
What if your software project loses the best developer? Who is the developer you can get rid of?
I bet these are questions that all project managers ask themselves several times during the lifecycle of a software project. Developers are valuable resources for any software project. They hold the knowledge to make the project advance and consequently, when they leave (temporarily or not), they can make the project slow down. However, not all the developers hold the same knowledge and the assessment of their actual knowledge in the project is far to be easy (their contribution could be spread on different source files, modified in turn by other developers).
To this purpose, a good indicator is the concentration of information in individual developers. This is also popularly known as the bus factor: “number of key developers who would need to be hit by a bus (incapacitated), to send the project into such disarray that it would not be able to proceed”. Alternative names for the bus factor are pony factor or truck factor.
A low bus factor means that the risk is high, since the information/knowledge is held only by a few developers. In the worst-case scenario, only one of them holds key knowledge of important components of the project, making his presence a single factor that could make the project fail. On the other hand, a high bus factor means that the risk for the project is low, since many developers know enough to carry on in the case some of them would quit the project.
But computing the bus factor is not easy. For instance, how do you calculate who counts as key developer?. Below, Valerio Cosentino talks about our tool to compute the bus factor of an open source software project and how it can help to answer the questions above. You can read more about the tool on the paper: Valerio Cosentino, Javier Luis Cánovas Izquierdo, Jordi Cabot:
Assessing the bus factor of Git repositories. SANER 2015: 499-503. Note that the tool itself is not maintained anymore (there are other tools available such as git-truck, each of them using different approaches to the calculation) but I think the method behind it (explained in this post) is nonetheless still a valuable reflection on the challenge of such computation.
Enter Valerio:
In order to ease the assessment of the bus factor, we present a tool that automatically calculates such an indicator for any software development project relying on a Git software repository. The tool provides bus factor information for any file, directory, branch and file extension in the Git repository, highlighting the key (i.e., most knowledgeable) developers for each of them and for the project itself. In addition, the tool allows to simulate the impact of one or more developers leaving the project, showing the file, directories, branches and file extensions that would be affected if they disappeared.
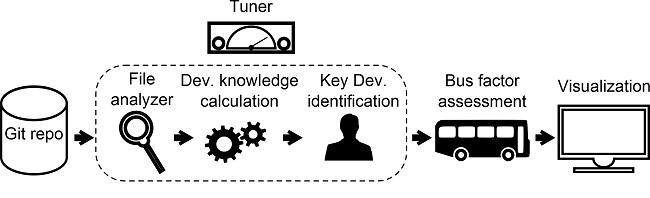
Steps to calculate the bus factor
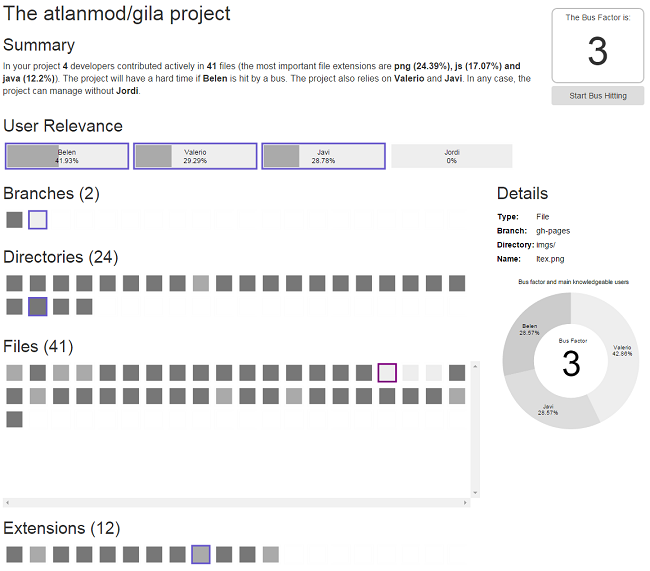
Example of the results generated by the tool
The process underlying the tool can be parameterized at several points so that companies can tailor it to their needs. For instance, some companies may be more risk-averse and therefore opt to require stronger conditions for a developer to be considered part of the bus factor (resulting in a lower bus factor, and thus, in a more conservative risk evaluation that could trigger countermeasures early on) while others
may be happy accepting higher risk and consider that even developers with little knowledge on a file would be able to take it over if the situation requires so.
