally, whenever an EObject is created, it is added to an index. This index is a map whose keys are the metamodel EClasses and the values are lists containing all the instances of the EClass.
Second, the cross references are filled based on the type information. This process traverses the whole model, taking one EObject at a time, and for each element checks the EStructuralFeatures that should be filled. The EStructuralFeatures have a type, so that, when it has to be populated (whteher because it’s mandatory or because the random generator says so) an existing EObject of the right type is picked up from the index.
Regarding about having different models… we rely on the pseudo-random number generator. We only seed the generator at the beginning, and we keep getting values from it according the uniform distribution for every operation that needs randomness. Regarding quantifying the difference… no, we don’t do it.
Regarding the OCL constraints… no, we don’t consider them either.