
The Pareto principle (also known as the 80-20 rule) states that, for many events, roughly 80% of the effects come from 20% of the causes.
This principle applies to many areas, e.g. “80% of your sales come from 20% of your clients” or “80% of your employee performance evaluation will come from just 20% of the items on your daily To-Do list”
What the rule tells us is that in anything a few (20 percent) are vital and many(80 percent) are trivial, and thus, to improve your productivity, you should focus on the 20% that makes a difference. Investing your time in the other 80% will only produce a slight improvement of your results.
I believe that this principle also applies to the area of model-driven development. I state the Pareto Principle for MDD as follows:
20% of the modeling effort suffices to generate 80% of the application code
This implies that, following a pragmatic MDD approach, we can boost our productivity and benefit from many of the advantages of modeling without the burden of defining complete and precise models. I think that for many companies, this 80% of code-generation will be more than enough or, at least, a good starting point to experiment with MDD before deciding whether to adopt a full MDD-based development process.
Let me give you an example. To achieve a 100% code-generation of a software system we need to fully specify during the modeling phase the behavior of all required system operations (e.g. using some kind of action language, as the one provided by the UML). However, it turns out that most of the operations (you guess it! around 80%) are simple CRUD (create/read/update/delete) operations, whose number, specification, parameters and behaviour could be automatically deduced from the static model elements in the class diagram! (e.g. if the class diagram contains a Customer class, it is not difficult to see that the system will need to offer operations to create new customers, to update each one of its attributes, … ). That is, with a 20% of the modeling effort (only the definition of the static aspects of the domain) we can automatically generate a staggering 80% of all operations required to query/manipulate the applications’ data.
For instance, given this model:
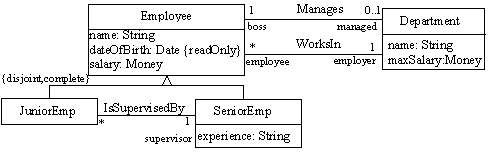
we could automatically generate this extended model:
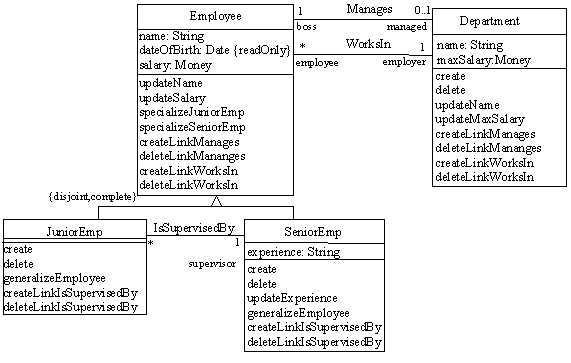
where each operation specification and body would be completely specified. For those interested in the details of the generation method used in this example, you can check the paper: Deriving Operation Contracts from UML Class Diagrams paper or in its extended version: Automatic Generation of Basic Behavior Schemas from UML Class Diagrams
and remember! this is just one example, I’m sure that the Pareto principle also applies to other aspects of modeling. Can you think of more scenarios?
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Perhaps that 20% of the code that is not generated is responsible for 80% of the competitive advantage that software produces. We need a study that can examine the productivity claims — I suspect these simple CRUD type functions would be pretty trivial to implement manually, as well.
These CRUD type functions are not always as trivial as they seem (in a paper that is now under review we check how many errors students had when manually writing those operations)
but of course, they could be manually implemented with a limited effort.
And obviously, the competitive advantage of the company won’t be ON that 80% OF the generated code, but I don’t think this contradicts the message of this post. In fact, what I’m saying here IS that you can easily GET rid off OF ALL these less important operations (that represent 80% OF your total) AND focus MORE ON those functions that ARE KEY FOR your product. Even if they ARE NOT that important, you’ll need to implement the CRUD ones anyway, so why bother when you have a way to automatically (and correctly) generate them?. To me, this represent an improvement in your productivity!
My pareto principle for MDD is being discussed as well in the model driven development forum and model driven architecture groups on LinkedIn.
Some comment excerpts:
I must say that while participating in development of some business-related applications, I usually saw 80% of complicated business logic (usually implemented as business rule sets) and 20% of CRUD stuff (the same percentage applies to test cases too). Implementation of the CRUD is such a common task nowadays, that I’m sure you won’t be able to gain much by generating it. In e-shop – maybe, but not in an enterprise invoicing solution. Though in such application you have quite complex data structures backed with RDBMS, some ORM is usually used here, and CRUD actually becomes only 20% of code (and 5 – 10% of effort) because on the other side you have let’s say 700 pages OF business rule docs, which normally can’t be automated that easy. DSLs are of a great help in this case, and that is much more important in my view.
ON the kind OF application. IN the ones I did WHEN working IN a private company (AND IN SOME OF the experiments we’ve done), my 80/20 rule applies but of course, in other domains or when dealing with other kinds of applications, your experience may be different.
[…] artículo sigue la filosofía de la regla del 80/20 (pareto principle) aplicada al MDD para auotmáticamente generar operaciones básicas para un diagrama de clases. En […]
If u r using models to generate crud operations and believe that gives u 80% of ur code, I might have to say the application you are building seems pretty simple with not many business rules. In which case you might as well just use an ORM.
I do believe this is the case for what we call data-intensive applications. Of course, there are other kinds of application for which this does not apply