The steps to compute the bus factor
File analyzer
This step is used to retrieve all information regarding who (and when) modified each file in the repository. For binary files (e.g., images, executable files), it collects only the change event type. For text files (source files, configuration files, documentation, etc.), it goes one step further and collects the previous information at the line level. Regular expressions are used to identify the addition and deletion symbols in the diff information with respect to the previous version of the file. This step also retrieves the number of times it has been included in a commit, the branch and directories in which is contained, its file extension and the history of the file to check whether the file has been renamed or moved across the repository. If so, the process recursively finds and groups together all the corresponding previous versions.
Developer’s knowledge calculation
Based on the file information, this step assigns a percentage value of knowledge for that file to each developer in the project. This value is then propagated to assign a knowledge percentage to the developer for each directory, branch and the project itself. As an auxiliary value, this is also aggregated at the file extension level. This propagation is performed by simply adding up the knowledge on individual files and scaling the results based on the number of files in that directory/branch/project. This ensures that developers with a little bit of knowledge on many files are still represented in the knowledge chart for the, for instance, directory where those files are located.
The developer’s knowledge of a file is measured according to one of the four different metrics described below. All metrics play with the information of the file modifications aggregated in the previous step, again, either at the file level, based on the number and order of modifications each developer made on the file, or the line level, based on the number and order of modifications on each line later summed up and scaled to a percentage value to get the corresponding developer knowledge at the file level.
Last change takes it all
This metric assigns all knowledge of a line/file to the last developer that modified that line (or file for binary files).
Multiple changes equally considered
This metric counts the number of times a line has been modified during the life-cycle of the project. It assigns more knowledge to the developers that modified the line/file most times. Therefore, with this metric, the result can be biased towards people with a coding style using smaller but more frequent commits.
Non-consecutive changes
In order to balance the effect of multiple changes on a line, this metric assesses the developer’s knowledge according to the number of non-consecutive changes on the line.
Weighted non-consecutive changes
This metric assesses the developer’s knowledge by relying upon the previous metric modified to take into account the position of the modifications in the timeline evolution of the line. It is used to assign incremental importance to the later modifications on the line.
Key developer identification
This step identifies the developers that have enough knowledge on file, directory, branch, and file extension to be part of the bus factor since any of them, if “surviving”, would be able to keep working of the artifact.
We provide a flexible formula that can be easily adapted to represent different situations, for instance, you can represent with it that a fixed minimum threshold of knowledge automatically puts you in the bus factor or more complex situations in which the top developers (relative to the total number of developers involved in the file) are selected. Our formula has two different components to give more flexibility to the calculation process. We first calculate the primary key developers and then the secondary ones. Their sum gives the bus factor for the artifact. Primary developers are those that have modified a minimum percentage X of the artifact. Secondary developers know at least a subset Y of X. By default (and based on our own experience), X is set to 1/N where N is the overall number of developers that have ever modified the artifact and Y is set to half of X.
Tuner
This step is used to tune the bus factor analysis. In particular, it allows the user to 1) control the resources and the developers to be analyzed and 2) parameterize the computation choosing the metric and the values for the bus factor formula.The second part is based on what we have previously explained. Regarding 1), the tuner allows users to filter out some files/directories/branches from the analysis (e.g., to focus only on source code files and remove libraries and other components), choose the granularity of the analysis (file or line-level) and group developers either to merge different usernames corresponding to the same physical person or to calculate the bus factor at the development subteam level by merging all developers in the same sub-team.
Bus factor assessment
The whole process is repeated at each level of the project to assign a bus factor to each file, directory, branch, file extension and the project itself. Note that the way the bus factor is calculated a given developer could be part of the bus factor of a file but not of the directory where that file is included. That is, she could be a key developer to maintain the file but if she leaves the project, the project itself could survive (even if maybe that file needs to be rewritten from scratch if its bus factor was 1 and therefore nobody else can take over it).
Visualization
This step shows the result of the bus factor on a web-page. A short summary of the project (name of the project, number of files, etc.) and the corresponding bus factor are shown at the top. All branches, directories, files and file extensions that have not been filtered are represented as clickable boxes. Clicking on the boxes shows the corresponding relations with the other boxes (e.g., files in a directory), its details (e.g., its name), its bus factor and the knowledge percentages hold by key developers. The page also shows the project developers as boxes. When a developer is clicked, the web-page highlights the software artifacts where she is a key developer (see the figure). Developers can also be temporarily removed to simulate the effect of those developers leaving the project. This recalculates the bus factor and shades the files, directories, branches and file extensions that would be affected because of their disappearance.
The tool can be downloaded at https://github.com/SOM-Research/busfactor