
REpresentational State Transfer (REST) has become the dominant approach to design Web APIs nowadays, resulting in thousands of public REST Web APIs offering access to a variety of data sources (e.g., open-data initiatives) or advanced functionalities (e.g., geolocation services).
Unfortunately, most of these APIs do not come with any specification that developers (and machines) can rely on to automatically understand and integrate them. Instead, most of the time we have to rely on reading its ad-hoc documentation web pages, despite the existence of languages to model Web APIs like Swagger or, more recently, OpenAPI that developers could use to formally describe their APIs.
There are several languages to describe Web APIs. Unfortunately, they are hardly used Click To TweetIn this post, we present an example-driven discovery process that generates model-based OpenAPI specifications for REST Web APIs by using API call examples. A tool implementing our approach and a community-driven repository for the discovered APIs are also presented.
This work has been presented at ECMFA’17. Feel free to download the paper on pdf , check the slides below or keep reading to discover the main parts of the proposal.
Contents
1. Modeling Web APIs
Web APIs are becoming the backbone of Web, cloud, mobile applications and even many open data initiatives. For example, as of February 2017, ProgrammableWeb lists more than 16,997 public APIs. REST is the predominant architectural style for building such Web APIs, which proposes to manipulate Web resources using a uniform set of stateless operations and relying only on simple URIs and HTTP verbs.
How many public APIs are out there? @Programmableweb lists over 17000! Click To TweetDespite their popularity, REST Web APIs do not typically come with any precise specification of the functionality or data they offer. Instead, REST “specifications” are typically simple informal textual descriptions [11] (i.e., documentation pages), which hampers their integration in third-party tools and services. Indeed, developers need to read documentation pages, manually write code to assemble the resource URIs and encode/decode the exchanged resource representations. This manual process is time-consuming and error-prone and affects not only the adoption of APIs but also its discovery so many web applications are missing good opportunities to extend their functionality with already available APIs.
Actually, languages to formalize APIs exist, but they are barely used in practice. Web Application Description Language (WADL) [6], a specification language for REST Web APIs was the first one to be proposed. However, it was deemed too tedious to use and alternatives like Swagger, API Blueprint or RAML quickly surfaced. Aiming at standardizing the way to specify REST Web APIs, several vendors (e.g., Google, IBM, SmartBear, or 3Scale) have recently announced the OpenAPI Initiative, a vendor neutral, portable and open specification for providing metadata (in JSON and YAML) for REST Web APIs.
This paper aims to improve this situation by helping both API builders and API users to interact with (and discover) each other by proposing an approach to automatically infer OpenAPI-compliant specifications for REST Web APIs, and, optionally, store them in a community-oriented directory. From the user’s point of view, this facilitates the discovery and integration of existing APIs, favoring software reuse. For instance, API specifications can be used to generate SDKs for different frameworks (e.g., using APIMATIC). From the API builder’s point of view, this helps increase the exposure of the APIs without the need to learn and fully write the API specifications or alter the API code, thus allowing fast-prototyping of API specifications and leveraging on several existing toolsets featuring API documentation generation (e.g., using Swagger UI) or API monitoring and testing (e.g., using Runscope).
Our approach is an example-driven approach, meaning that the OpenAPI specification is derived from a set of examples showing its usage. The use of examples is a well-known technique in several areas such as Software Engineering [8, 10] and Automatic Programming [5]. In our context, the examples are REST Web API calls expressed in terms of API requests and responses.
We follow a metamodeling approach [1] and create an intermediate model-based representation of the OpenAPI specifications before generating the final OpenAPI JSON Schema definition for two main reasons:
- to leverage the plethora of modeling tools to generate, transform, analyze and validate our discovered specifications (as existing JSON schema tools are limited and may produce contradictory results [12]); and
- to enable the integration of APIs into model-driven development processes (for code- generation, reverse engineering,..). For instance, we envision designers being able to include API calls in the definition of web-based applications using the Interaction Flow Modeling Language (IFML) [2].
The remainder of this paper is structured as follows. Section 2 show the running example used along the paper. Section 3 presents the overall approach and then Sections 4, 5 and 6 describe the OpenAPI metamodel, the discovery process, and the generation process, respectively. Section 7 describes the validation process and limitations of the approach. Section 8 presents the related work. Section 9 describes the tool support, and finally, Section 10 concludes the paper.
