
Software development projects are notoriously complex and difficult to deal with. Several support tools such as issue tracking, code review and Source Control Management (SCM) systems have been introduced in the past decades to ease development activities. While such tools efficiently track the evolution of a given aspect of the software project (e.g., bug reports), each provides just a partial view of it and usually comes with insufficient means (e.g., only command line support or other simple user interfaces) to perform any non-trivial query operation.
This is particularly true for projects that rely on Git, the most popular SCM system today. Despite the existence of several project management and monitoring tools built on top of Git, there is still a major lack of data integration efforts between them and they all fall short regarding the possibilities they offer for advanced query functionalities. Practitioners are therefore forced to resort to off-the-shelf tools based on predefined queries on individual aspects of the project.
Gitana is a new tool (available on GitHub) we have developed to overcome this situation. It exports the data contained in one or more Git repositories to a relational database in order to:
- Promote data integration with other existing development support tools.
- Enable to write queries on Git data using standard SQL syntax.
To ensure efficiency, Gitana relies on an incremental propagation mechanism that refreshes the database content with the latest modifications in Git repositories.
Full details on the Git conceptual schema we propose are available in our ER’15 accepted paper that you can read here. Read on for a summary of the work.
Approach
Gitana proposes a conceptual schema for Git to facilitate data integration between existing Git-based tools and advanced query operations. This schema is materialized as a relational database, for which we have defined an extraction process that populates and keeps it up-to-date and an export process to perform analysis in other technologies.
Conceptual model for Git data
The structure of a Git repository is shown in the conceptual schema of Fig.1. Note that the conceptual schema also includes some derived concepts, methods and attributes to facilitate the analysis of Git repositories by making explicit some information that is normally hidden or hard to query. This is the case for LineDetail ( that stores information for each line of textual files) and FileRename (that keeps tracks file rename actions), the getVersion method (used to get the version of a file at a particular timestamp) and the attributes filesDeleted and emptyLines (used to provide some activity metrics).
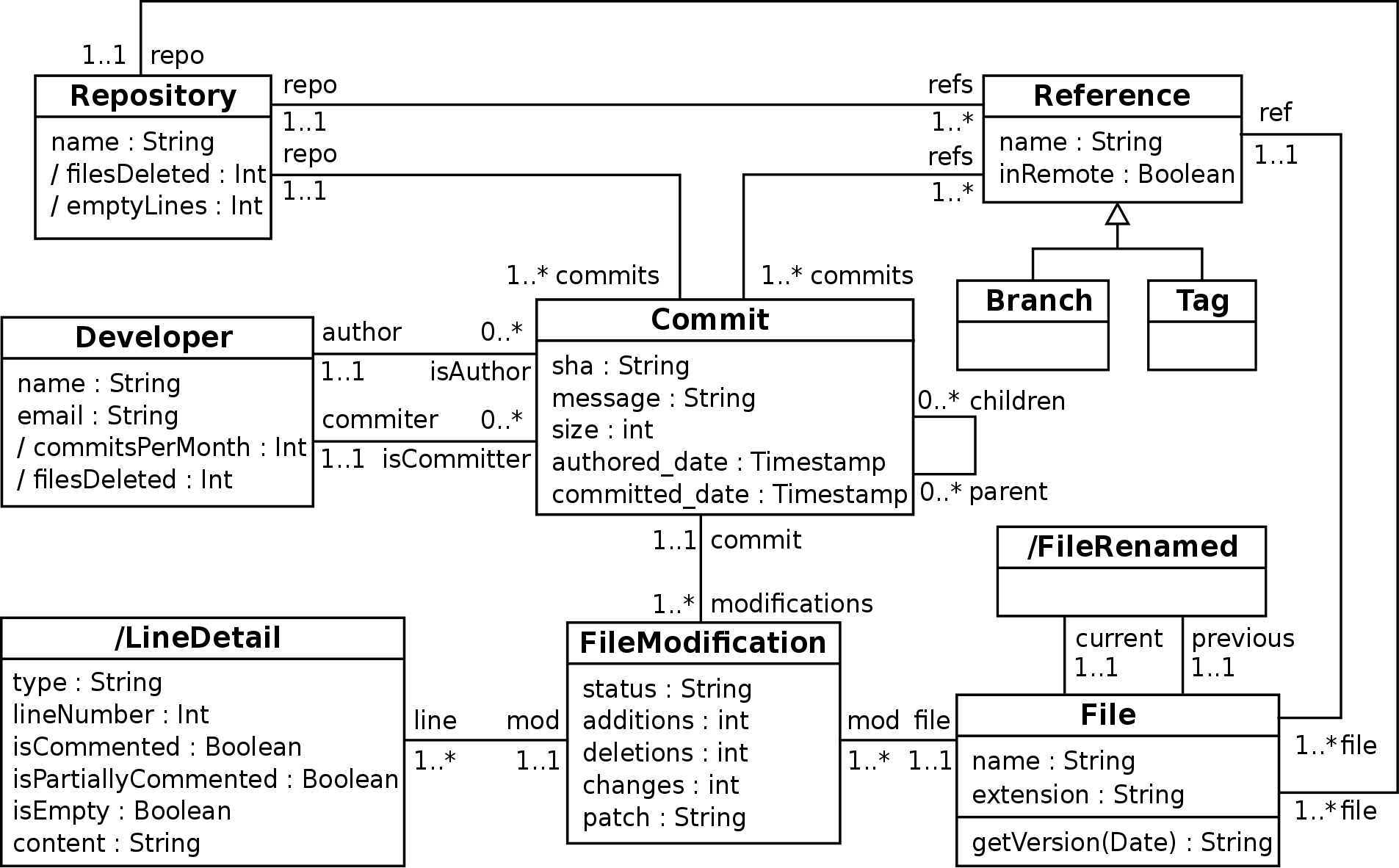
Fig. 1 – Conceptual model.
