
I got a complaint about the translation of many-to-many UML associations to SQL tables in my UMLtoSQL online service .
More specifically, the complaint was that in the translation of this UML class diagram: 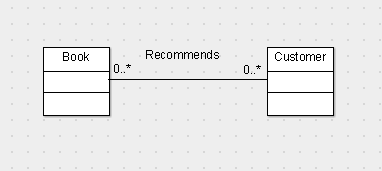
the Recommends association was implemented as an independent table with an autoincrement id field as the PK in it. This is the excerpt of the translation corresponding to this association:
-- Table for storing the data of Recommends
CREATE TABLE Recommends_rt(
id INTEGER(5) NOT NULL AUTO_INCREMENT,
-- Attribute referencing the customer
customer INTEGER(5) NOT NULL ,
-- Attribute referencing the book
book INTEGER(5) NOT NULL ,
CONSTRAINT pk_Recommends PRIMARY KEY (id),
CONSTRAINT u_Recommends1 UNIQUE (customer,book)
);
ALTER TABLE Recommends_rt
ADD CONSTRAINT fk_RecommendsToCustomer_customer FOREIGN KEY(customer)
REFERENCES Customer_rt(id)
ON DELETE restrict
ON UPDATE cascade;
ALTER TABLE Recommends_rt
ADD CONSTRAINT fk_RecommendsToBook_book FOREIGN KEY(book)
REFERENCES Book_rt(id)
ON DELETE restrict
ON UPDATE cascade;
This is a fully conscious decision. I know that the “traditional” way of implementing M:N associations is with a composite PK consisting in the union of the PKs of each participant class (in the example, customer+book would be the PK). However, I think the strategy I implemented in my service is better for two reasons:
- It enforces the same data integrity constraints: according to the semantics of associations in conceptual modeling languages like ER or UML (well, in fact UML 2.0 has the property isUnique that can be used to specify a different behaviour but IMHO this is not useful for data modeling), a customer cannot recommend twice the same book. This constraint is enforced by the Database Management System (DBMS) when <customer,book> is the PK. However this constraint is also enforced in my solution since the generator adds a unique constraint in the table that has the same effect
- It is a more pragmatic solution (in fact, I decided to adop this solution after discussing with several colleagues working as SE in different companies). The main problem with composite keys are that: 1- you need to propagate them to other tables (e.g. if Recommends was an association class and we would allows external users to comment on the recommendation, then the Comment table would need a composite FK to recommends to relate both concepts) and this is cascading effect (imagine the length of a PK if a many-to-many association class participates in another many-to-many association), 2 – implementing the GUI for the application gets more complex since we always need to take into account the possibility of having tables with composite PKs
What do you think? What strategy do you use for this? In general, do you prefer to be a pragmatic or a purist?
Btw, the complaint continued by saying “you’re clearly pandering TO the RoR/Django crowd who have forgone good design IN the NAME OF make their ORM tools easier TO WRITE” . RoR/Django fans, feel free to react!! (obviously I disagree with the comment: to me the design quality is better because we keep the semantics and offer a simpler solution)
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


I thought I’d respond publicly here: the excuses you’ve given here (I certainly wouldn’t call them reasons) for avoiding composite keys are both born out of laziness. It’s the same as arguing that you should avoid giving methods/functions descriptive names in your code because it’s less effort to type “doProc” than it is to type “requestCreditCardAuthorisation”.
Having a composite primary key accurately represents the true nature of the world: when a weak entity type exists that is because it can not logically exist without the entity it depends on.
Just because it’s more work, or more typing, or more complex, is not a reason to change a design technique. The design of a database should not be affected by considerations around implementation of the application that will use it for persistence: only the functional needs of the application should be considered when designing the database.
This goes for things like form builders which automatically read a database and output HTML for easy submission/saving of information. It encourages people to poison their design techniques by providing incentives to couple the design of the interface to the design of their database.
The design of database, API and UI should be separate activities.
Now, that being said I’m certainly not opposed to changes in design technique, but I’ve just never heard anyone give an argument opposing composite keys that doesn’t just involve saying “oh well it’s less work to do it this way”.
Sincerely,
Iain Dooley
I think it depends.
If we are talking about an ordinary association, there shouldn’t be a need FOR anyone TO refer TO instances OF the association (IN UML, “links”), so it does NOT need an IDENTITY/PK. If you want TO enforce uniqueness, a UNIQUE CONSTRAINT involving the two columns (AS you have) makes sense AND should be ALL it IS required.
If we ARE talking about an association class (usually WITH additional attributes), THEN it makes sense FOR it TO have an IDENTITY OF its own. I don’t think it should be a composite primary key (which don’t make sense IN ORM), but rather a surrogate KEY.
The example you give seems TO fit the FIRST CASE. If instead it somehow included extra information, such AS a rating AND/OR a review comment, it feels LIKE recommendations ARE just entities, AND would fit the SECOND CASE.
Just my R$ 0,02…
Rafael
http://alphasimple.com
IMHO it’s much better TO spend MORE effort IN other design aspects than composite PKs…
“Laziness” isn’t the right word, i would call it efficiency!
I can’t see the added VALUE OF USING meaningful PKs AT ALL. Mostly I prefer UUIDs OR numbers AS PK AND I’m quite happy with this solution. Simpler IS better 🙂
Greetings, ben
AS you’ve said: “…if Recommends was an association class…”. But it isn’t, RIGHT? If it were AND got referenced by other classes, than yes, Recommends would GET its own single COLUMN PK LIKE ANY other class/entity IN you model.
This IS opposite TO your assumption that we need TO propagate composite PKs. They don’t need to be cascaded because they represent simple associations (relashionships) and simple associations usually don’t GET referenced. ONLY classes GET referenced AND that IS why association classes do exist.
@charlesabreu
Let´s say that I prefer to assume that all M:N associations are potential association classes and adopt a more homogeneous solution. If the semantics are preserved and the solution is simpler (at least in my opinion), then I go for it!
In xtUML, you would make Recommends an associative class with the identifier composed of the referential identifiers from Book and Customer. If you don’t do this, you’d have to support multivalued and null value attributes.
The ID attribute doesn’t add any value, as it’s extra data that gives no correlation to anything in the model outside of the number of recommends in the whole system.
The propagation argument is specious on two points: it’s a logical-physical confusion and the idea of a relationship to recommends means recommends is a class in the model, which needs to have a formalized relationship to Book and Customer that shouldn’t be hodden.
Hi Jordi:
I agree with your implementation. Main reason is that I am against meaningful PKs, and I’d rather use always “autoincrement” or similar PKs, and thus, only one field as PK.
This will avoid plenty of forthcoming problems in migrations, refactoring, changes in business requirements, multiple column PK propagation, etc…
Rgds