2. Running Example
This section introduces the running example used along the paper together with the main elements of a REST Web API. The example is based on the Petstore API, a REST Web API for a pet store management system, released by the OpenAPI community as a reference. This API allows users to manage pets (e.g., add/find/delete pets), orders (e.g., place/delete orders), and users (e.g., create/delete users).
Figure 1 shows an excerpt of this API specification, an API access request and a possible response document for that call request. Figure 1a shows the request to retrieve the pet with the id 123 while Figure 1b shows
the returned response with that pet information. A request includes a method (e.g., GET), a URL and optionally a message body. The URL, in turn, includes: (i) the transfer protocol, (ii) the host, (iii) the base path, (iv) the relative path and (v) the query (indicated by the first question mark “?”, empty for this example). The relative path and the query are optional. A response includes a status code (e.g., 200) and optionally a JSON response message.
Figure 1c shows an excerpt of the OpenAPI-compliant specification for this example call in JSON format. This document includes fields to specify properties such as the host, the base path, the available paths (i.e., the field paths), the supported operations for each path (e.g., the field get), and the data types produced and consumed by the API (i.e., the field definitions). The specification indicates that the GET operation of the path /pet/{petId} allows retrieving a pet by his ID.

Fig. 1. API call example of the Petsore API: (a) the request, (b) the response, and (c) an excerpt of the corresponding OpenAPI specification.
3. Approach
We define a two-step process to discover OpenAPI-compliant specifications from a set of REST Web API call examples. Figure 2 shows an overview of our approach.
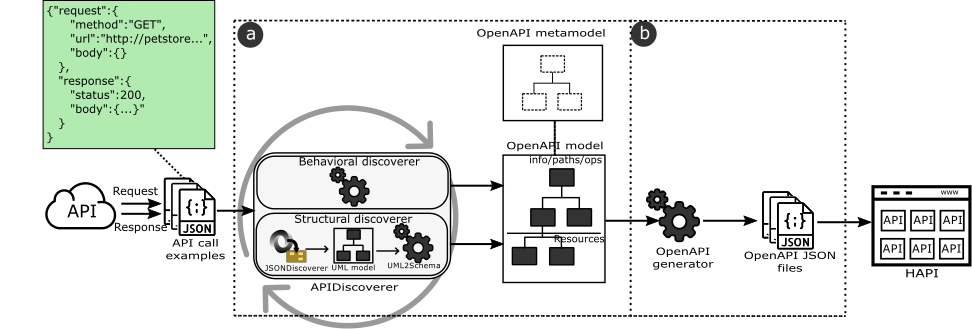
Overview of our API Specificatio Discovery approach
The process takes as input a set of API call examples. For the sake of simplicity, we assume examples are provided beforehand and later in Section 9 we describe how we devised a solution to provide them both manually and relying on other sources. These examples are used to build an OpenAPI model (see Figure 2a) in the first step of the process. Each example is analyzed with two discoverers, namely: (1) behavioral and (2) structural targeting the corresponding elements of the API definition. The output of these discoverers is merged and added incrementally to an OpenAPI model, conforming to the OpenAPI metamodel presented in the next section. The second step transforms these OpenAPI models to valid OpenAPI JSON documents (see Figure 2b).
To represent the API call examples themselves, we rely on a JSON-based representation of the request/response details. Both, the request sent to the server and the received response message, are represented as JSON objects (i.e., request and response fields in left upper box of Figure 2). The request object includes fields to set the method, the URL and the JSON message body; while the response object includes fields for the status code and the JSON response message. This JSON format helps to simplify the complexity of directly using raw HTTP requests and responses (which would require to perform HTTP traffic analysis) and facilitate the provision of examples by end-users. As discussed later, we provide also tool support to provide API call examples and even to (semi)automatically derive them from other sources, like existing documentation.
As a final step, the resulting OpenAPI-compliant specifications may optionally be added to HAPI, our community-driven hub for REST Web APIs, where developers can search and query them. In the following sections, we describe our OpenAPI metamodel, the discoverers, and the OpenAPI generator. The example providers, APIs importers, and HAPI will be explained in Section 9.
4. The Open API Metamodel
This section presents the OpenAPI metamodel to specify REST Web APIs. In a nutshell, a metamodel describes the set of valid models for a language, specifying how the different elements of the modeling language can be used and combined [1].
This model-based approach to define and store internally OpenAPIs facilitates the integration of our approach with model-based development methods and facilitates the manipulation of such OpenAPI specifications before the final generation of the corresponding JSON documents. Such features are not provided by the JSON Schema definition of OpenAPI11, which is limited to be used to validate documents against the original specification; or existing implementations (e.g., the Java model for OpenAPI), which generally consist of a set of POJOs to serve as parsing facilities.
