
Guest post by Jokin García summarizing our work “DB Schema Evolution in Model-to-Text Transformations: An Adapter-based Approach” co-written by Jokin, Óscar Díaz (both from the Onekin group, (www.onekin.org, University of the Basque Country -UPV/EHU) and myself. This work have been accepted in the CAiSE 2014 conference . Enter Jokin.
Generally, in model-to-text (M2T) transformations there is an static part and a dynamic part. The dynamic part includes references to the input model of the transformation to extract information from the domain while the static part embodies this dynamic part with code excerpts targeting a specific platform. This code couples the platform and the M2T transformation. Therefore, an evolution in the platform can leave the transformation, and hence the generated code, outdated. This issue is exacerbated by the perpetual beta phenomenon of most platforms that change constantly forcing designers of code-generators to continuously adapt and rebuilt their transformations.
Our work studies this problem when using databases as a platform. This is a typical scenario in Web 2.0, where the applications are data-centered: for instance, think about Wikipedia, which is built upon Mediawiki database, that evolves regularly. In this context, we aim at keeping the consistency between the code generator and the Database schema of the target platform. A synchronization in this scenario involves two specificities to take into account:
- SQL scripts are dynamically generated once references to the input model are resolved.
- The dependency is external: Database schema and the transformation might belong to different organizations.
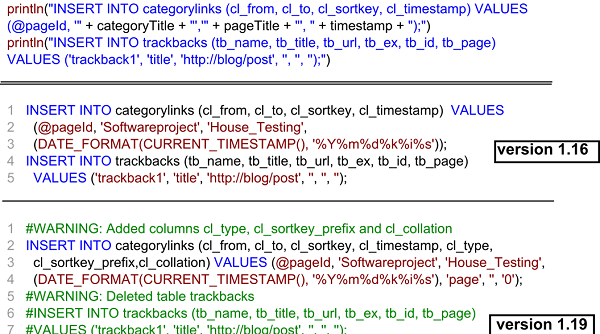
An snippet of code is shown below to illustrate the problem. In the upper part of the picture, we can see statements of a transformation. In the middle of the picture we can see the code generated by the transformation. These statements are affected by the evolution of the database schema, that adds three new columns in the “categorylinks” table, and deletes the table “trackbacks”. Our goal is to make sure the M2T generate an updated code, according to the new schema, as we can see at the bottom of the code snippet.
We propose as a solution applying the adapter pattern to model-to-text transformations. Data manipulation requests (i.e. insert, delete, update, select) are re-directed to the adapter during the transformation. The adapter outputs the code according to the latest schema release. In this way, the main source of instability (i.e. schema upgrades) is isolated in the adapter. As the adapter is domain agnostic, it can be re-used in any scenario, as long as the platform is a database.
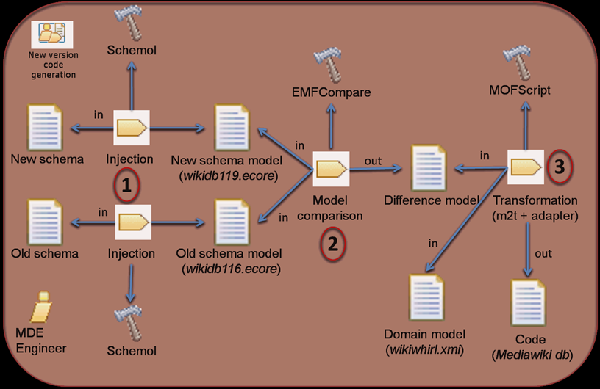
The picture above outlines different steps of our proposal. First, database schemas are injected; next, the schema difference is computed; and finally, this schema difference feeds the adapter, that iterates over all the changes to adapt the statements at runtime.
We consider that his approach can be applied to scenarios that fulfill the following requirements: low stability and high transformation coupling. We have implemented the database scenario (www.onekin.org/downloads/public/Batch_MofscriptAdaptation.rar), but we envisage the benefits of applying the approach to different scenarios (XML schemas, APIs, …), implementing the corresponding adapters, in order to provide M2T transforamation developers a set of adapters.
FNR Pearl Chair. Head of the Software Engineering RDI Unit at LIST. Affiliate Professor at University of Luxembourg. More about me.


Recent Comments