
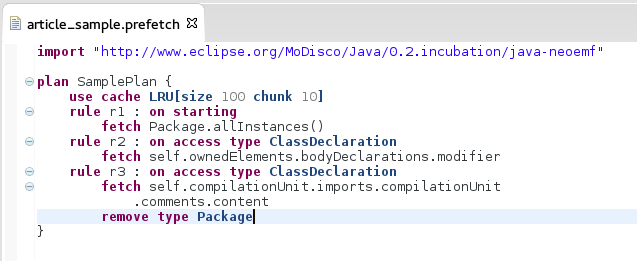
PrefetchML: A DSL to define Prefetching and Caching rules on EMF models
How to speed up the access and queries on large models thanks to our language (and execution environment) to define prefetching/caching plans for specific modeling scenarios
No Results Found
The page you requested could not be found. Try refining your search, or use the navigation above to locate the post.
Modeling: all you need to know


Recent Comments