The metamodel is derived from the concepts and properties described in the OpenAPI specification document. Next we explain the main parts of this metamodel, namely: (1) behavioral elements, (2) structural elements, and (3) serialization/deserialization elements. The metamodel also includes support for metadata (e.g., description or version) and security aspects. The complete metamodel, comprised of 29 different metaclasses, is available in our repository.
4.1. Behavioral Elements in the OpenAPI Metamodel
Figure 3 shows the behavioral elements of the OpenAPI metamodel. A REST Web API is represented by the API element, which is the root element of our metamodel. This element includes attributes to specify the version of the API (swagger attribute), the host serving the API, the base path of the API, the supported transfer protocols of the API (schemes attribute) and the list of MIME types the API can consume/produce. It also includes references to the available paths, the data types used by the operations (definitions reference) and the possible responses of the API calls.
The Path element contains a relative path to an individual endpoint and the op- erations for the HTTP methods (e.g., get and put references). The description of an operation (Operation element) includes an identifier operationId, the MIME types the operation can consume/produce, and the supported transfer protocols for the operation (schemes attribute). An operation includes also the possible responses returned from executing the operation (responses reference).
API, Path and Operation elements inherit from ParameterContext, which allow them to define parameters at API level (applicable for all API operations), path level (applicable for all the operations under this path) or operation level (applicable only for this operation).
The Response element defines the possible responses of an operation and includes the HTTP response code, a description, the list of headers sent with the response, and optionally an example of the response message. Response and Parameters elements inherit from SchemaContext thus allowing them to add the definition of the response structure and the data type (schema reference) used for the parameter, respectively. Parameter and Schema elements will be explained in Section 4.2.
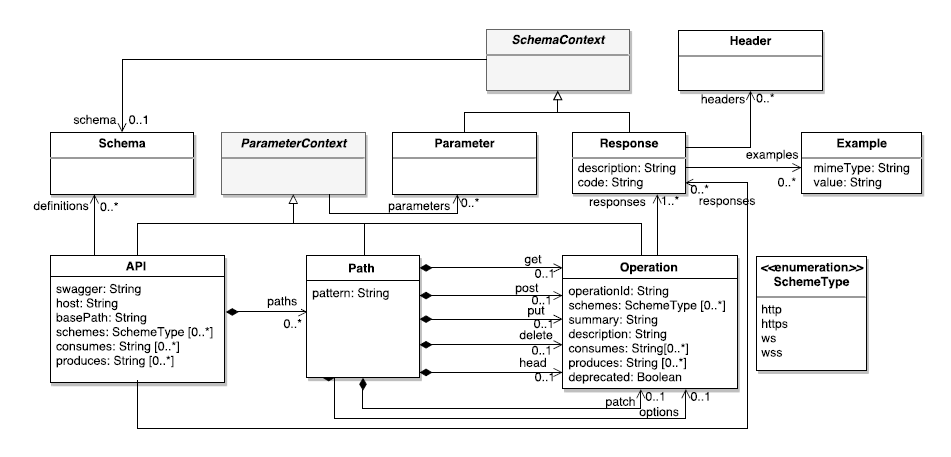
Fig. 3. Behavioral elements of the OpenAPI metamodel.
4.2. Structural Elements of the OpenAPI metamodel
Figure 4 describes the structural elements used in a REST Web API, namely: the Schema element, which describes the data types; the Parameter element, which defines an operation parameter; the ItemsDefiniton element, which describes the type of items in an array; and the Header element, which describes a header sent as part of a response. These elements use an adapted subset of the JSON Schema Specification defined in the super class JSONSchemaSubset.
A parameter includes a name, and two flags to specify whether either the parameter is required or empty.The location of the parameter is defined by the location attribute. The possible locations are: (i) path, when it is part of the URL (e.g., petId in /pet/petId); (ii) query, when it is appended to the URL (e.g., status in /pet/findByStatus?status=”sold”); (iii) header, for custom headers; (iv) body, when it is in the request payload; and (v) formData, for specific payloads.
Parameter and Header elements inherit from ArrayContext to allow them to specify the collection format and the items definition for attributes of type array. Additionally, the Parameter element inherits from the SchemaContext to define the data structure when the attribute location is of type body (Schema reference).