Database schema for Git data
The previous conceptual schema is materialized in the relational database schema of Fig. 2. In a nutshell, concepts/attributes in the conceptual schema are mapped into tables/columns in the database schema and associations are mapped into foreign keys or new tables depending on the cardinality of the association, following the typical translation strategies.
Additionally, the derived attributes in the conceptual schema are mapped as views, while auxiliary methods are implemented as either functions or stored procedures.
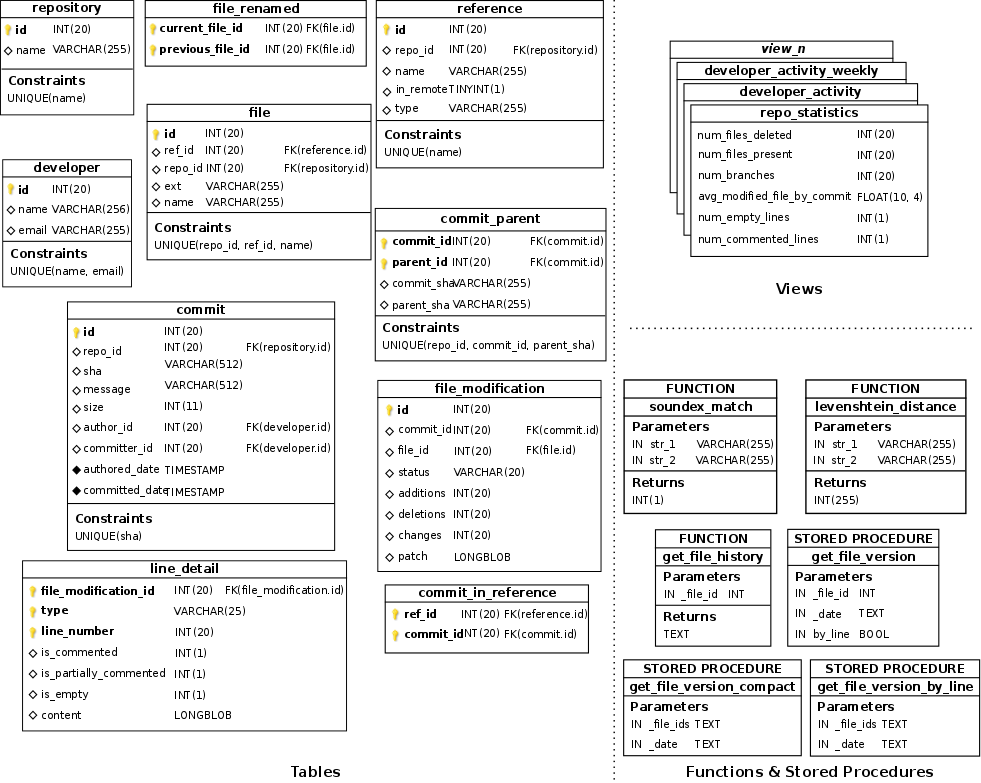
Fig. 2 – Database schema for Git.
Integration with other development tools
The schema presented in Fig. 2 can be integrated with other development-related data coming from tools that rely on a database infrastructure. Examples of such tools are most of issue tracking systems (e.g., BugZilla, Trac, Mantis) plus tools like GHTorrent, a scalable and offline mirror of GitHub; Gerrie, a data and information crawler for Gerrit, and Bicho, a tool that is able to parse different issue tracking systems (e.g., Launchpad, Jira, Allura).