The Schema element defines the data types that can be consumed and produced by operations. It includes a name, a title, and an example. Inheritance and polymorphism are specified by using the allOf reference and the discriminator attribute, respectively. Furthermore, when the schema is of type array, the items reference makes possible to specify the values of the array.
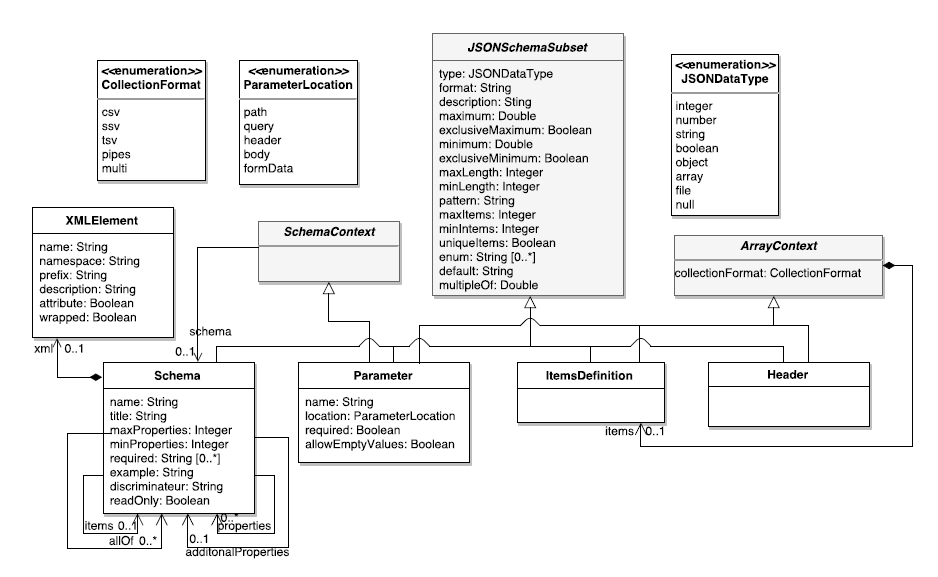
Fig. 4. Structural elements of the OpenAPI metamodel
5. The API Discovery process
The discovery process takes as input a set of API call examples and incrementally generates an OpenAPI model conforming to our OpenAPI metamodel using two types of discoverers: (1) behavioral and (2) structural. The former generates the behavioral elements of the model (e.g., paths, operations) while the latter focuses on the data types elements. In the following, we explain the steps followed by these two discoverers.
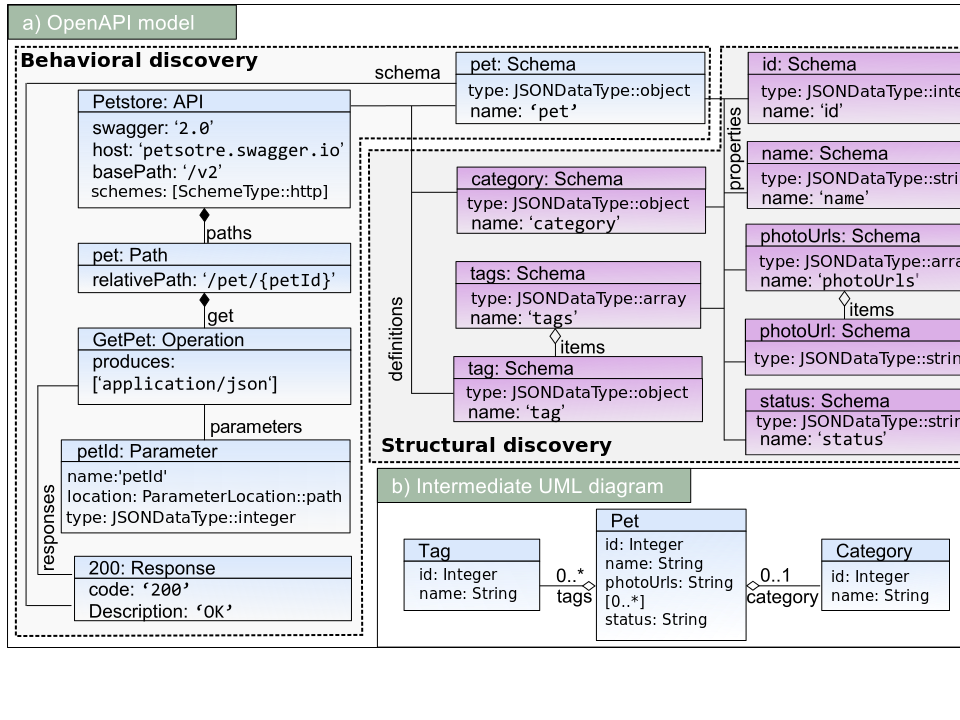
Fig. 6. The discovered OpenAPI model from the Petstore API example
5.1. Behavioral API Discoverer
This discoverer analyzes the different elements of the API example calls (i.e., HTTP method, URL, request body, response status, response body) to discover the behavioral elements of the metamodel.
Table 1 shows the applied steps. Target elements column displays the created/updated elements in the OpenAPI model while Source column shows the elements of an API call example triggering those changes (see Figures 1a and 1b). The Action column describes the applied action at each step and the Notes column displays notes for special cases. These steps are applied in order and repeated for each API call example. A new element is created only if such element does not exist already in the OpenAPI model. Otherwise, the element is retrieved and enriched with the new discovered information. Note that the dis- covery of the schema structure will be assessed by the structural discoverer (see step 6).
Figure 6a shows the generated OpenAPI model for the API call example shown in Figure 1. The discovery process is applied as follows.
- Step 1 creates an API element and set its attributes (i.e., schemes to SchemeType::http, host to petstore.swagger.io, and basePath to /v2).
- Step 2 creates a Path element, sets its only attribute realtivePath to /pet/{petId} (the string ’123’ was detected as identifier), and adds it to the paths references of the API element.
- Step 3 creates an Operation element, sets its produces attribute to application/json, and adds it to the get reference of the previously created Path element.
- Step 4 creates a Parameter element, sets its attributes (i.e., name to petId, location to path, and type to JSONDataType::integer), and adds it to the parameters reference of the previously created Operation element.
- Step 5 creates a Response element, sets its attributes (i.e., code to 200 and description to OK), and adds it to the response reference of the previously created Operation element.
- Finally step 6 creates a Schema element, sets only its name to Pet, and adds it to the definitions reference of the API element. The rest of the Schema element will be completed by the structural discoverer.
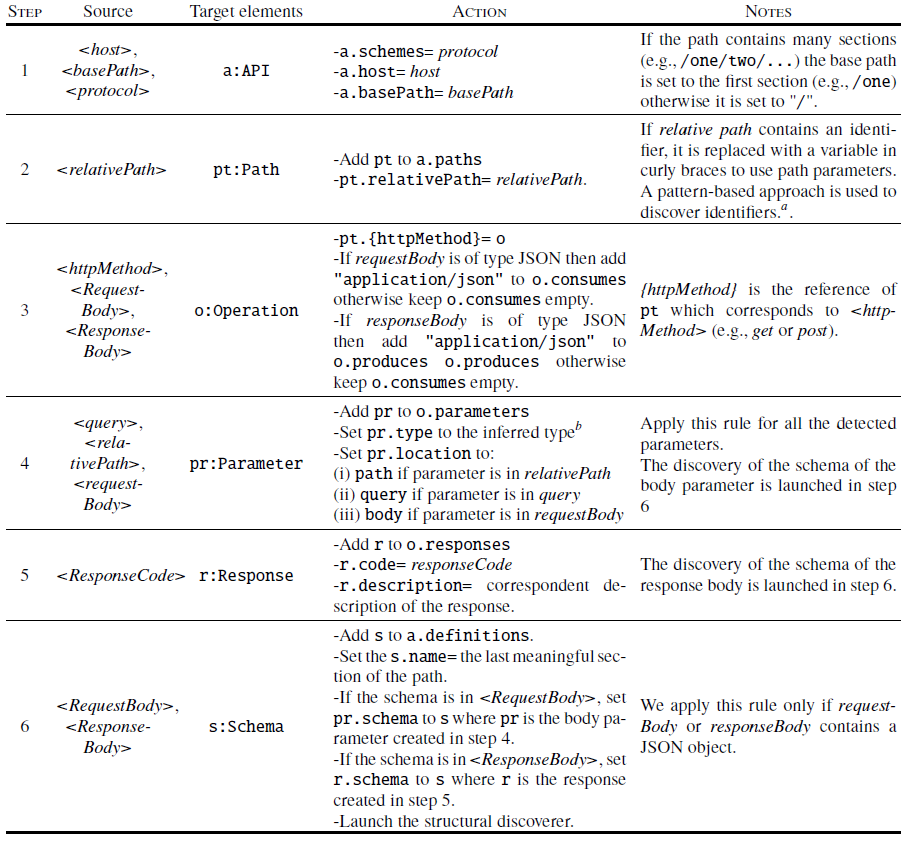
Table 1. Steps of the behavioral discoverer applied for each REST Web API call example.