Any of such tools embeds at least one concept that deals with Commits, Files or Developers. By leveraging on such concepts we can connect their database schemas with our Git schema by matching file names and SHA identifiers for Commits and Files, and relying on identity matching algorithm for Developers.
As an example, we show in Fig. 3 how our Git schema can be integrated with GHTorrent and Gerrie databases. The integration with GHTorrent provides a broader view of a GitHub project by combining the collaboration data and the Git SCM data, which GHTorrent does not cover at the moment. On the other hand, Gerrie integration allows extending the analysis of code-reviews with fine-grained information from the Git SCM data.
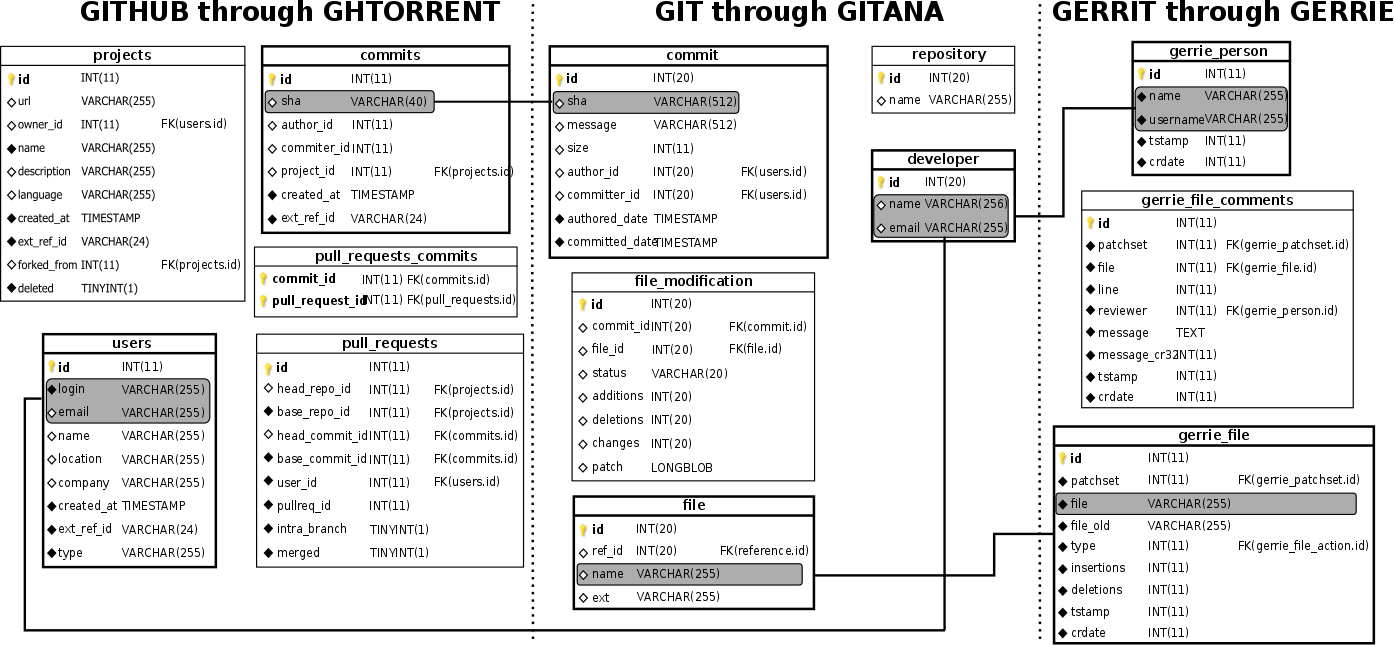
Fig. 3 – Integration scenario.
Advanced query functionalities on Git data
Given the database representation of the SCM system, we can leverage on the plethora of tools and techniques existing in the database realm to perform advanced queries on the data. In the example below we show how to count the modifications (i.e., additions, deletions and changes) made by each developer in the repository. As can be seen, instead of using a combination of Git and Shell commands, with Gitana, pure SQL syntax suffices to get the information.

Ex. 1 – Comparing Command line and SQL
Additionally, our approach also includes some calculated information not directly available when using the Git command line. This can help developers to uncover valuable information from the repository. For instance, the derived concept LineDetail and its corresponding database table line_detail may help to discover who are the developers that comment the most the source code. The example below shows a SQL query that calculates the number of files including comments per developer.

Ex. 2 – Files commented per developer
Beyond pure SQL queries, we can also apply on our Git schema ETL (Extract, Transform and Load) and OLAP (On-line Analytical Processing) technologies to perform multidimensional analysis for Git. Examples of possible analysis could be the evolution of the number of commits and files per unit of time (e.g., week, month, quarter) as well as the contribution activity of developers over time.