5.2. Structural Discoverer
This discoverer instantiates the part of the OpenAPI model related to data types and schema information. This process is started after the behavioral discovery when the API call includes a JSON object either in the request body or the response body that will be used to enrich the definition of the discovered Schema elements.
We devised a two-step process where we first obtain an intermediate UML-based representation from the JSON objects and then we perform a model-to-model trans- formation to instantiate the actual schema elements of the OpenAPI metamodel. This intermediate step allows us to benefit from JSONDiscoverer [4], which is the tool used to build a UML class diagram, and to use this UML-based representation to bridge easily to other model-based tools if needed. Then, classes, attributes, and associations of the UML class model are transformed to Schema elements.
Table 2 shows the transformation rules applied to transform UML models to Schema elements. Source column shows the source elements in a UML model while Target: create and Target: update columns display the created/updated elements in the OpenAPI model. The Attribute initialization column describes the transformation rules.
Note that elements are updated/enriched when they already exist in the OpenAPI model. This particularly happens when different examples represent the same schema elements, as JSON schema allows having optional parts in the examples.
Figure 6b shows the UML class model discovered by JSONDiscoverer for the API response shown in Figure 1b. This class model is transformed to actual schema elements applying the discovery process as follows. Tag, Pet, and Category classes are trans- formed to schema elements of type Object. Single-valued attributes (e.g., name, id) are transformed to Schema elements where type is set to the corresponding primitive type. The photoUrls multivalued attribute and tags multivalued association are transformed to Schema elements of type array having as items a Schema element of type String and Tag element, respectively. Finally, attributes and associations are added to the properties reference of the corresponding Schema element.

Table 2. Transformation rules from UML to Schema
6. The OpenAPI Generation Process
The generator creates a OpenAPI-compliant JSON file from an OpenAPI model by means of a model-to-text transformation. The root object of the JSON file is the API model element, then each model element is transformed to a pair of name/value items where the type for the value is (1) a string for primitive attributes, (2) a JSON array for multivalued element or (3) a JSON object for references. Serialization/deserialization model elements are used to resolve references. As said in Section 4, elements such as Schema, Parameter, and Response can be declared in different locations and reused by other elements. While the declaringContext reference is used to define where to declare the object, the ref attribute (inherited form JSONPointer class) is used to reference this object from another element. By default the discovery process sets the declaring context to the containing class of the element (e.g., parameters in operations).
The following listing shows the generated JSON file for the OpenAPI model shown in Figure 6a. Note that the declaring context of the Pet schema element is set to API, which resulted in listing the Pet element in the definitions object. Consequently, the attribute ref is set to #/definitions/Pet and will be used to reference Pet from any another element (as in the response object).
{ "swagger ":"2.0",
"info":{ },
"host":"petstore.swagger.io","basePath ":"/v2",
"tags":[ "pet" ],"Schemes":[ "http" ],
"paths":{
"/pet/{petId}":{
"get":{
"produces ":[" application/json"],
"parameters ":[{"name":"petId","in":"path","type":"integer"}],
"responses":{
"200":{
"description":"OK",
"schema":{"$ref":"#/ definitions/Pet"
}}}}
}},
"definitions":{
"Pet":{
"type":"object",
"properties":{
"id":{"type":"integer"},
"category ":{"$ref":"#/ definitions/Category"},
"name":{"type":"string"},
"photoUrls ":{"type":"array","items":{"type":"string"}},
"tags":{"type":"array","items":{"$ref":"#/ definitions/Tag"}},
"Status":{"type":"string"}},
}}} |
9. Tool Support
Figure 8 shows the underlying architecture of our discovery tool. Our tool includes a front-end, which allows users to collect and run API call examples (see APIDiscoverer UI) to trigger the launch of the core API discoverer process; and a back-end, which all the components to parse the calls and responses, generate the intermediate models, etc. Our tool has been implemented in Java and is available as an Open Source application.
More specifically, APIDiscoverer is a Java Web application that can be deployed in any Servlet container (e.g., Apache Tomcat). The application relies on JavaServer Faces (JSF), a server-side technology for developing Web applications, and Primefaces, a UI framework for JSF applications. Figure 9 shows a screenshot of the APIDiscoverer interface.
The center panel of APIDiscoverer contains a form to provide API call examples either by sending requests or using our JSON-based representation format. The former requires providing the request and obtaining a response from the API. As result, a JSON-based API call example is shown on the right. The latter only requires providing the JSON-based API call example. API call examples are then used by APIDiscoverer to obtain/enrich the corresponding OpenAPI model.
The examples history is shown on the left panel and an intermediate OpenAPI model is shown on the right panel. The OpenAPI model is updated after each example with the new information discovered by the last request. Finally, a button in the top panel allows the user to download the final OpenAPI description file.
The main components of the back-end are (1) a REST agent and (2) the core APIDiscoverer. The REST agent relies on unirest, a REST library to send requests to APIs to build and collect API call examples. The APIDiscoverer relies on a plethora of web/modeling technologies, namely, (1) the Eclipse Modeling Framework (EMF) as a modeling framework to implement the OpenAPI metamodel, (2) the Eclipse OCL to validate models and (3) the JSONDiscoverer to discover models from JSON examples. Additionally, we have implemented the required components (1) to discover OpenAPI elements from API call examples (see Ex2OpenAPI), (2) to transform UML models to a list of schema elements using model-to-model transformations (see UML2Schema), and (3) to generate an OpenAPI description file from an OpenAPI model by using model-to-text transformations (see JSONGen).
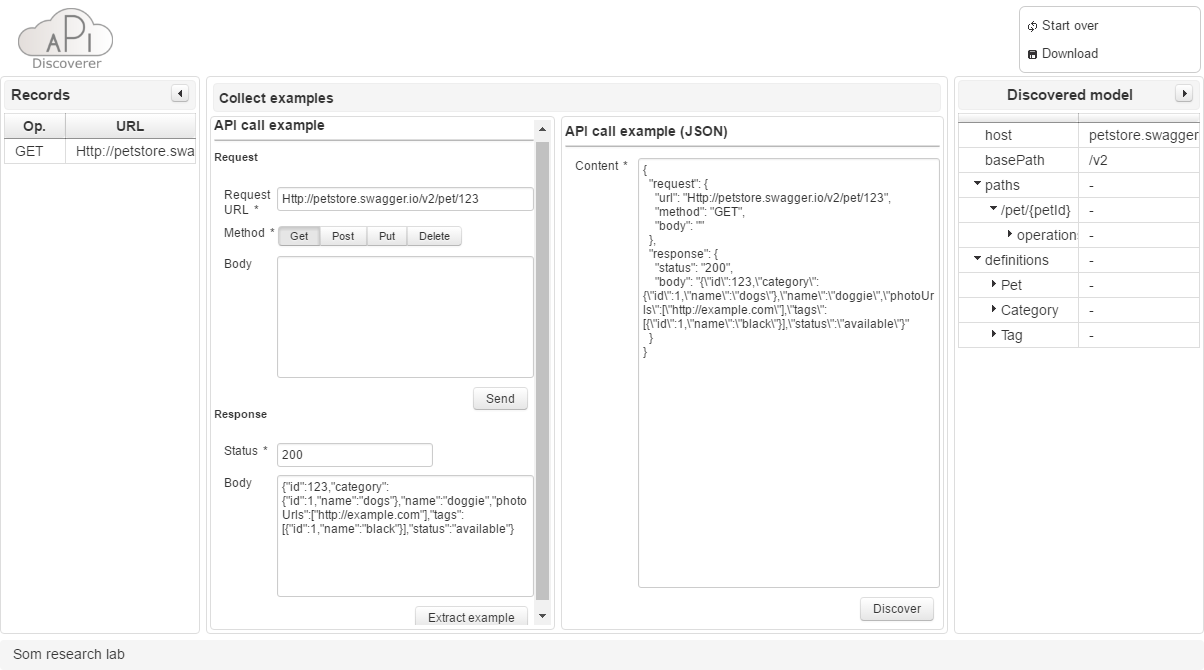
Screenshot of the tool interface
10. Conclusion
We have presented an example-driven approach to generate OpenAPI specifications for REST Web APIs. These specifications are stored in a shared directory where anybody can comment and improve them. We believe our process and repository is a significant step forward towards API reuse, helping developers to find and integrate the APIs they need to provide their software services. The discovery tool is available online as an open source application.
As further work, we are interested in extending the OpenAPI metamodel to add Quality of Service (QoS) and business plan aspects, which play a fundamental role in the API economy, as well as ontology and vocabulary concepts (e.g., FOAF ontology) to describe the APIs not only on a syntactical level but also on a semantic level. We are also interested in discovering security aspects, non-functional properties, and the semantic definitions of the APIs under scrutiny, and supporting non-JSON data (e.g. XML). The discovery process per se could also be improved by extending our approach to support the generation of call examples based on the textual analysis of the API documentation websites, this way speeding up the process of interacting with the API to infer its specification. Finally, we plan to systematically apply our process to a large number of APIs (linked from other directories or repositories) in order to expand HAPI.
References
1. Brambilla, M., Cabot, J., Wimmer, M.: Model-Driven Software Engineering in Practice.
Morgan & Claypool Publishers (2012)
2. Brambilla, M., Fraternali, P., et al.: The Interaction Flow Modeling Language (IFML). Tech. rep., Object Management Group (OMG) (2014)
3. Cabot, J., Gogolla, M.: Object Constraint Language (OCL): a Definitive Guide. In: Formal methods for model-driven engineering, pp. 58–90 (2012)
4. Cánovas Izquierdo, J.L., Cabot, J.: JSONDiscoverer: Visualizing the Schema Lurking Behind
JSON Documents. Knowledge-Based System 103, 52–55 (2016)
5. Frankle, J., Osera, P.M., Walker, D., Zdancewic, S.: Example-Directed Synthesis: A Type- Theoretic Interpretation. In: ACM Symp. on Principles of Programming Languages. pp.
802–815 (2016)
6. Hadley, M.J.: Web Application Description Language (WADL). Tech. rep. (2006)
7. Klettke, M., Störl, U., Scherzinger, S., Regensburg, O.: Schema Extraction and Structural Outlier Detection for JSON-based NoSQL Data Stores. In: Conf. on Database Systems for Business, Technology, and Web. pp. 425–444 (2015)
8. López-Fernández, J.J., Cuadrado, J.S., Guerra, E., de Lara, J.: Example-Driven Meta-Model
Development. Software & Systems Modeling 14(4), 1323–1347 (2015)
9. Motahari-Nezhad, H.R., Saint-Paul, R., Casati, F., Benatallah, B.: Event Correlation for
Process Discovery from Web Service Interaction Logs. Inter. J. on Very Large Data Bases
20(3), 417–444 (2011)
10. Nierstrasz, O., Kobel, M., Girba, T., Lanza, M.: Example-Driven Reconstruction of Software
Models. In: Euro. Conf. on Software Maintenance and Reengineering. pp. 275–286 (2007)
11. Pautasso, C., Zimmermann, O., Leymann, F.: RESTful Web Services vs. “Big”’ Web Services.
In: Inter. Conf. on World Wide Web. pp. 805–814 (2008)
12. Pezoa, F., Reutter, J.L., Suarez, F., Ugarte, M., Vrgoč, D.: Foundations of JSON Schema. In: Inter. Conf. on World Wide Web. pp. 263–273 (2016)
13. Quarteroni, S., Brambilla, M., Ceri, S.: A Bottom-up, Knowledge-Aware Approach to In- tegrating and Querying Web Data Services. ACM Transactions on the Web 7(4), 19–33 (2013)
14. Rodriguez Mier, P., Pedrinaci, C., Lama, M., Mucientes, M.: An Integrated Semantic Web
Service Discovery and Composition Framework. IEEE Transactions on Services Computing
9(4), 537–550 (2015)
15. Ruiz, D.S., Morales, S.F., Molina, J.G.: Inferring Versioned Schemas from NoSQL Databases and its Applications. In: Int. Conf. on Conceptual Modeling. pp. 467–480 (2015)
16. Schmidt, C., Parashar, M.: A Peer-to-Peer Approach to Web Service Discovery. In: Inter.
Conf. on World Wide Web. pp. 211–229 (2004)
17. Serrour, B., Gasparotto, D.P., Kheddouci, H., Benatallah, B.: Message Correlation and Busi- ness Protocol Discovery in Service Interaction Logs. In: Int. Conf. on Advanced Information Systems Engineering. pp. 405–419 (2008)
18. Sohan, S., Anslow, C., Maurer, F.: SpyREST: Automated RESTful API Documentation Using an HTTP Proxy Server (N). In: Int. Conf. on Automated Software Engineering. pp. 271–276 (2015)
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Recent Comments